






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
目录
前言
imageProjection的六个核心函数逐个解析。
一、copyPointCloud函数
该函数主要干了两件事:使用fromROSMsg函数将ROS格式的点云转换为PCL,然后再调用pcl库函数removeNaNFromPointCloud去除无效点。
void copyPointCloud(const sensor_msgs::PointCloud2ConstPtr& laserCloudMsg){
cloudHeader = laserCloudMsg->header; // 将接收到的点云消息的头部信息赋值给类成员 cloudHeader。
//cloudHeader.stamp = ros::Time::now(); // Ouster lidar users may need to uncomment this line
pcl::fromROSMsg(*laserCloudMsg, *laserCloudIn); // 使用 PCL 提供的函数将 ROS 中的 sensor_msgs::PointCloud2 转换为 PCL 的点云格式,存储在 laserCloudIn 中。
// Remove Nan points
std::vector<int> indices; // 移除点云中的 NaN(Not a Number)点。pcl::removeNaNFromPointCloud 函数用于删除包含 NaN 值的点,
// 操作的结果覆盖了原始的点云数据,并且有效的点的索引存储在 indices 中。
pcl::removeNaNFromPointCloud(*laserCloudIn, *laserCloudIn, indices);
// have "ring" channel in the cloud
// 如果 useCloudRing 标志为真,说明点云消息中包含了 "ring" 通道信息。接着,将 sensor_msgs::PointCloud2 转换为 PCL 格式的点云,并将其存储在 laserCloudInRing 中。如果点云不是稠密格式,会输出错误信息并终止 ROS 节点。
if (useCloudRing == true){
pcl::fromROSMsg(*laserCloudMsg, *laserCloudInRing);
if (laserCloudInRing->is_dense == false) {
ROS_ERROR("Point cloud is not in dense format, please remove NaN points first!");
ros::shutdown();
}
}
}二、findStartEndAngle函数
该函数目的是找点云的起始角和终止角。这里雷达坐标系为右前天坐标系,也就是东北天坐标系。使用收到的第一个点云和最后一个点云作为该帧点云的起始角和结束角。
atan2函数的范围是[-pi,pi],因为雷达是顺时针旋转,夹角应该不断增大,而在原坐标系是递减的,所以取负值。所以起始角是在[-pi,pi]之间,结束角是在[pi,3pi]之间。
如果起始角在[-pi,0],结束角在[2pi,3pi],后者减前者范围在[2pi,4pi],在减去2pi,可知结束角在[0,2pi];
如果起始角在[0,pi],结束角在[pi,2pi],后者减前者范围在[0,2pi],在加上2pi,可知结束角在[2pi,4pi];
void findStartEndAngle(){
// start and end orientation of this cloud
segMsg.startOrientation = -atan2(laserCloudIn->points[0].y, laserCloudIn->points[0].x);
segMsg.endOrientation = -atan2(laserCloudIn->points[laserCloudIn->points.size() - 1].y,
laserCloudIn->points[laserCloudIn->points.size() - 1].x) + 2 * M_PI;
// pi-3pi - -pi-pi 0-4pi
if (segMsg.endOrientation - segMsg.startOrientation > 3 * M_PI) {
segMsg.endOrientation -= 2 * M_PI; // pi - 2pi
} else if (segMsg.endOrientation - segMsg.startOrientation < M_PI)
segMsg.endOrientation += 2 * M_PI; // 2pi-3pi
segMsg.orientationDiff = segMsg.endOrientation - segMsg.startOrientation;
}三、projectPointCloud函数
