









背景
我们前面一直在写处理程序、sql去处理数据,大家都知道我们要处理和分析的数据是存在hdfs分布式文件存储系统当中的
但这些数据并不是一开始就存储在hdfs当中的,有些数据在业务系统的机器上,有些数据在日志系统的机器上
这就要求我们能够将数据从业务系统的机器上给收集过来,而且后面我们实践后续项目时也要求能够对数据进行采集(不然数据从哪来?)
比如说我们需要分析用户的行为习惯,通过分析了解用户的喜好等,从而为公司的运营指导方向,对用户进行精准投放广告或者推荐,提高公司产品的转化率
再或者通过用户的行为 来优化公司内部产品的研发
那需要分析用户的行为习惯,用户产生的行为,肯定是某个动作,某个行为,触发,比如用户在提交订单这个步骤上停留的时间非常长
这些用户的行为,肯定来源于业务系统,那数据肯定存储在业务系统的服务器上
我们不可能直接自己在服务器上写个java程序,请求hdfs客户端,采集日志数据完之后,再上传到hdfs上,一来我们不能保证程序的健壮性
比如程序崩了怎么办?数据传输安全吗?数据丢失了怎么办?二来,我们自己写太麻烦了
这就用到了分布式数据采集工具----------flume
特点
1)高可用(级联模式下,一台下游agent崩掉之后,可以立即切换另外一台agent使用)
2)分布式(可以在多台服务器上采集数据),可以采集文件,socket数据包(网络端口)、文件夹、kafka、mysql数据库等各种形式源数据
3)可存储、汇聚到大数据生态的各种存储系统中(hdfs、hbase、hive、kafka)可以将采集到的数据(下沉sink)输出到HDFS、hbase、hive、kafka等众多外部存储系统中
4)配置简单,开箱即用!一般的采集、传输需求,通过对flume的简单配置即可实现;不用开发一行代码!
5)良好的扩展功能,Flume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以适用于大部分的日常数据采集场景
业务系统-日志服务器集群-日志采集-示意图如下:
小知识点:埋点
我们知道,用户行为的记录,肯定是用户自己做了某种行为之后,才会记录下来。那么怎么记录,又记录在哪呢?
举个例子,web项目,用户通过淘宝购物,点击购物车,触发了网页html中js设置的程序代码,这个就叫埋点代码
触发之后,代码将向服务器端进行请求,服务器端将用户行为,通过打日志或者其他方式记录到本地磁盘中

核心概念
1)agent
Flume中最核心的角色是agent,flume采集系统就是由一个个agent连接起来所形成的一个或简单或复杂的数据传输通道。
对于每一个Agent来说,它就是一个独立的守护进程(JVM),它负责从数据源接收数据,并发往下一个目的地,如下图所示:
Agent的3个组件的设计思想,主要考虑的是:
source和sink之间解耦合,以及异步操作;
每一个agent相当于一个数据(被封装成Event对象)传递员,内部有3个核心组件:
- Source:采集组件,用于跟数据源对接,以获取数据;它有各种各样的内置实现;
- Sink:下沉组件,用于往下一级agent传递数据或者向最终存储系统传递数据
- Channel:传输通道组件,用于从source将数据传递到sink
2)Event
数据在channel中的封装形式;
Source组件在获取到原始数据后,需要封装成Event放入channel;
Sink组件从channel中取出Event后,需要根据目标存储的需求,转成其他形式的数据输出
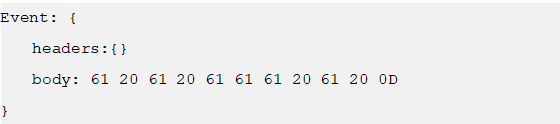
Event封装对象主要有两部分组成: Headers和 Body
header是一个集合 Map[String,String],用于携带一些KV形式的元数据(标志、描述等)
body: 就是一个字节数组byte[];装载具体的数据内容
3)interceptor 拦截器
拦截器,就是为用户提供添加数据处理逻辑的可能性
拦截器工作在source组件之后,source产生的event会被传入拦截器根据需要进行拦截处理
而且,拦截器可以组成拦截器链!
拦截器在flume中有一些内置的功能比较常用的拦截器
用户也可以根据自己的数据处理需求,自己开发自定义拦截器!
这也是flume的一个可以用来自定义扩展的接口!
4)级联串联(一般下游agent会使用高可用模式,有一个处于待机或者未工作状态)
4)事务机制
数据传输的三个语义:
- At least once 至少传输数据完整一次(不会丢失数据,但可能产生重复传输)
- At most once 至多传输数据完整一次(可能一次都不会成功,可能会丢失数据)
- Exactly once 数据不丢失且不重复 实现完美传输
Flume并没有实现Exactly once!但可以实现at least once! 因为Exactly once确实比较难实现!
Flume使用两个独立的事务:
- put操作:source读取数据源并写入event到channel
- take操作:sink从channel中获取event并写出到目标存储
事务实现的核心点是:记录状态!
比如source,会记录自己完成拉取成功数据的偏移量
另外还有些其他的概念,以后碰到了再说,这里不再赘述。



