







1.统计学分为监督学习,非监督学习,半监督学习和强化学习
2.方法=模型+决策+算法
3.输入变量与输出变量均为连续变量的称为回归问题;输出变量为有限个离散量的称为分类问题;输入输出均为变量序列的称为标注问题
4.概率分布函数与决策函数描述输入与输出间的映射关系
5.损失函数
损失函数度量一次模型预测的好坏
 |
6.风险函数度量平均意义下预测模型的好坏
损失函数与联合分布函数的积分即为风险函数
风险函数也称为期望损失
7.模型关于训练数据集的平均损失称为经验风险或经验损失
8.期望风险是模型关于联合分布的期望损失,经验风险是模型关于训练样本集的平均损失,当样本数量趋于无穷时,期望风险等于 经验风险
9.结构风险=经验风险+复杂度
10.监督学习即为经验风险或者结构风险的最优化问题,此时经验或结构函数是最优化的目标函数
11.当损失函数给定时,基于损失函数的模型的训练误差和模型的测试误差即为学习方法评估的标准
12.过拟合指选定的模型过于复杂,对已知数据的预测很准确但对未知数据的预测不准确
13.随着模型趋于复杂,训练误差趋于0,测试误差先减小后增大
14.正则化即为期望风险函数最优化
15.在所有可能的模型中,能很好地解释已知数据的最简单的模型就是应该选择的模型
16.交叉验证中,训练集用来训练模型,验证集用于对模型的选择,测试集用于最终对学习方法的评估
- 简单交叉验证
随机将数据分为训练集和测试集
- n 折交叉验证
随机分成 n 个互不相交的子集,然后利用n-1个子集的数据训练模型,利用余下的子集测试模型
- 留一交叉验证
即 n = N 的情况
17.学习方法的泛化能力是指由该方法学习到的模型对未知数据的预测能力,是学习方法本质上重要的性质
18.泛化误差上界是样本容量的函数,当样本容量增加时,趋近于0;它是假设空间容量的函数,假设空间容量越大,泛化误差上界 就越大
19.泛化误差小于等于经验风险加上关于N的单调递减函数,其中后者即为误差泛化上界;训练误差越小样本数量越大,泛化误差上界越小
20.分类准确率定义为对于给定的数据测试集、分类器正确分类的样本数为总样本数之比,也就是损失函数为0-1损失时测试数据集上 的准确率
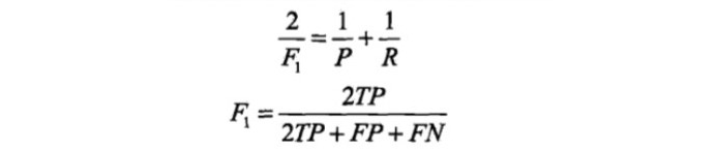
21.二类分类常用的评价指标是精准率与召回率,通常以关注的类为正类,其余的类为负类,以下为四种情况:
 |
精准率定义为正类正类数除以正类正类数与负类正类数之和
召回率定义为正类正类数除以正类总数
此外还有精确率为召回率的调和函数
 |















 731
731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