该函数目的是把一帧点云进行图像化。首先,16线激光雷达点云分布在半径为100米一个球体内,那么如何把一帧点云中的每个点进行可表示化,也就是如何确定点云中每个点的位置。因此,考虑到16线激光雷达的垂直和水平分辨率(2°和0.2°),对其进行划分为16*1800份。这样,每个点的位置即可确认下来。例如,第10行,第100列的点。
水平划分时,需要计算当前点与水平面的夹角。代码中使用atan2函数,可见夹角范围在[-15°,15°]之间,即-15°,-13°,-11°,-9°,-7°,-5°,-3°,-1°,1°,3°,5°,7°,9°,11°,13°,15°。行索引计算公式为:(当前点夹角+15°)/2。因此,可得行索引范围是[0,15]
垂直划分时,首先找一个参考系,x轴正方向在右,y轴正方向在前。计算该点与x轴正方向的夹角,然后除以0.2。列索引范围为[0,1799]。代码中加了900,也就是在x轴正方向为H(900)。代码中同样加了判断,既然加了H,肯定有超过2H的,那就减去呗,X轴下方[0,H]的由来,如此形成了一个完整的闭环。
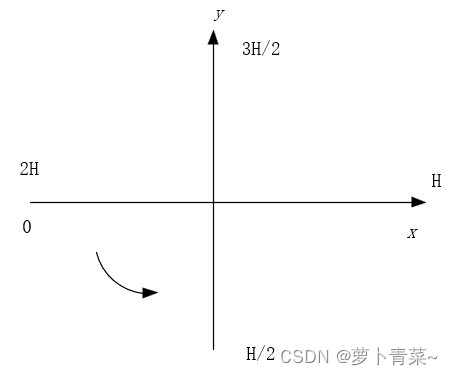
通过上面的处理,点云中的每个点都指定了行列索引。当然,这个索引可以转换为了线性索引,本来是16*1800,现在变成了0~16*1800-1,也就是index范围。代码将行列信息保存到了强度信息中。强度信息取整便是行,取余乘以10000便是列。
最终,fullCloud按线性索引存储了每个点(thisPoint),然后这个点里面包含了强度信息,这个强度信息包含了点的位置(行列索引)信息。fullInfoCloud中的每个点包含距离信息。
void projectPointCloud(){
// range image projection
float verticalAngle, horizonAngle, range;
size_t rowIdn, columnIdn, index, cloudSize;
PointType thisPoint;
cloudSize = laserCloudIn->points.size(); // 获取点云数量
for (size_t i = 0; i < cloudSize; ++i){
// 从输入点云中提取坐标信息
thisPoint.x = laserCloudIn->points[i].x;
thisPoint.y = laserCloudIn->points[i].y;
thisPoint.z = laserCloudIn->points[i].z;
// 如果使用环号信息,则从输入点云中提取环号
// find the row and column index in the iamge for this point
if (useCloudRing == true){
rowIdn = laserCloudInRing->points[i].ring;
}
else{
verticalAngle = atan2(thisPoint.z, sqrt(thisPoint.x * thisPoint.x + thisPoint.y * thisPoint.y)) * 180 / M_PI;
rowIdn = (verticalAngle + ang_bottom) / ang_res_y;
}
// 检查行号是否在有效范围内,如果不在则跳过当前点
if (rowIdn < 0 || rowIdn >= N_SCAN)
continue;
// 根据水平角度计算列号
horizonAngle = atan2(thisPoint.x, thisPoint.y) * 180 / M_PI;
columnIdn = -round((horizonAngle-90.0)/ang_res_x) + Horizon_SCAN/2;
if (columnIdn >= Horizon_SCAN)
columnIdn -= Horizon_SCAN;
// 检查列号是否在有效范围内,如果不在则跳过当前点
if (columnIdn < 0 || columnIdn >= Horizon_SCAN)
continue;
// 计算点的距离
range = sqrt(thisPoint.x * thisPoint.x + thisPoint.y * thisPoint.y + thisPoint.z * thisPoint.z);
// 如果距离小于传感器最小范围,则跳过当前点
if (range < sensorMinimumRange)
continue;
// 将距离信息保存到rangeMat矩阵中
rangeMat.at<float>(rowIdn, columnIdn) = range;
thisPoint.intensity = (float)rowIdn + (float)columnIdn / 10000.0;
index = columnIdn + rowIdn * Horizon_SCAN;
fullCloud->points[index] = thisPoint;
fullInfoCloud->points[index] = thisPoint;
