







import numpy as np
#激活函数
def sigmoid(x):
return 1/(1 + np.exp(-x))
#输出层时使用的‘激活函数’
def outputtype(x):
return x
#softmax函数
def softmax(a):
c = np.max(a)
exp_a = np.exp(a-c) #防止计算溢出,所以同时减去输入信号中的最大值,
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
#输入层到第一层
X = np.array([1.0, 0.5]) #输入的数据
W1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]]) #第一层的权重
B1 = np.array([0.1, 0.2, 0.3]) #第一层的偏置
A1 = np.dot(X,W1)+B1 # np.dot矩阵的乘积运算
Z1 = sigmoid(A1) #j激活函数
print(‘A1:’,A1)
print(‘Z1:’,Z1)
#第一层到第二层
W2 = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
B2 = np.array([0.1, 0.2])
A2 = np.dot(Z1,W2)+B2
Z2 = sigmoid(A2)
print(np.dot(X,W1))
print(‘A2:’,A2)
print(‘Z2:’,Z2)
#第二层到输出层
W3 = np.array([[0.1, 0.3],[0.2, 0.4]])
B3 = np.array([0.1,0.2])
A3 = np.dot(Z2,W3)+B3
Y = outputtype(A3) #输出层时使用的‘激活函数’
Y = np.argmax(A3) #返回numpy列表中最大值的下标
print(‘A3:’,A3)
print(A3.max())
print(Y)
运行代码输出:
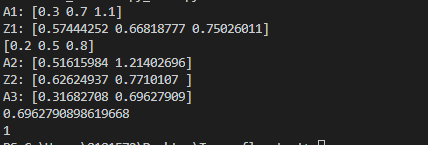
关于输出层使用的激活函数说明
输出层所使用的激活函数,要根据求解问题的性质决定。一般而言,
1、回归问题可以使用恒等函数作为激活函数(如上述自定义的outputtype函数)
2、二元分类问题可以使用sigmoid函数作为激活函数
def sigmoid(x):
return 1/(1 + np.exp(-x))

3、多元分类问题可以使用softmax函数作为激活函数。
def softmax(a):
c = np.max(a) #防止计算溢出,所以同时减去输入信号中的最大值,
#同时加上或减去一个常数并不会影响结果。
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
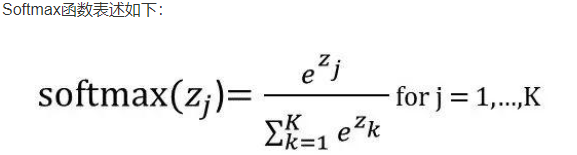















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









