







目录
描述:
在headless为true模式下,发现无法获取对应的元素,一开始以为是自己写的组件名称不对,无法识别,但是将元素的名称去控制台中去搜索是可以锁定的。而当我将headless设置为false,一切就都很正常,代码如下
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless:true
});
const page = await browser.newPage();
await page.goto('https://www.staples.com/paint/cat_CL140420');
const bodyHandle = await page.waitForSelector("#searchTerm");
const html = await page.evaluate(body => {
return body.innerHTML;
}, bodyHandle);
console.log(html)
await browser.close();
})();运行的结果:
(node:21380) UnhandledPromiseRejectionWarning: TimeoutError: waiting for selector `#searchTerm` failed: timeout 30000ms exceeded
at new WaitTask (I:\puppeteer\node_modules\puppeteer\lib\cjs\puppeteer\common\DOMWorld.js:609:34)
at DOMWorld._waitForSelectorInPage (I:\puppeteer\node_modules\puppeteer\lib\cjs\puppeteer\common\DOMWorld.js:520:26)
at Object.internalHandler.waitFor (I:\puppeteer\node_modules\puppeteer\lib\cjs\puppeteer\common\QueryHandler.js:34:29)
at DOMWorld.waitForSelector (I:\puppeteer\node_modules\puppeteer\lib\cjs\puppeteer\common\DOMWorld.js:455:36)
at Frame.waitForSelector (I:\puppeteer\node_modules\puppeteer\lib\cjs\puppeteer\common\FrameManager.js:1007:51)
at Page.waitForSelector (I:\puppeteer\node_modules\puppeteer\lib\cjs\puppeteer\common\Page.js:2224:39)
at I:\puppeteer\index.js:14:35
(Use `node --trace-warnings ...` to show where the warning was created)
(node:21380) UnhandledPromiseRejectionWarning: Unhandled promise rejection. This error originated either by throwing inside of an async function without a catch block, or by rejecting a promise which was not handled with .catch(). To terminate the node process on unhandled promise rejection, use the CLI flag `-
-unhandled-rejections=strict` (see https://nodejs.org/api/cli.html#cli_unhandled_rejections_mode). (rejection id: 1)
(node:21380) [DEP0018] DeprecationWarning: Unhandled promise rejections are deprecated. In the future, promise rejections that are not handled will terminate the Node.js process with a non-zero exit code.
问题原因
困惑许久,后面添加了一个截图方法在页面启动后,发现如下:
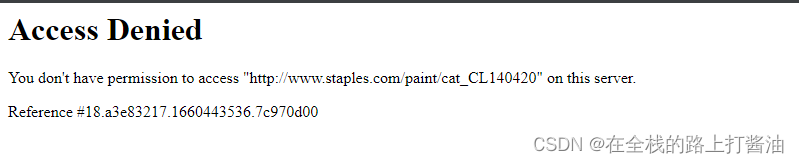
也就是说在headless为true的模式下,这个网站的反爬虫机制会禁止访问。
解决方法:
在打开页面以后,添加一个服务代理就可以解决了
await page.setUserAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36");完整代码如下:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless:true
});
const page = await browser.newPage();
await page.setUserAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36");
await page.goto('https://www.staples.com/paint/cat_CL140420');
await page.screenshot({path: 'exampl1.png'});
const bodyHandle = await page.waitForSelector("#searchTerm");
const html = await page.evaluate(body => {
return body.innerHTML;
}, bodyHandle);
console.log(html)
await browser.close();
})();这个时候就可以获取运行结果:
Painting Supplies
如果发现上述的方法还是不能够的话,那么可以再添加以下参数
await page.setExtraHTTPHeaders({
'Accept-Language': 'en-GB,en-US;q=0.9,en;q=0.8'
});还有另外一种是使用
puppeteer-extra
GitHub - berstend/puppeteer-extra: 💯 Teach puppeteer new tricks through plugins.
根据网上大神的原话
puppeteer-extra-plugin-anonymize-ua-- anonymizes your User Agent. Note that this might help with getting past headless mode detection, but as you'll see if you visit AmIUnique it is unlikely to be enough to keep you from being identified as a repeat visitor.puppeteer-extra-plugin-stealth-- this might help win the cat-and-mouse game of not being detected as headless. There are many tricks that are employed to detect headless mode, and as many tricks to evade them.
这个方法放在这里,因为需要添加插件,觉得麻烦,后面上面使用代理的方法无法解决时再考虑使用这个方法

















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









