








📑来源
本文图片均收集自网络
⭐推荐
建议观看以下计算机字符编码方式科普视频
《锟斤拷是怎样炼成的——中文显示“入”门指南【柴知道】》,bilibili @ 柴知道
https://www.bilibili.com/video/BV1cB4y177QR
《你懂乱码吗?锟斤拷烫烫烫(详解 ASCII、Unicode、UTF-32、UTF-8编码)》,bilibili @ 林粒粒呀
https://www.bilibili.com/video/BV1xP4y1J7CS
基础概念
字符和字符集
**字符(character)**可以简单地理解为计算机表示信息的单位
像符号、数字、字母、文字、emoji 表情等肉眼能直接看见的文本或表情都是可见字符(打印字符)
像换行、回车、换页等肉眼不可见,但是却能对文本进行控制的不可见字符(控制字符)
不可见字符中,空格、回车、换行、水平制表、垂直制表还被称为空白字符
**字符集(character set)**就是字符的集合,如常见的 ASCII 字符集,GB2312 字符集,Unicode 字符集等
编号和编码
一个字符集会给每个字符都规定个数字编号
由于计算机只能识别 0 和 1,因而在计算机内部,所有的信息最终都表示为一个二进制串,比如 100111101100000,每一个二进制位(bit)有 0 和 1 两种状态,而将字符对应到一个二进制串的过程,叫做字符编码(character encoding)
💬注释
下文如无特殊说明,出于方便,编码均采用 16 进制数字进行表示,但实际上最终存储在计算机中还是 2 进制的数字
一般对于比较小的字符集不用考虑太多,一个字符集就只有一种编码方式,只要转换成二进制,一个字符的编号就是它的编码。但对像 Unicode 这种比较大的字符集就不一定是了,它有着多种编码方式,编号也不等于编码
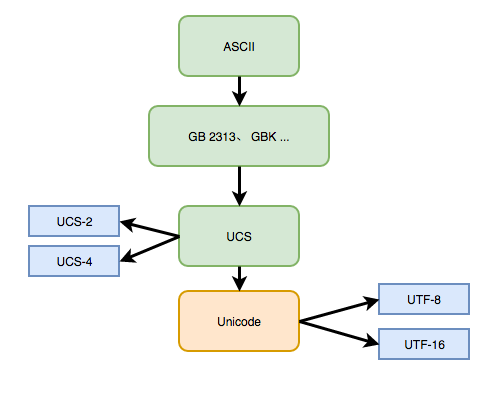
字符集发展史
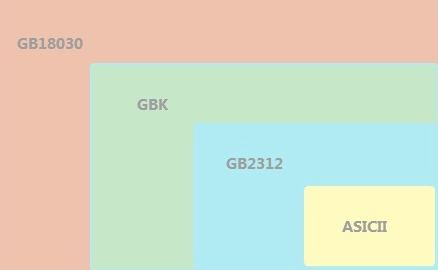
字符集有一个发展历史,ASCII 是最早出现的字符集,仅含有 128 个字符,但局限于英文字母和部分符号,无法适用于非英语国家和地区,即便是后来拓充成 ASICII 字符集也不够用
后来各个国家和地区都推出了自己的字符集,如中国大陆推出 GB2312、GBK、GB18030,中国港澳台地区推出 Big5 等
但各地标准不统一,同一个编码在不同字符集里对应的很可能是完全不同的字符,这就导致乱码现象,最终才出现相关组织意推出囊括全球的大一统字符集 UCS 和 Unicode
目前主流的字符集是 Unicode,采取 UTF-8 编码方式
GB2312、GBK、GB18030
发展历史
其实“GB”就是“国标”,“K”就是“扩”的意思
- 1980年, GB2312-80(我国的第一套汉字集标准),共包含7445个字符,其中6763个常用汉字
- 1995年,GBK,由GB2312-80(和港、台两种标准)扩展而来,共包含21886个字符,其中常用汉字14240个
- 2000年,GB18030-2000编码标准是由信息产业部和国家质量技术监督局在2000年3月17日联合发布的,并且作为一项国家标准在2001年的1月正式强制执行;增加了6351个字符,其中一部分为4字节字(four-byte encoding range)
- 2005年,GB18030-2005《信息技术中文编码字符集》是中国制订的以汉字为主并包含多种中国少数民族文字(如藏、蒙古、傣、彝、朝鲜、维吾尔文等)的超大型中文编码字符集强制性标准,其中收入汉字70000余个
GB2312 收录的是最常用的汉字,可以说我们用到的 99% 的汉字,都属于 GB2312 编码范围
目前用的最为广泛的中文字符集是 GBK
编码方式
📑对应
GB2312、GBK、GB18030 编码知识均学习自《彻底搞明白 GB2312、GBK 和 GB18030》
https://zhuanlan.zhihu.com/p/453675608
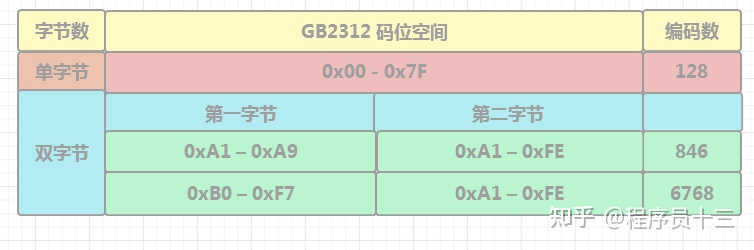
GB2312 把每个汉字都编码成两个字节,第一个字节称为"高位字节",第二个字节称为"低位字节"
平常说的“英文字母单字节,中文汉字双字节”就出自于此
“半角”和“全角”的概念也出自于此,“半角”是占单字节的字符,“全角”是占双字节的字符,中文由于全是双字节因而没有半角和全角的区别,或者说中文全是全角。但英文和部分标点符号有半角和全角的区别,全角的英文和部分标点符号显示表现为更“胖”了
GBK 也是把每个汉字都编码成两个字节,但编码范围更广,涵盖字符数量更多