fullInfoCloud->points[index].intensity = range; // the corresponding range of a point is saved as "intensity"
}
}四、groundRemoval函数
好了,接下来就对16*1800点进行操作了。首先是去除分离地面点,便于后续进行分割操作。前面提到这些点的行索引是[0,15]。代码是对行索引小于7的点进行判断是否构成了地面点,也就是点与激光雷达平面的夹角小于-1°的点。
关于地面点的判断方法如下,相邻行处于且同一列的两个点与水平面的夹角小于10°,那么这两个点构成了地面点。下面这张图能形象看出来,当这个夹角越小时,越平,越大越直。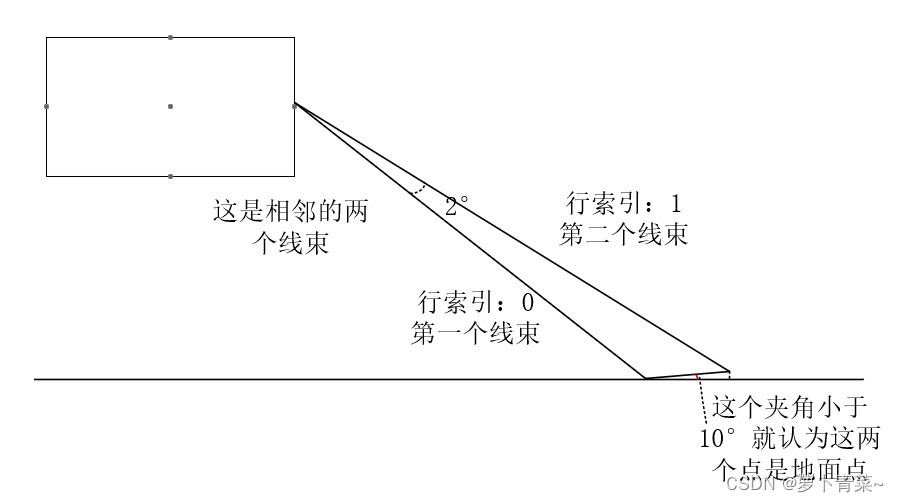
通过上面的判断,我们就能得到地面点信息了。代码中使用了7*1800大小的groundMat用于标记地面点,是地面点则为1,否则为-1。好了,现在通过groundMat,我们就能得到地面点了。当然,并不是所有行列索引都有点,自然距离也就不存在了。所以,代码中使用了16*1800大小的labelMat存储没有距离值且为地面点的信息,其中-1代表地面点。
最终,groundCloud存储地面点,这些地面点的强度值是行和列信息。现在,读代码应该不是难事了。
void groundRemoval(){
// 初始化参数
size_t lowerInd, upperInd;
float diffX, diffY, diffZ, angle;
// groundMat
// -1, no valid info to check if ground of not
// 0, initial value, after validation, means not ground
// 1, ground
// 遍历每个激光线(column)和每个扫描环(row)
for (size_t j = 0; j < Horizon_SCAN; ++j){
for (size_t i = 0; i < groundScanInd; ++i){
// 计算当前线和下一环之间的索引:
lowerInd = j + ( i )*Horizon_SCAN;
upperInd = j + (i+1)*Horizon_SCAN;
// 检查两个点是否有效,如果有无效点则标记为 -1:
if (fullCloud->points[lowerInd].intensity == -1 ||
fullCloud->points[upperInd].intensity == -1){
// no info to check, invalid points
groundMat.at<int8_t>(i,j) = -1;
continue;
}
// 计算两个相邻点之间的高度差和夹角:
diffX = fullCloud->points[upperInd].x - fullCloud->points[lowerInd].x;
diffY = fullCloud->points[upperInd].y - fullCloud->points[lowerInd].y;
diffZ = fullCloud->points[upperInd].z - fullCloud->points[lowerInd].z;
angle = atan2(diffZ, sqrt(diffX*diffX + diffY*diffY) ) * 180 / M_PI;
// 如果夹角接近地面平面(sensorMountAngle),则标记为地面点:
if (abs(angle - sensorMountAngle) <= 10){
groundMat.at<int8_t>(i,j) = 1;
groundMat.at<int8_t>(i+1,j) = 1;
}
}
}
// extract ground cloud (groundMat == 1)
// mark entry that doesn't need to label (ground and invalid point) for segmentation
// note that ground remove is from 0~N_SCAN-1, need rangeMat for mark label matrix for the 16th scan
// 如果为地面或者rangeMat为空,则标记为-1,后面去除这些点
for (size_t i = 0; i < N_SCAN; ++i){
for (size_t j = 0; j < Horizon_SCAN; ++j){
if (groundMat.at<int8_t>(i,j) == 1 || rangeMat.at<float>(i,j) == FLT_MAX){
labelMat.at<int>(i,j) = -1;
}
}
}
// 如果存在订阅者,则将地面点添加到 groundCloud 中:
if (pubGroundCloud.getNumSubscribers() != 0){
for (size_t i = 0; i <= groundScanInd; ++i){
