







话说在前头,爬爱回收对我这个菜鸟来说,收获很大(有点麻烦)...
具体代码可见文末我的GitHub链接...
- 首先明确一下目的,本来是想着爬取全部的价格数据,但是想想未免太多,所以先从手机-华为开始爬起(可以自行通用到其他回收品)
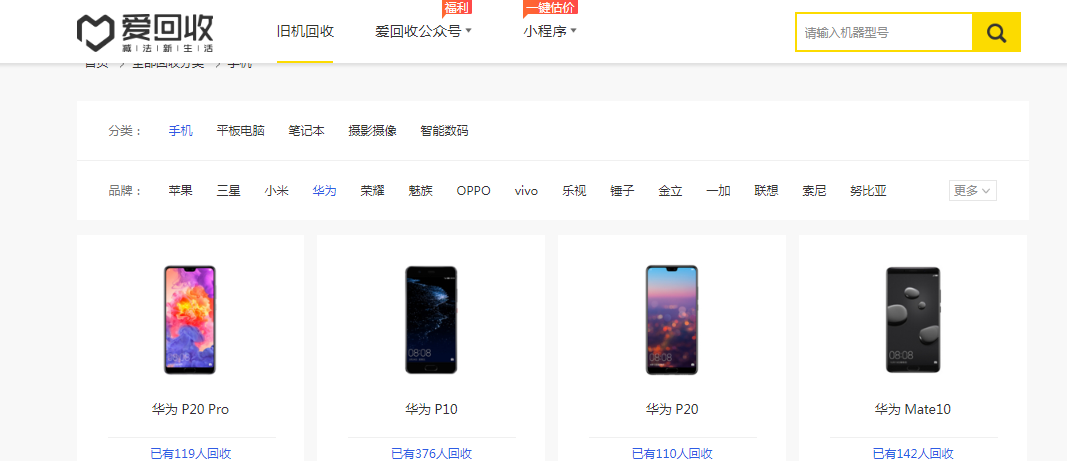
- 我们看看具体的信息在哪里可以得到
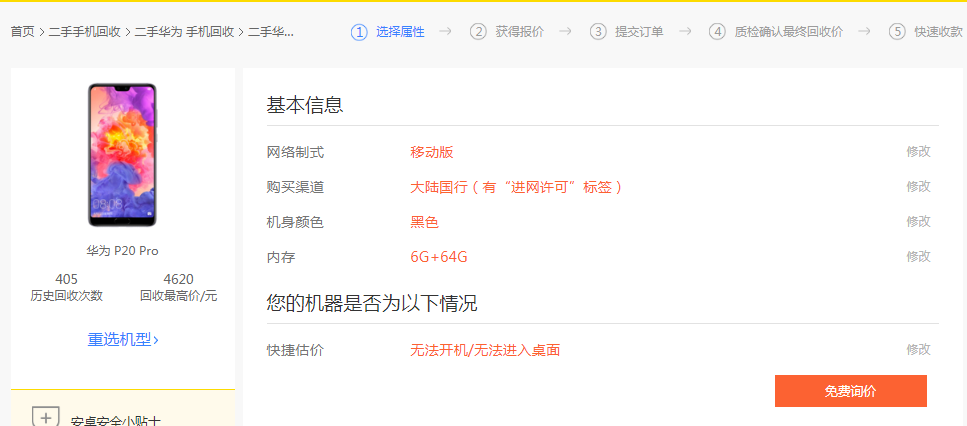
按F12打开Chrome的开发者工具,点击免费查询,通过异步加载得到的数据在这里
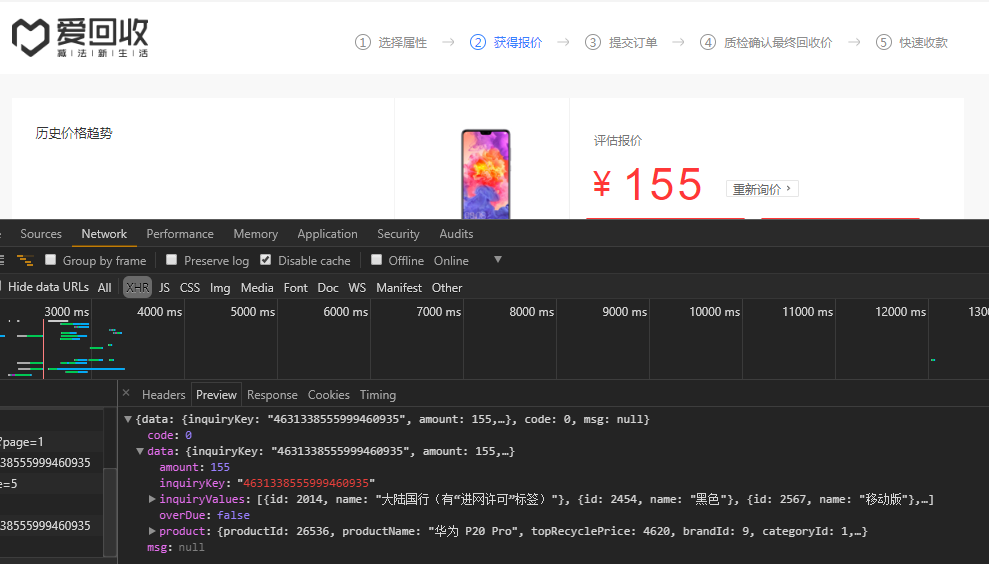