安装配置
flume的安装贼简单,只需要导个包,配置些文件即可!
1)解压
将flume的安装包上传到linux01上之后,解压到/opt/apps下面
2)写配置文件
接下来我们通过案例,一边配置一边实践

案例实践
需求:
现在需要对服务器磁盘某个文件下的数据进行采集,数据是用户的行为数据,数据中含有时间,采集完成之后,我需要按照时间,具体到天为单位文件夹存放在hdfs中
思考:
1)因为flume的agent从用户触发时间开始到收集----存入channel-----由sink读出来下沉到hdfs中,这个过程肯定有时间延迟,假如某个用户某次行为触发事件的时间为2021-1-8 23:59:59 ,而存入hdfs端的时间也是用的本机服务器的时间的话,很明显,按照天单位文件夹存,它就存到1月9号去了,是不可行的,所以我们得记录用户触发事件的时间,最好是连带着用户的行为中,一起被收集到source中
2)既然时间是在用户行为数据当中,那么我们可以设置拦截器,对数据进行提取,分析,再存入到event的header中(不能存入body中,因为目标数据具体是什么格式的,我们并不知道,但是header是一个hashmap),因为flume自己提供的拦截器 并没有能完成我们这种需求的,所以需要自定义拦截器
先来写拦截器:
新建maven代码,导入flume依赖包,自定义拦截器,继承flume的interceptor
代码如下:
package cn.study.demo01; import org.apache.flume.Context; import org.apache.flume.Event; import org.apache.flume.interceptor.Interceptor; import java.util.List; /** * @author:tom * @Date:Created in 16:15 2021/1/8 */ public class EventStampInterceptor implements Interceptor { String split_by; Integer ts_index; public EventStampInterceptor(String split_by, Integer ts_index) { this.split_by = split_by; this.ts_index = ts_index; } /** * 初始化方法,在正式调用拦截逻辑之前,会先调用一次 */ public void initialize() { } /** * 拦截的处理逻辑所在方法 * 假设,我们要采集的数据,格式如下: * id,name,timestamp,devicetype,event */ public Event intercept(Event event) { byte[] body = event.getBody(); String line = new String(body); String timeStamp = line.split(split_by)[ts_index]; event.getHeaders().put("timestamp", timeStamp); return event; } public List<Event> intercept(List<Event> list) { for (Event event : list) { intercept(event); } return list; } /** * 关闭清理方法,在销毁该拦截器实例之前,会调用一次 */ public void close() { } //builder 构建自定义拦截器对象的 public static class EventStampInterceptorBuilder implements Interceptor.Builder { String split_by; Integer ts_index; public Interceptor build() { return new EventStampInterceptor(split_by, ts_index); } //可以获取到配置文件中的对象 public void configure(Context context) { split_by = context.getString("split_by"); ts_index = context.getInteger("ts_index", 2); } } }采用级联模式,使用三台linux作为agent,其中linux03作为下游agent,linux01和linux02作为上游agent
下游linux03的配置文件:
a1.sources = r1
a1.channels = c1
a1.sinks = k1a1.sources.r1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41414a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 200
a1.sinks.k1.channel = c1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://linux01:8020/doit19_0108/%Y-%m-%d/
a1.sinks.k1.hdfs.filePrefix = DoitEduData
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.rollInterval = 60
a1.sinks.k1.hdfs.rollSize = 268435456