for (size_t j = 0; j < Horizon_SCAN; ++j){
if (groundMat.at<int8_t>(i,j) == 1)
groundCloud->push_back(fullCloud->points[j + i*Horizon_SCAN]);
}
}
}
}五、cloudSegmentation函数
上面labelMat存储了所有的点,其中值为0对应的是非地面点,-1则为地面点。接下来,这个函数里的代码,通过if(labelMat.at<int>(i,j)=0)判断,即可对非地面点进行处理。
对非地面点进行分割目的就是尽可能找出属于同一个物体的所有点,进行归类,也就是聚类操作,这样是方便后续的特征提取操作。
代码首先使用两个for循环,若是地面点则进入labelComponets函数。首先,我们看一下labelComponets函数。该函数输入是行列索引,
设想一下,如果用激光雷达扫描一下物体,如果这个物体垂直于地面,那么激光雷达扫描到这个物体表面的点是垂直于水平面的。如下图,现在16线激光雷达扫描到一个正方体(正视图)和一个三棱柱,我们该如何区分扫描的点哪些是属于正方体的呢?哪些属于三棱柱的呢?代码中提供的思路是:先找到给定一点相邻的四个点(同一线束的左右相邻点和不同线束的上下相邻点),判断该点依次和这四个点以及激光雷达构成的三角形最长边与物体表面的夹角,这个夹角超过60°,且越大意味是属于同一物体。实际上这个角最大值应该小于90°的,想一想,16线激光雷达同时扫描一个房屋(垂直地面)。从上下看的话,任意相邻两个线束中最长的那条与房子表面的夹角是小于90°的。且低于激光雷达高度(2m)的房子表面,该角是逐渐增大的。高于激光雷达高度(2米)的房子表明该角是逐渐减小的。

回归到核心问题上,这个角位于60°~90°为啥能反映这两个点是否是同一物体上的?下面画一个三角形进行解释: 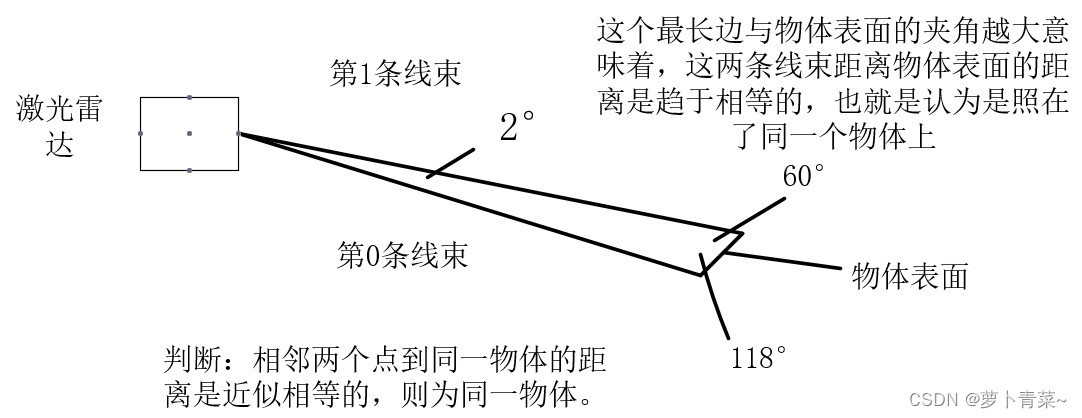
其实,不同线束时,这个夹角范围在(60°,89°],相同线束时这个夹角范围在(60°,89.4°]。
现在有这么多点,该如何判断呢?于是代码中采用广度优先遍历算法。例如,从(0, 0)点开始,找其相邻点有(0,1),(1,0)和(0,1799),这三点标记已访问。采用上面判断方式逐个判断是否是同一物体上的点,是则标记标签0(相同标签值表示相同物体上的点),接着从(0,1)开始,重复上述过程;再接着从(1,0),不断进行搜索判断。这样看来,似乎调用一次labelComponents函数即可。其实不然,这个函数labelComponents找到同一物体的点就停止了,其它相隔很远的点就不进行搜索了。因此,代码中需要遍历每个点,不过好的是,函数内部对其进行了标记,搜索过的点直接跳过。
代码中判断同一标签值的点超过30个,或者横跨连续三条线束的点超过5个,则认为属于同一物体,标签值加1,否则标记为999999。通过labelComponents函数,labelMat矩阵中又多了物体的标签值。-1表示地面点。0表示地面点,然后这些标记为0的点通过聚类变成含有1,2,3,...,n的标签值,另外999999表示噪声点或者后续要丢弃的点。
聚类完之后,对于非地面点(行数超过7的)且没有聚类成功的,称之为outlierCloud,代码中对这些点在每个线束上按5的倍数进行提取,保存到outlierCloud点云中。对于地面点保存到了segmentedCloud中,每个点的强度值是其行列索引。
最后,将分割后的点云保存到了segmentedCloud中,每个点的强度值对应标签值。
void cloudSegmentation(){
// segmentation process
for (size_t i = 0; i < N_SCAN; ++i)
for (size_t j = 0; j < Horizon_SCAN; ++j)
if (labelMat.at<int>(i,j) == 0)
labelComponents(i, j);
int sizeOfSegCloud = 0;
// extract segmented cloud for lidar odometry
// 提取分割云用于激光雷达里程计
// 遍历所有点
for (size_t i = 0; i < N_SCAN; ++i) {
segMsg.startRingIndex[i] = sizeOfSegCloud - 1 + 5;
for (size_t j = 0; j < Horizon_SCAN; ++j) { // 遍历所有点
if (labelMat.at<int>(i,j) > 0 || groundMat.at<int8_t>(i,j) == 1){
// 不会用于优化的异常值(始终继续)
if (labelMat.at<int>(i,j) == 999999){ // //该点是一个没有聚类的噪点
if (i > groundScanInd && j % 5 == 0){ //简单的过滤
outlierCloud->push_back(fullCloud->points[j + i*Horizon_SCAN]); //将该点加入噪点的点云中