GB18030 是变长多字节编码,每个字或字符可以由一个,两个或四个字节组成

GB2312、GBK、GB18030 依次在前者的基础上扩充而来,因而都能向前兼容
Unicode
Unicode,也被称为万国码、统一码
狭义的 Unicode 就只是字符集,广义的 Unicode 是一套标准,包括了字符集和编码规则
Unicode 规定了每个字符的数字编号,这个 Unicode 编号被称为码点(code point)或码位(code position),通常在编号前面加上"U+"表示是 Unicode 的编号
Unicode 的实现方式,也就是编码方式,被称为 Unicode 转换格式(Unicode Transformation Format,UTF),目前有 UTF-8、UTF-16、UTF-32 几套方案
考虑到存储空间、格式识别等一系列因素,码点一般都不等于编码,需要进行一定的处理才形成编码
如对于字符“你”而言
| 码点 | UTF-8 编码 | UTF-16 编码 | UTF-32 编码 |
|---|---|---|---|
| 4F60 | E4 BD A0 | 4F 60 | 00 00 4F 60 |
💬相关
Unicode 字符百科
https://unicode-table.com/cn/blocks/
编码方式
📑对应
Unicode 编码知识部分学习自《UTF8、UTF16、UTF32区别》
https://blog.csdn.net/zhaohong_bo/article/details/89196938
UTF-8:当编码为一个字节,则设最高比特位为 0,当编码超过一个字节,则需要几个字节,就在第一个字节从最高位开始令连续的几个比特位为 1,之后的字节最高位为 10

UTF-16:使用2或4个字节进行存储。对于 Unicode 编号范围在 0~FFFF 之间的字符,统一用两个字节存储,无需字符转换,直接存储 Unicode 编号。对于 Unicode 字符编号在 10000-10FFFF 之间的字符,UTF-16 用四个字节存储