好嘛,到时候get一下这个url,拿到api的内容就行了,但是url中最后的数字串是变化的(如何获取在后面讲解)
- 既然决定要获取华为的回收信息,那么我们先把其第一页的各个手机型号的网页链接拿到

在这,我的思路是用beautifulsoup获取每个<a href=“...”>中的url存入列表中
然后遍历列表,逐个访问,但就算是这一页,需要爬取的数据也是比较多,所以暂时爬取的是第一个手机型号的回收信息,你要是觉着不多...可以都爬了
- 然后我们看看要爬取的这个型号的手机
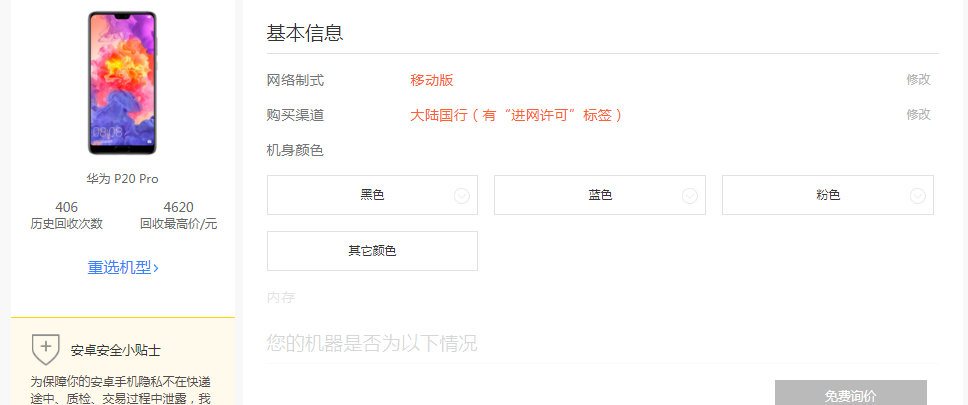
发现给了好多选项,这就意味着一个型号的手机有极其多种选择(包括某几个选择得到的手机价格是相同的)
我们再来仔细分析一下这个过程,选择标签->点击免费查询->服务器发回这个选择下的手机价格
我们发现免费查询对应的链接

注意这个链接,应该是通过向这个链接post某些数据,好我找了找post的...

这是什么...??应该是将post的数据加密了!emmm...
还有...