continue;
}else{
continue;
}
}
// majority of ground points are skipped
// // 2. 如果为地,跳过index不是5的倍数的点
if (groundMat.at<int8_t>(i,j) == 1){ //如果该点是地面点
if (j%5!=0 && j>5 && j<Horizon_SCAN-5) //每5个点采一个点
continue;
}
// 3. 这里有可能是地面,也有可能是分割之后的点
// mark ground points so they will not be considered as edge features later
// 标记接地点,这样以后就不会被认为是边缘特征
segMsg.segmentedCloudGroundFlag[sizeOfSegCloud] = (groundMat.at<int8_t>(i,j) == 1); //标志地面点
// 标记点的列索引,以便以后标记遮挡
segMsg.segmentedCloudColInd[sizeOfSegCloud] = j;
// 保存距离信息
segMsg.segmentedCloudRange[sizeOfSegCloud] = rangeMat.at<float>(i,j);
// 保存分割点云
segmentedCloud->push_back(fullCloud->points[j + i*Horizon_SCAN]);
// size of seg cloud
// 分割点云大小
++sizeOfSegCloud;
}
}
segMsg.endRingIndex[i] = sizeOfSegCloud-1 - 5;
}
// 4. 分割后的点云,不包含地面
// //可视化 聚类的点和 地面点
// extract segmented cloud for visualization
if (pubSegmentedCloudPure.getNumSubscribers() != 0){
for (size_t i = 0; i < N_SCAN; ++i){
for (size_t j = 0; j < Horizon_SCAN; ++j){
if (labelMat.at<int>(i,j) > 0 && labelMat.at<int>(i,j) != 999999){
segmentedCloudPure->push_back(fullCloud->points[j + i*Horizon_SCAN]);
segmentedCloudPure->points.back().intensity = labelMat.at<int>(i,j);
}
}
}
}
}
void labelComponents(int row, int col){
// use std::queue std::vector std::deque will slow the program down greatly
float d1, d2, alpha, angle; // d1,d2是距离激光雷达距离;alphas是激光束间夹角,angle是判断角度;
int fromIndX, fromIndY, thisIndX, thisIndY;
bool lineCountFlag[N_SCAN] = {false};
//初始化变量:
// 初始化队列,将初始点加入队列和已处理点集合:
queueIndX[0] = row;//队列把行和列分布设置了一个队列,行和列构成一个点元素。
queueIndY[0] = col;
int queueSize = 1; // 初始化队列的长度为1
int queueStartInd = 0; //queueSize 初始化队列的长度为1
// queueStartInd 开始索引 queueEndInd 结束索引
int queueEndInd = 1;
allPushedIndX[0] = row;
allPushedIndY[0] = col;
int allPushedIndSize = 1;
// 判断队列的长度,当队列长度等于0,即遍历结束
while(queueSize > 0){
// Pop point
// // 弹出队首点
// 首先取出队首的元素
// 队列长度减1
//队列开始索引加1
fromIndX = queueIndX[queueStartInd];
fromIndY = queueIndY[queueStartInd];
--queueSize;
++queueStartInd;
// Mark popped point
// 标记已处理点
labelMat.at<int>(fromIndX, fromIndY) = labelCount;
//进行点云聚类的标记,labelCount就是聚类的id标签
// Loop through all the neighboring grids of popped grid
// 遍历弹出点的相邻点
// 然后开始遍历邻接顶点
//[-1 0 ] [0 1] [0 -1] [1 0] 就是上下左右