UTF-32:用固定长度的字节存储字符编码,不管 Unicode 字符编号需要几个字节,全部都用 4 个字节存储,直接存储Unicode 编号
平面
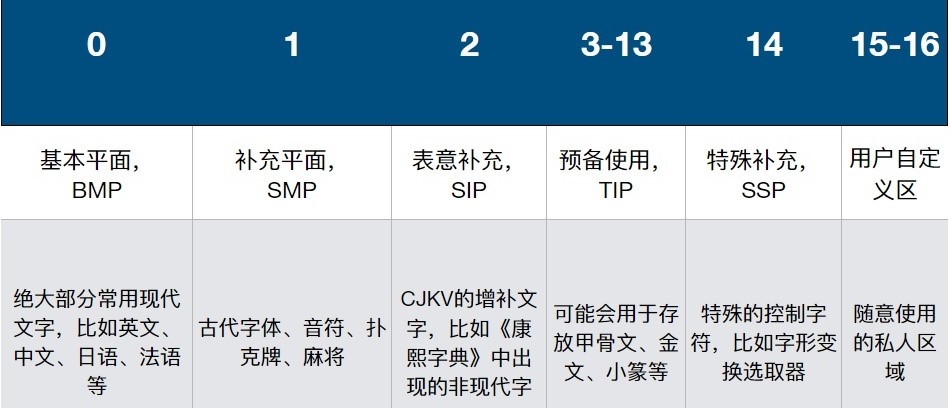
目前的 Unicode 字符分为 17 组编排,每组称为一个平面(Plane),而每平面拥有 65536(即 2¹⁶)个码点
每个平面还根据用途划分成若干个区块(Block),区块相当于把同类字符放在一起,方便检索和补充
而首个 16 位统一码字符的平面称为基本多文种平面(BMP),写成 16 进制就是从 U+0000 到 U+FFFF,剩下还有 16 个辅助平面(SMP),码点范围从 U+010000 一直到 U+10FFFF,绝大部分的常见字符都在首个平面
这 17 个平面结合起来至少需要占据 21 位的空间,也就是差不多 3 个字节(24 位),而辅助平面实际上是用 4 个字节表示,方便以后向后扩展。
-
第 0 平面称为BMP(Basic Multilingual Plane)平面,又称为基本多文种平面
-
第 1 辅助平面称为 SMP(Supplementary Multilingual Plane)平面,又称为多文种补充平面,主要摆放拼音文字及符号
-
第 2 辅助平面称为 SIP(Supplementary Ideographic Plane)平面,又称为表意文字补充平面,其范围为 20000-2FFFF。
-
第 3 辅助平面称为 TIP(Tertiary Ideographic Plane)平面,又称为表意文字第三平面,其范围为 30000-3FFFF
-
第 4 至 13 辅助平面尚未使用
-
第 14 辅助平面称为 SSP(Supplementary Special-purpose Plane)平面,又称为特殊用途补充平面,摆放语言标签(Language Tags)和异体字选择器(Variation Selectors),这些都是控制字符,其范围为 E0000-EFFFF
-
第 15 辅助平面为补充私人使用区-A (Supplementary Private Use Area-A),其范围为 F0000-FFFFF
-
第 16 辅助平面为补充私人使用区-B(Supplementary Private Use Area-B),其范围为 100000-10FFFF
emoji
emoji 表情也可以被称作绘文字、彩色象形字符,算是一类特殊的字符,如 。最开始的 emoji 源于日语“絵文字”,是日本手机使用的表情,后来才被部分收录进 Unicode 字符集
起初,Unicode 中的 emoji 表情只有黑色,而随着 emoji 表情的发展,越来越多 emoji 表情开始有了彩色版本
此处额外提及一下另一个词“颜文字”,源于日语“顔文字(kaomoji)”,颜文字是指用若干个字符排列成表情的样子,如 O(∩_∩)O ,和 emoji 表情完全不是一个概念,但有的地方会把二者混为一谈
💬相关
目前 Unicode 中收录的所有 emoji 表情
https://www.unicode.org/emoji/charts/emoji-list.html
各版本 Unicode 中收录的 emoji 表情的相关数据
https://unicode.org/Public/emoji/
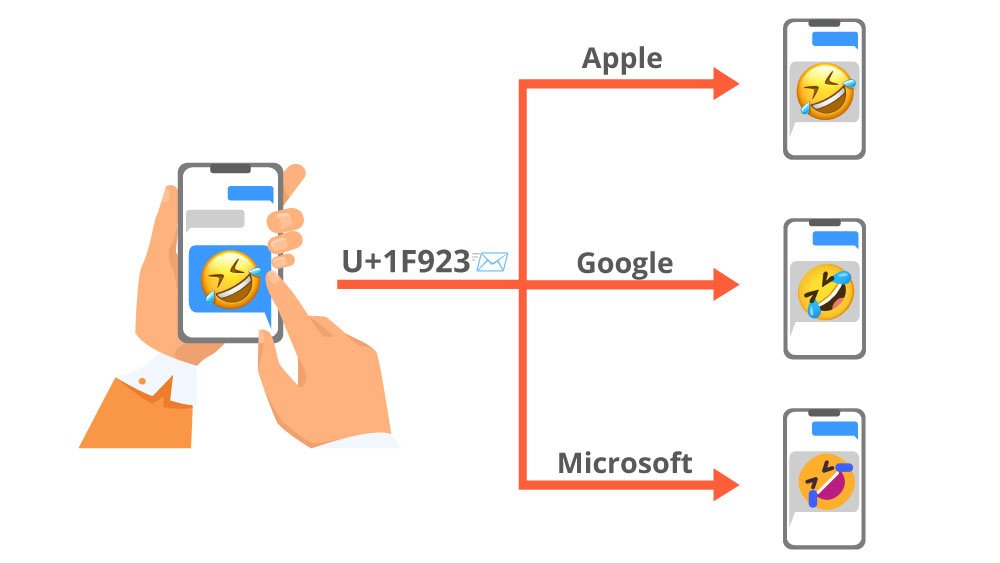
Unicode 只是规定了 emoji 的码点和含义,并没有规定它具体表现成什么形式,Unicode 联盟主要负责的就是 emoji 的审核、管理和编码等工作,而设计 emoji 外观的任务则交到了各平台手里
有的平台出于规避版权风险,有的平台出于自己的设计理论、品牌风格来重新设计 Emoji 表情。比如有的 Emoji 表情富有立体感,并含有着渐变和阴影的细节,有的 Emoji 表情趋于扁平简约化

