







文章目录
需求:
如果有一串字符串,含有&#的特殊字符串,如何解决,我尝试之后,放入html页面中,使用浏览器打开是正常的。
最后搜到了一篇文章:
https://blog.csdn.net/WindyQCF/article/details/71435145
然后我就想着用HTMLParser模块,结果各种报错,最终还是解决了。
解决步骤:
1、安装HTMLParser模块:
pip install HTMLParser
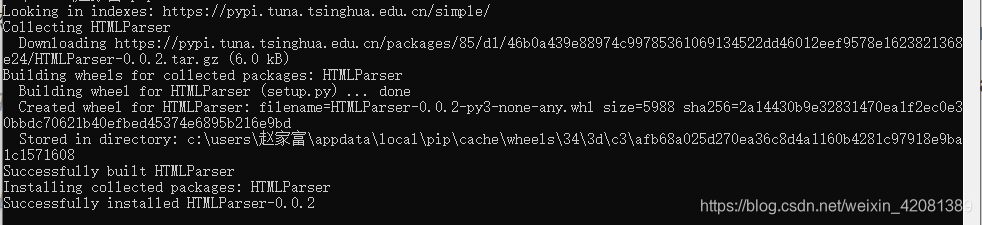
当时安装之后不能直接使用。
2、解决报错:ModuleNotFoundError: No module named ‘markupbase’
说是缺少:markupbase模块,然后搜了半天,都没有这个模块。
最后找到一个:micropython-_markupbase模块,但是安装不上,又报错。
https://pypi.org/project/micropython-_markupbase/#files
再往后,我找到一个百度步骤:
https://jingyan.baidu.com/article/48b558e3eede697f39c09a6c.html
说是把,micropython-_markupbase下载解压,然后把_markupbase.py放入到:python安装位置的,\Lib\site-packages目录下面。
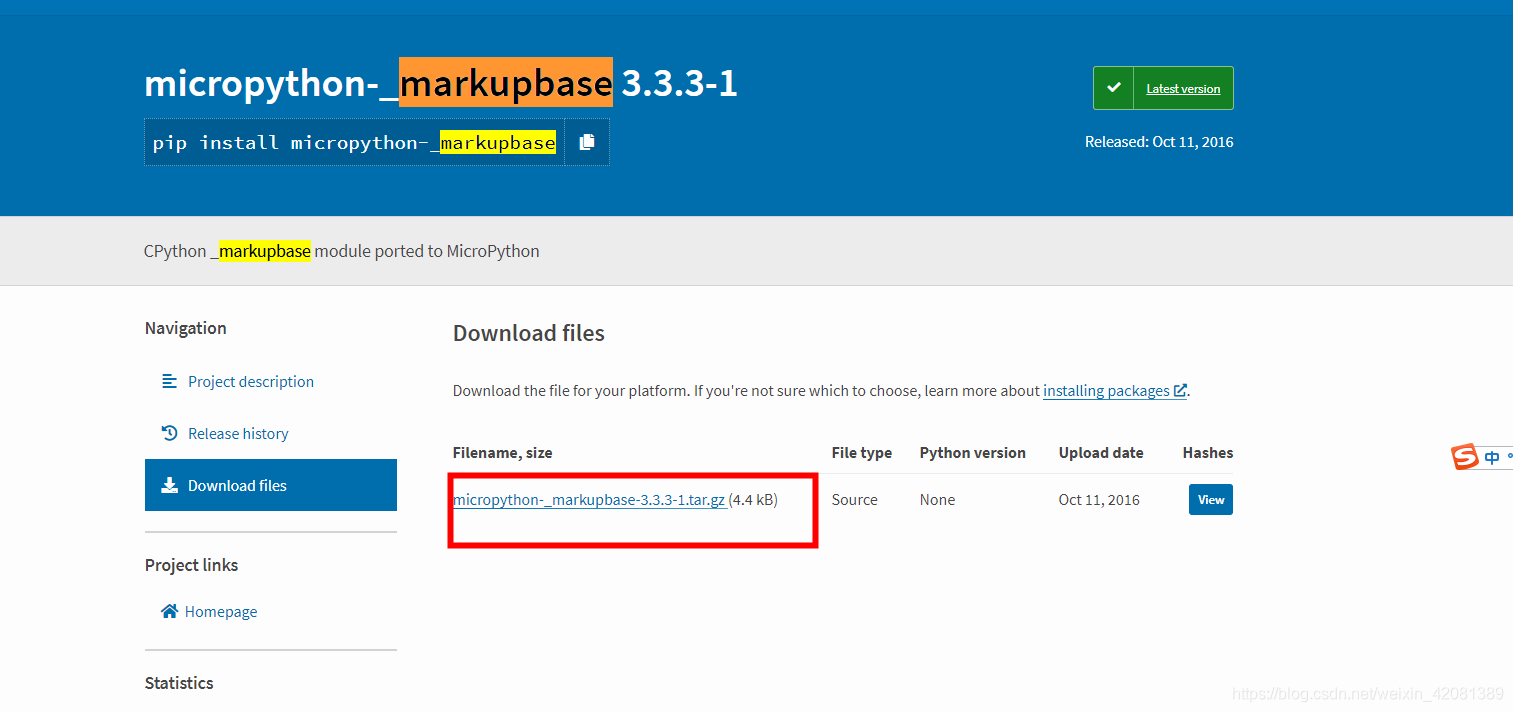
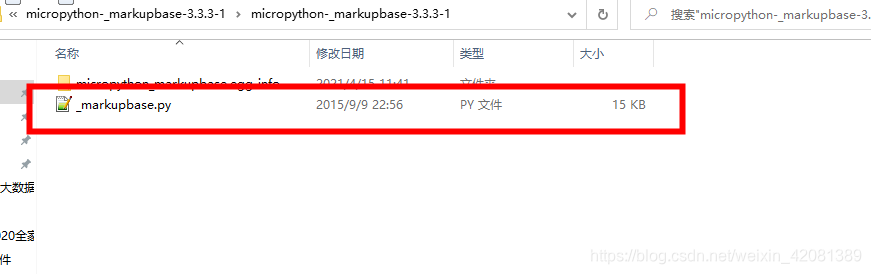
然后复制到里面还是不行,最后我想着是不是需要把_markupbase.py的_markupbase名称改为markupbase,然后就不报这个错了。
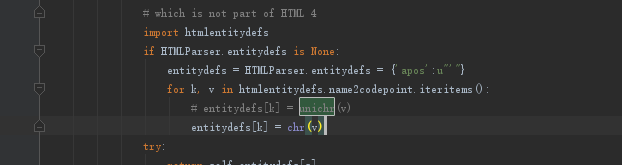
3、报unichr错误:NameError: name 'unichr' is not defined
然后找到一篇文章:
http://www.voidcn.com/article/p-wcuodcym-btb.html
意思就是python中这个方法改为了chr。
然后把报错位置的D:\python_work_tools\Python37\Lib\site-packages\HTMLParser.py
文件,中的俩处unichr,改为chr函数。
4、再次运行代码,成功。
import HTMLParser
s = '【试呼】'
h = HTMLParser.HTMLParser()
print(h.unescape(s))
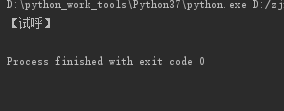
5、根据歌词需求进行一个整改:
#coding=utf-8
import HTMLParser
import re
class Replace_Unicode_str(object):
def get_set_chars(self, str_text):
list_result = re.findall('&#.*?;', str_text)
list_result = list(set(list_result))
return list_result
def extract_unicode(self,list_result):
result_json = {}
for list_one in list_result:
h = HTMLParser.HTMLParser()
value = h.unescape(list_one)
result_json[list_one] = value
return result_json
def replace_str(self, result_json,str_):
for key in result_json.keys():