for (auto iter = neighborIterator.begin(); iter != neighborIterator.end(); ++iter){
// new index
// 新的索引
thisIndX = fromIndX + (*iter).first;//取出邻接点的 坐标 // 左或右
thisIndY = fromIndY + (*iter).second; // 上或下
// index should be within the boundary
// 索引应在边界内
//垂直方向上,上下边界点不作为邻接
if (thisIndX < 0 || thisIndX >= N_SCAN)
continue;
// 处于深度图边缘(左侧或右侧)
// at range image margin (left or right side)
//水平方向上,左右边界点为邻接
if (thisIndY < 0)
thisIndY = Horizon_SCAN - 1;
if (thisIndY >= Horizon_SCAN)
thisIndY = 0;
// prevent infinite loop (caused by put already examined point back)
// 避免无限循环(已经处理过的点重新放回队列)//
// 判读该点是否被访问过,如果被访问过,或者是地面点等,该值就不是0
if (labelMat.at<int>(thisIndX, thisIndY) != 0)
continue;
// 计算深度差和夹角
// 取出这两点的d1和d2 ,d1是长的一边,d2是短的一边
d1 = std::max(rangeMat.at<float>(fromIndX, fromIndY),
rangeMat.at<float>(thisIndX, thisIndY));
d2 = std::min(rangeMat.at<float>(fromIndX, fromIndY),
rangeMat.at<float>(thisIndX, thisIndY));
// 根据邻接点是垂直方向和是水平方向设置 激光束夹角
// 垂直方向是 2°
// 水平方向是 0.2°
if ((*iter).first == 0)
alpha = segmentAlphaX; // 0 的话表示左右,夹角是0.2°
else
alpha = segmentAlphaY; // 1 的话表示上下, 夹角是2°
angle = atan2(d2*sin(alpha), (d1 -d2*cos(alpha))); // 计算角度
// 根据夹角和阈值判断是否属于同一组件
// 如果角度大于阈值,阈值为60°,则认为是一个聚类;
if (angle > segmentTheta){
// 把点加入队列
queueIndX[queueEndInd] = thisIndX;
queueIndY[queueEndInd] = thisIndY;
++queueSize; // 队列长度增加1
++queueEndInd; // 队列末尾索引加1
labelMat.at<int>(thisIndX, thisIndY) = labelCount; // 给该点附上标签
lineCountFlag[thisIndX] = true; // 该行有被处理
allPushedIndX[allPushedIndSize] = thisIndX; // 本次聚类结果
allPushedIndY[allPushedIndSize] = thisIndY;
++allPushedIndSize;
}
}
}
// check if this segment is valid
bool feasibleSegment = false; // //初始化聚类是否有效 初始化为无效
if (allPushedIndSize >= 30) // 如果聚类点数大于30,即说明该聚类成功
feasibleSegment = true;
// 点数小于30,再做次判断,因为垂直方向,角分辨率较大,如果物体垂直,
// 那么出现的点则会比较少,判断垂直方向上出现的聚类次数,如过大于阈值,认为聚类成功,代码中阈值为3
else if (allPushedIndSize >= segmentValidPointNum){
int lineCount = 0;
for (size_t i = 0; i < N_SCAN; ++i)
if (lineCountFlag[i] == true)
++lineCount; //
if (lineCount >= segmentValidLineNum)
feasibleSegment = true;
}
// segment is valid, mark these points
if (feasibleSegment == true){
++labelCount; //如果聚类成功 将标签加1
// 如果 聚类失败,将聚类失败的点 打上标签 999999
// 以上完成了labelComponents函数的代码,将一帧里面可以聚类的点附上标签,
// 不可以聚类的点付上999999.