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.batchSize = 100
a1.sinks.k1.hdfs.useLocalTimeStamp = false
上游linux01的配置文件:
a1.sources = r1
a1.channels = c1
a1.sinks = k1a1.sources.r1.channels = c1
a1.sources.r1.type = TAILDIR
a1.sources.r1.batchSize = 100
a1.sources.r1.filegroups = g1
a1.sources.r1.filegroups.g1 = /home/a.log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = cn.study.demo01.EventStampInterceptor$EventStampInterceptorBuilder
a1.sources.r1.interceptors.i1.split_by = ,
a1.sources.r1.interceptors.i1.ts_index = 2a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 200a1.sinks.k1.channel = c1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = linux03
a1.sinks.k1.port = 41414
a1.sinks.k1.batch-size = 100
上游linux02的配置文件:
a1.sources = r1
a1.channels = c1
a1.sinks = k1a1.sources.r1.channels = c1
a1.sources.r1.type =TAILDIR
a1.sources.r1.filegroups = g1
a1.sources.r1.filegroups.g1 = /home/a.log
a1.sources.r1.batchSize = 100
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = cn.study.demo01.EventStampInterceptor$EventStampInterceptorBuilder
a1.sources.r1.interceptors.i1.split_by = ,
a1.sources.r1.interceptors.i1.ts_index = 2
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 200a1.sinks.k1.channel = c1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = linux03
a1.sinks.k1.port = 41414
a1.sinks.k1.batch-size = 100
为了制造新产生的数据,我写了个脚本,并输出到/home/a.log 中
先执行脚本,使其不断产生数据
启动下游agent
linux03:bin/flume-ng agent -c conf/ -f myagentconf/exec-m-hdfs-xiayou.conf -n a1 -Dflume.root.logger=INFO,console
启动上游两个agent
linux02:
bin/flume-ng agent -c conf/ -f myagentconf/exec-m-shangyou.conf -n a1 -Dflume.root.logger=INFO,console
linux01:
bin/flume-ng agent -c conf/ -f agent.conf/exec-m-shangyou.conf -n a1 -Dflume.root.logger=INFO,console
可以看到,成功采集并才hdfs上分好了文件夹,和存入了相应的数据









注意点:
1)上游两个采集数据的agent的type使用的是TAILDIR 而不是exec ,因为TAILDIR 会记录已经采集数据的偏移量,能保证数据不丢失,一般我们使用的也是这个TAILDIR ,但是记得要指定filegroups
2) 必须要先启动下游的linux03,因为linux03作为下游服务器端agent,是接收上游客户端nagent的数据请求,通过网络将上游的数据拉取过来,必须先启动下游,才能启动上游的agent,下游的agent通过监听启动服务的端口号,看是否有数据sink(上游agent的sink)传输过来,进而进行工作,上游agent的sink需要指定端口号,即下游agent 启动之后的resoure的端口号
3)上游的agent的sink端口号为下游agent的source的端口号;上游agent的sink的type和下游的source的type都为avro,这是一种跨平台、跨语言的序列化方式
4)上游agent的sink 主机名记得写linux03,写错了几次
5)linux02和linux03要配置hadoop的环境变量
6)配置文件,粘贴的时候,要提前按i或者o进入插入模式,否则将消耗粘贴内容中的关键字
更多学习、面试资料尽在微信公众号:Hadoop大数据开发















 1453
1453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