看到这里问题就来了,我既然要post数据,但是数据加密了我怎么才能看到
- 我的方法是抓包,利用强大的fiddler进行抓包
打开fiddler,在选择完选项后,点击免费查询,马上看fiddler中的抓到的信息

这不就是按钮对应的url吗,应该就是这条了
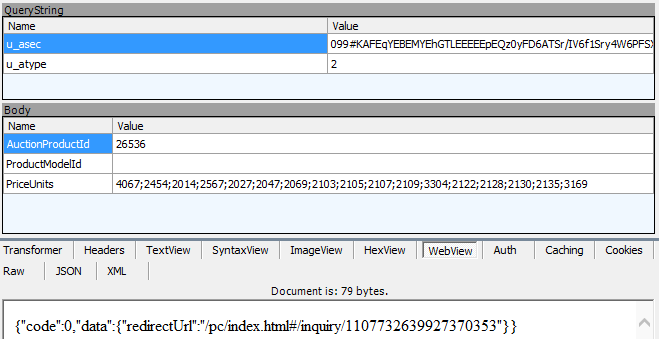
这里的body就是post上去的东西!原来长这样...
经过分析,auctionProductId是这个型号手机对应的url的后几位数,也就是之前获取的<a href...>中得到的数字部分
productModelId我找了找发现

其实在这里有pid跟mid,分别对应的就是前两行的内容
至于priceUnits这一系列的数字好像
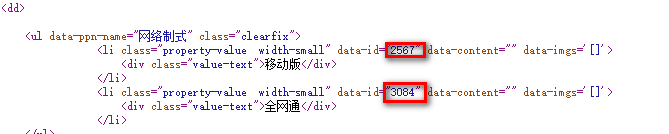
其实就是这几个选项的ID!
那么可以知道这个priceUnits就是选项ID的一个组合,所以前两个还简单,那么重点就是获取这个ID
- 所以我的方法是通过xpath获取这些id,然后通过for循环得到一个个选择组合(虽然麻烦了点),或者有更好的办法,欢迎提点
接下来就是post这些数据上去,得到redirectUrl
- 这里又会碰到一个问题,那就是请求太频繁的话会出现验证码,我试过用高匿代理,但是好像没什么用,绕不过去,而且爱回收的验证码是黏连验证码

一个字,恶心...
用简单的pytesseract或pytesser识别出来的简直看不了
经过反复找资料等一系列操作,决定还是用阿里云的图片验证码识别服务,花了我0.91元试验(尚可,就是1跟7难以区别,而且第三方不稳定,容易报错),当然也只能先接受了
- 通过判断post后返回信息中的code是否为0,区别是否出现验证码
若为0,直接发送get请求即可获取数据
若为其他,像3001这样的,拿到后面的验证码的url,下一步要做的就是拿到验证码图片,识别验证码,再把验证码中的数字添加到post的数据中
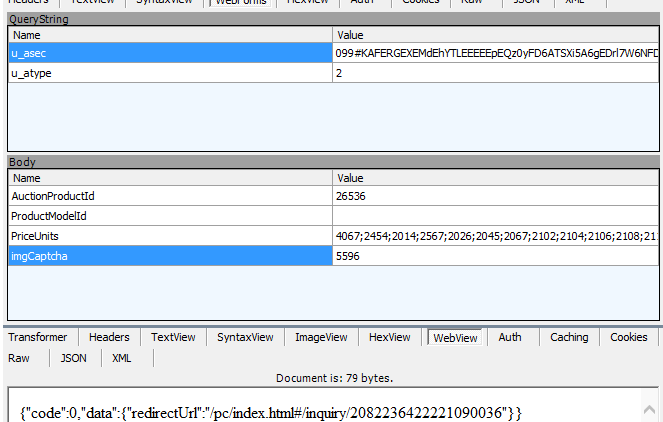
- 如何获取验证码
这里用的是selenium+phantomJS,一开始用selenium+chrome,发现一要获取验证码就会弹出一个Chrome窗口很是不舒服,后来了解到phantomJS这种无界面浏览器,好用就在这里(但是都说运行比较的慢?)
然后将二维码截图获取,降噪,二值化处理,最后调用阿里云的接口,就能识别啦!!
- 具体代码可以见我的GitHub链接,第一次写博文写的不够完善,以后会补充
参考过一篇博文:https://blog.csdn.net/weixin_42069950/article/details/80331478
我的GitHub:https://github.com/joelYing/aihuishou

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