因而发出去同个 emoji 表情(同个码位),在不同平台上看到的样式可能是截然不同的

💬相关
emoji 的百科网站
网站 Emojipedia
https://emojipedia.org/zh/
网站 EmojiXD
https://emojixd.com/
网站 EMOJIALL
https://www.emojiall.com/zh-hans
输入
emoji 表情没有办法直接通过键盘输入,但可以通过复制粘贴,或通过码点输入 emoji 表情(对于其他 Unicode 字符也同样适用)
dddd是十进制码点,hhhh是十六进制码点- 在 HTML 中,可以写成 HTML 实体
&#dddd;或&#xhhhh; - 在 CSS 中,可以写成
\hhhh - 在 JavaScript 中,可以写成
\uhhhh - 在部分平台上(如 GitHub、Slack 等),可以使用 emoji 简短代码(Emoji Shortcode)
- 有的平台可能会有特定的快捷输入 emoji 的方式
以 emoji 表情为例,可以将其码点 U+1F600 写成 HTML 形式 😀(十进制)或 😀(十六进制),CSS 形式 \1F600,JavaScript 形式 \uD83D\uDE00(辅助平面的字符需借助 UTF-16 编码成 8 位),在部分平台上简短代码 :grinning:,
💬相关
emoji 简短代码介绍
https://www.emojiall.com/zh-hans/help-shortcode
微信快捷输入 emoji 表情方法
https://www.emojiall.com/zh-hans/platform-wechat
序列
📑对应
emoji 序列相关知识学习自《emoji 编码规则介绍》
https://blog.csdn.net/chriscross/article/details/104746788
一个 emoji 表情,通常由一个 Unicode 码点表示,但也可以由多个 Unicode 码点组合成一个序列表示
但由于并不是所有的系统都支持最新的 emoji 标准,因而在有的系统上,多个 Unicode 码点组合成一个序列表示 emoji 表情会被拆成多个 emoji 表情进行显示
表示序列
有些字符,它既可以显示成黑白文本,也可以显示成彩色 emoji 表情,有的默认显示为前者,有的默认显示为后者,此处列举几个
表示序列(emoji presentation sequence),用于说明一个字符显示为文本还是 emoji 表情
如果一个字符后面加上 U+FE0E,那么它就作为文本显示
如果一个字符后面加上 U+FE0F,那么它就作为 emoji 表情显示
📋格式
基础字符 + 显示方式 = 文本/emoji表情
📝例子
⛄(
U+26C4) +U+FE0E= ⛄︎(U+26C4 U+FE0E)
📝例子
修饰序列
修饰序列(emoji modifier sequence),由一个基础字符(base)和一个修饰字符(modifier)组成,主要用来修改 emoji 表情中人的肤色

📋格式
基础 emoji 表情 + 肤色 = 对应肤色的 emoji 表情
📝例子
🧑(
U+1F9D1) + 🏾(U+1F3FE) = 👨🏾(U+1F9D1 U+1F3FE)
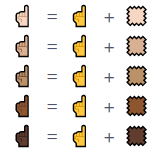

💬相关
emoji 肤色类型
https://www.arpansa.gov.au/sites/default/files/legacy/pubs/RadiationProtection/FitzpatrickSkinType.pdf
旗帜序列
旗帜序列(emoji flag sequence)
📋格式
区域指标字母1 + 区域指标字母2 = 2个字母组成的国家码对应的国旗
📝例子
🇨(
U+1F1E8) + 🇳(U+1F1F3) = 🇨🇳(U+1F1E8 U+1F1F3)
键盘序列
键盘序列(emoji keycap sequence)
📋格式
数字 +
U+FE0E+ 方框 = 数字键盘
📝例子
2(
U+0032) +U+FE0F+ ⃣ (U+20E3) = 2️⃣ (U+0032 U+FE0F U+20E3)
零宽连接序列
零宽连接序列(emoji zero width joint sequence),通过 ZWJ 等宽连接符(U+200D),对多个 emoji 表情进行组合
目前有 5 种组合方式
📋格式
emoji 表情1 +
U+200D+ emoji 表情2 = 合成 emoji 表情
📝例子
👨(
U+1F468) +U+200D+ 👩(U+1F469) +U+200D+ 👧(U+1F467)= 👨👩👧(U+1F468 U+200D U+1F469 U+200D U+1F467)















 3408
3408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