}else{ // segment is invalid, mark these points
for (size_t i = 0; i < allPushedIndSize; ++i){
labelMat.at<int>(allPushedIndX[i], allPushedIndY[i]) = 999999;
}
}
}六、publishCloud函数
最后,publishCloud发布点云以及其它信息。包括:
1. outlierCloud点云:该点云是非地面点且未聚类成功的点的集合;
2. segmentedCloud点云:地面点的集合,强度值是索引;
3. fullCloud点云:所有点的集合,强度值是索引
4. fullInfoCloud点云:所有点集合,强度值是点到雷达的距离;
5. groundCloud点云:地面点集合,强度值是索引;
6. segmentedCloudPure点云:非地面点进行分割后的点集合,强度值是标签值,相同标签值代表同一物体,从1开始算起。
7. segmentedCloudInfo信息:包括去掉每个线束的首尾五个点的索引信息,地面点的位置,列索引以及距离信息。
void publishCloud(){
// 1. Publish Seg Cloud Info
segMsg.header = cloudHeader;
pubSegmentedCloudInfo.publish(segMsg);
// 2. Publish clouds
sensor_msgs::PointCloud2 laserCloudTemp;
pcl::toROSMsg(*outlierCloud, laserCloudTemp);
laserCloudTemp.header.stamp = cloudHeader.stamp;
laserCloudTemp.header.frame_id = "base_link";
pubOutlierCloud.publish(laserCloudTemp);
// segmented cloud with ground
pcl::toROSMsg(*segmentedCloud, laserCloudTemp);
laserCloudTemp.header.stamp = cloudHeader.stamp;
laserCloudTemp.header.frame_id = "base_link";
pubSegmentedCloud.publish(laserCloudTemp);
// projected full cloud
if (pubFullCloud.getNumSubscribers() != 0){
auto remove_from = std::remove_if(fullCloud->points.begin(), fullCloud->points.end(), [](const auto& points) {
return points.intensity < 0;
});
fullCloud->points.erase(remove_from);
fullCloud->width = fullCloud->points.size();
// 上面从auto 到 width 为新增
pcl::toROSMsg(*fullCloud, laserCloudTemp);
laserCloudTemp.header.stamp = cloudHeader.stamp;
laserCloudTemp.header.frame_id = "base_link";
pubFullCloud.publish(laserCloudTemp);
}
// original dense ground cloud
if (pubGroundCloud.getNumSubscribers() != 0){
pcl::toROSMsg(*groundCloud, laserCloudTemp);
laserCloudTemp.header.stamp = cloudHeader.stamp;
laserCloudTemp.header.frame_id = "base_link";
pubGroundCloud.publish(laserCloudTemp);
}
// segmented cloud without ground
if (pubSegmentedCloudPure.getNumSubscribers() != 0){
pcl::toROSMsg(*segmentedCloudPure, laserCloudTemp);
laserCloudTemp.header.stamp = cloudHeader.stamp;
laserCloudTemp.header.frame_id = "base_link";
pubSegmentedCloudPure.publish(laserCloudTemp);
}
// projected full cloud info
if (pubFullInfoCloud.getNumSubscribers() != 0){
pcl::toROSMsg(*fullInfoCloud, laserCloudTemp);
laserCloudTemp.header.stamp = cloudHeader.stamp;
laserCloudTemp.header.frame_id = "base_link";
pubFullInfoCloud.publish(laserCloudTemp);
}
}实际上,在featureAssociation订阅的有三个,segmentedCloudInfo信息, segmentedCloudPure点云信息和outlierCloud点云点云。
















 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











