






1、Sklearn简介
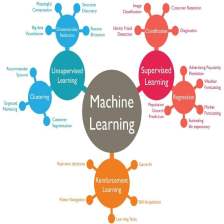
Scikit-learn(sklearn)是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression)、降维(Dimensionality Reduction)、分类(Classfication)、聚类(Clustering)等方法。当我们面临机器学习问题时,便可根据下图来选择相应的方法。Sklearn具有以下特点:
简单高效的数据挖掘和数据分析工具
让每个人能够在复杂环境中重复使用
建立NumPy、Scipy、MatPlotLib之上
易上手、丰富的API,文档完善,包括许多机器学习算法的实现

2、sklearn特征抽取的API
特征抽取:sklearn.feature_extraction
(1)字典特征抽取
类 :sklearn.feature_extraction.DictVectorizer
作用:对字典数据进行特征值化
| DictVectorizer(sparse=True,...) | 构造函数,返回sparse矩阵 | sparse:true使用sparse矩阵返回,否则返回ndarray数组 |
| DictVectorizer.fir_transform(X) | 输入数据并转换 | 返回sparse矩阵; X字典或者包含字典的迭代器 |
| DictVectorizer.inverse_transform(X) | X:array数组或者sparse矩阵 | 返回转换之前的数据格式 |
| DictVectorizer.get_feature_names() | 返回特征(属性)的名称 | |
| DictVectorizer.transform(X) | 按照原先的标准转换 | |
| 注:使用sparse矩阵原因:节约内存,方便读取处理 | ||
from sklearn.feature_extraction import DictVectorizer
def dictVec():
"""
字典数据抽取
:return: None
"""
#实例化 sparse矩阵:节约内存,方便读取处理
#sparse=False,使用矩阵形式(numpy的ndarray形式)
"""
One-hot编码:出于公平起见,利于数据分析
[[1. 0. 1. 0.]
[0. 1. 0. 1.]]
"""
dict = DictVectorizer(sparse=False)
#调用fit_transform
data = dict.fit_transform([{'city':'北京', 'temperature':'100'}, {'city':'运城', 'temperature':'50'}])
data1 = dict.inverse_transform(data)
#字典数据抽取:把字典中一些类别的数据,分别进行转换成特征
print(dict.get_feature_names())
print(data)
print(data1)
return None
if __name__ == "__main__":
dictVec()
(2)文本特征抽取
类 :sklearn.feature_extraction.text.CountVectorizer
作用:对文本数据进行特征值化
| CountVectorizer() | 构造方法(初始化) | 返回词频矩阵 |
| CountVectorizer.fit_transform(X) | 输入数据并转换(特征抽取) | 返回sparse矩阵 |
| CountVectorizer.inverse_transform(X) | 返回转换之前的格式 | |
| CountVectorizer.get_feature_names() | 统计文章中所有出现的词(重复的只看做一次) | 返回单词列表 |
| 注:fit_transform的返回格式,利用toarray()进行sparse矩阵转换array数组 | ||
from sklearn.feature_extraction.text import CountVectorizer
def countVec():
"""
对文本进行特征值化
:return:
"""
cv = CountVectorizer()
#特征值提取
data = cv.fit_transform(["Life is short, i like python", \
"List is too long, i dislike python"])
print(data)
print(data.toarray()) #sparse矩阵转换成array数组
#统计单词
print(len(cv.get_feature_names()))
return None
if __name__ == "__main__":
countVec()中文问题处理:
直接处理的话,默认把一句话当成一个词,明显不能满足真正的需求,因此做中文处理之前,先进行分词处理
- 使用 jieba 进行分词
- import jieba
- jieba.cut("人生苦短,我学python")
- 注意:返回词语生成器
python——jieba库简介
(1)jieba库概述
jieba是优秀的中文分词第三方库
- 中文文本需要通过分词获得单个的词语
- jieba是优秀的中文分词第三方库,需要额外安装
- jieba库提供三种分词模式,最简单只需掌握一个函数
(2)jieba分词的原理
Jieba分词依靠中文词库
- 利用一个中文词库,确定汉字之间的关联概率
- 汉字间概率大的组成词组,形成分词结果
- 除了分词,用户还可以添加自定义的词组
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def cutWord():
"""
中文分词操作
:return: 词语生成器
"""
con1 = jieba.cut("古之立大志者,不惟有超世之才,亦必有坚韧不拔之志。——苏轼")
con2 = jieba.cut("美是到处都有的,对于我们的眼睛,不是缺少美,而是缺少发现。——罗丹")
con3 = jieba.cut("劳动一日,可得一夜的安眠;勤劳一生,可得幸福的长眠。——达·芬奇")
#词语生成器转换成列表
content1 = list(con1)
content2 = list(con2)
content3 = list(con3)
#列表转换成string
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1, c2, c3
def chinVec():
"""
中文特征值化
:return:None
"""
c1, c2, c3 = cutWord()
print(c1, c2, c3)
cv = CountVectorizer()
# 特征值提取
data = cv.fit_transform([c1, c2, c3])
print(data)
print(data.toarray())
# 统计单词
print(cv.get_feature_names())
print(len(cv.get_feature_names()))
return None
if __name__ == "__main__":
chinVec()(3)文本特征抽取(tf idf法)——文本分类
TF-IDF的主要思想:如果某个词或者短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
作用:用以评估一字词对于一个文件集或者一个语料库中其中一份文件的重要程度。
类 :sklearn.feature_extraction.text.TfidfVectorizer
tf(term frequency):词的频率
idf(inverse document frequency):逆文档频率
- tfidf做法:每个词都会有一个tf * idf,表示该词的重要性程度
注:逆文档频率公式 log(总文档数量 / 该词出现的文档数量)
| TfidfVectorizer(stop_words=None,...) | 初始化 | 返回词的权重矩阵 |
| TfidfVectorizer.fit_transform(X) | X:文本或者包含文本字符串的可迭代对象 | 返回sparse矩阵 |
| TfidfVectorizer.inverse_transform(X) | X:array数组或者sparse矩阵 | 返回转换之前的格式 |
| TfidfVectorizer.get_feature_names() | 返回单词列表 | |
| 注:按照切割词输出的顺序,对应给出每篇文章中每个词的重要性程度 | ||
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
def cutWord():
"""
中文分词操作
:return: 词语生成器
"""
con1 = jieba.cut("古之立大志者,不惟有超世之才,亦必有坚韧不拔之志。——苏轼")
con2 = jieba.cut("美是到处都有的,对于我们的眼睛,不是缺少美,而是缺少发现。——罗丹")
con3 = jieba.cut("劳动一日,可得一夜的安眠;勤劳一生,可得幸福的长眠。——达·芬奇")
#词语生成器转换成列表
content1 = list(con1)
content2 = list(con2)
content3 = list(con3)
#列表转换成string
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1, c2, c3
def chinVec():
"""
中文特征值化
:return:None
"""
c1, c2, c3 = cutWord()
print(c1, c2, c3)
tf = TfidfVectorizer()
# 特征值提取
data = tf.fit_transform([c1, c2, c3])
print(data) #sparse格式的权重
print(data.toarray()) #输出权重矩阵
# 统计单词
print(tf.get_feature_names())
print(len(tf.get_feature_names()))
return None
if __name__ == "__main__":
chinVec()为什么需要TfidfVectorizer?
分类机器学习算法的重要依据
















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