val = result_json[key]
str_ = str_.replace(key,val)
return str_
def run_start(self,s):
list_result = self.get_set_chars(s)
result_json = self.extract_unicode(list_result)
s_result = self.replace_str(result_json, s)
return s_result
if __name__ == '__main__':
# import HTMLParser
#
# s = '【试呼】'
# h = HTMLParser.HTMLParser()
# print(h.unescape(s))
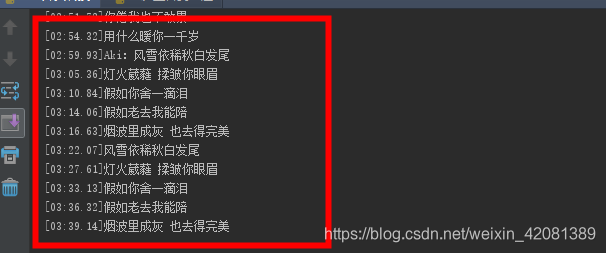
s = "[ti:牵丝戏] [ar:Aki阿杰] [al:在线热搜(华语)系列96] [by:] [offset:0] [00:00.11]牵丝戏 - 银临/Aki阿杰 [00:01.88]词:Vagary [00:02.44]曲:银临 [00:03.28] [00:24.55]银:嘲笑谁恃美扬威 [00:28.52] [00:30.16]没了心如何相配 [00:34.15] [00:34.97]盘铃声清脆 [00:37.80]帷幕间灯火幽微 [00:40.63]我和你 最天生一对 [00:45.22] [00:46.94]没了你才算原罪 [00:50.89] [00:52.59]没了心才好相配 [00:56.50] [00:57.22]你褴褛我彩绘 [00:59.93]并肩行过山与水 [01:02.80]你憔悴 我替你明媚 [01:07.74] [01:08.42]是你吻开笔墨 [01:11.35]染我眼角珠泪 [01:14.07]演离合相遇悲喜为谁 [01:18.92] [01:19.68]他们迂回误会 [01:22.47]我却只由你支配 [01:25.11]问世间哪有更完美 [01:30.26]Aki:兰花指捻红尘似水 [01:35.96]三尺红台 万事入歌吹 [01:41.62]唱别久悲不成悲 [01:44.67]十分红处竟成灰 [01:47.47]愿谁记得谁 最好的年岁 [01:53.58] [02:16.30]银:你一牵我舞如飞 [02:20.17] [02:21.82]你一引我懂进退 [02:25.86] [02:26.53]苦乐都跟随 [02:29.31]举手投足不违背 [02:32.01]将谦卑 温柔成绝对 [02:37.05] [02:37.83]你错我不肯对 [02:40.47]你懵懂我蒙昧 [02:43.23]心火怎甘心扬汤止沸 [02:48.09] [02:48.99]你枯我不曾萎 [02:51.72]你倦我也不敢累 [02:54.32]用什么暖你一千岁 [02:59.93]Aki:风雪依稀秋白发尾 [03:05.36]灯火葳蕤 揉皱你眼眉 [03:10.84]假如你舍一滴泪 [03:14.06]假如老去我能陪 [03:16.63]烟波里成灰 也去得完美 [03:22.07]风雪依稀秋白发尾 [03:27.61]灯火葳蕤 揉皱你眼眉 [03:33.13]假如你舍一滴泪 [03:36.32]假如老去我能陪 [03:39.14]烟波里成灰 也去得完美"
replac_unicode = Replace_Unicode_str()
s_result = replac_unicode.run_start(s)
print("s_result",s_result)
可以看到,想要的已经全部替换正确。


















 3205
3205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











