










首先很感谢大家的垂爱,从当初收回学校运营的这个公众号到后面自己专注于大数据技术公众号,也快一年了,不知不觉粉丝的个数已经从当初的两三百到千级别了,其实一直没怎么精心去运营,只想着权当把微信公众号这个平台当做树洞,当做日记,来分享自己的一次次学习,一次次跳坑,一次次成长。一路走来,有人离开,有人陪伴,虽然我身体上是孤独的,但是精神上却一直是充实的,没有大号主的扶持、没有精心的运营、没有软文式的广告,只想默默跟大家一起学习,目前只有大成子也就是号主本人一直在运营,如果有志同道合的同鞋想一起学习,平常也愿意分享分享自己的学习,可以私信我。

好久都没碰kafka了,为了项目系列的学习,我打算全部 弄一遍组件,所以需要重装一下kafka。
在重装kafka之前,需要预删除一些东西
大数据生态分布式组件,既然涉及到了分布式,在信息和技术更新迭代如此之快的这个时代里,肯定不是单打独斗,独立存在的,kafka里面就涉及到了管理者(工地头子)【如下图】

预删除zookeeper里面的如下组件
登录zookeeper的cli,使用rmr path 命令删除以下节点信息即可
rmr path 删除此节点及其子文件夹信息
cluster:kafka集群信息
config:配置信息
consumer:消费者信息
producer:生产者信息
brokers :集群几点信息,topic信息
admin:删除的topic
controller:控制节点的broker.id
controller_epoch:集群经过了多少次controller选取
isr_change_notification
latest_producer_id_block
在kafka的安装目录下,进入cli控制行:

查看所有的节点:

删除关于kafka的所有节点:

在其他节点机器 登录 查看是否已经删除成功:


预删除掉kafka的数据存储文件夹
可以去到kafka的配置文件里面查看当时安装kafka时所配置的数据存储目录:

vi 配置文件:
/log 搜索,kafka中的数据是以日志形式存储的,按n查询匹配下一个
 查询到当时所配的数据存储目录在/opt/kafkaData,可以看到该目录还是有很多文件的
查询到当时所配的数据存储目录在/opt/kafkaData,可以看到该目录还是有很多文件的

删除掉所有机器上的此目录下的所有数据



删除kafka安装目录



去镜像网站上下载安装包

解压到app目录
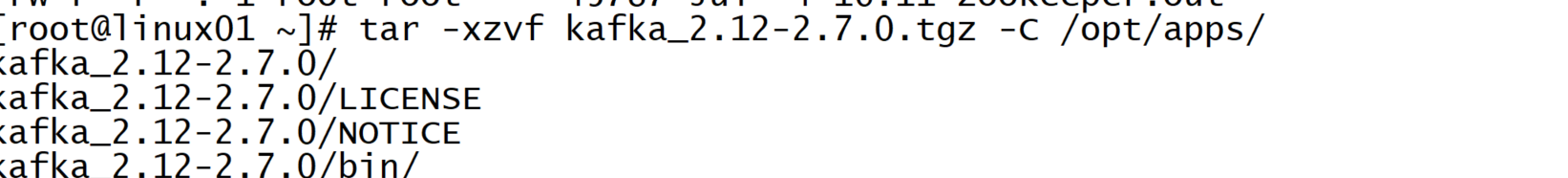

接下来,就是配置kafka集群了
vi config下的server.properties
步骤:
配置以下东西
- broker的id
- 数据存储的目录
- 指定zookeeper的位置
- 数据的过期时间
它只要求独一无二的id即可,linux分配1

数据存储位置

指定zookeeper的位置

设置数据存储有效时间
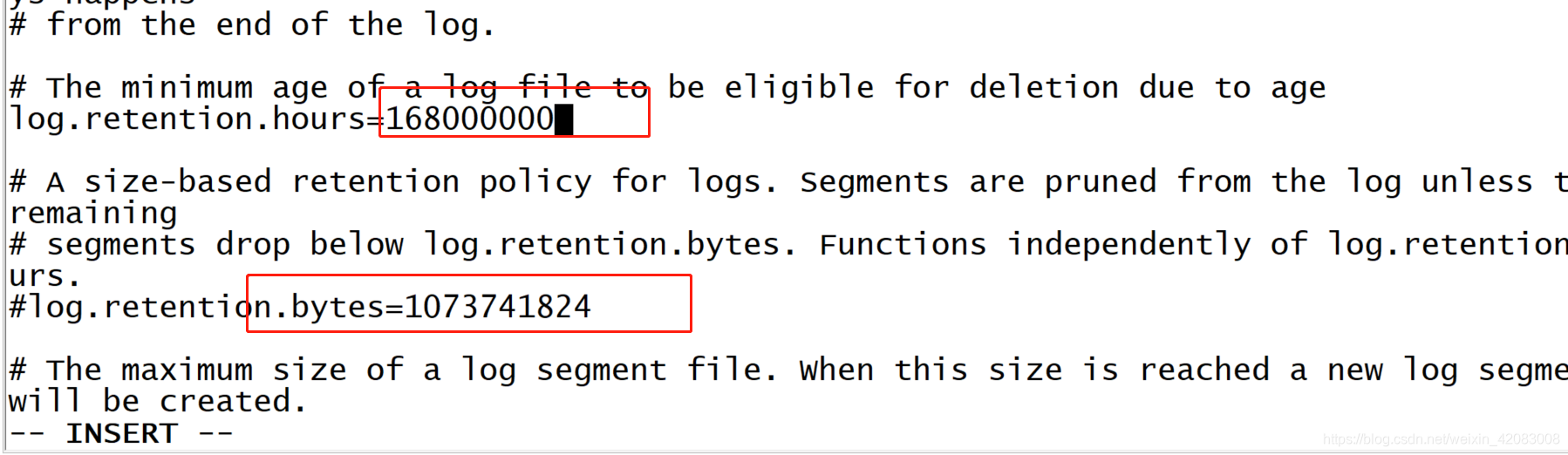
为了后面项目实践,我刻意将数据的有效期设置了很长时间,(kafka默认数据存放时间为7天即168个小时)当满足上图中任一条件,数据将会被删除。
将配置好的kafka分发给其他机器




修改linux02和linux03上的borkerid


写一个启动脚本,用于一键启动kafka服务。

# !/bin/bash
arg=$1
if [ $arg="start" ]
then
for hostname in linux01 linux02 linux03
do
ssh $hostname "source /etc/profile;/opt/apps/kafka_2.12-2.7.0/bin/kafka-server-start.sh -daemon /opt/apps/kafka_2.12-2.7.0/config/server.properties;exit"
done
else
for hostname in linux01 linux02 linux03
do
ssh $hostname "source /etc/profile;/opt/apps/kafka_2.12-2.7.0/bin/kafka-server-stop.sh -daemon /opt/apps/kafka_2.12-2.7.0/config/server.properties;exit"
done
fi



成功启动三台机器的kafka!
下面试验一下集群的正常性,在linux01上创建一个名为test的topic,分别在linux02和linux03上查看是否存在。
./kafka-topics.sh --zookeeper linux01:2181,linux02:2181,linux03:2181 --create --topic test --replication-factor 2 --partitions 6

分别在linux02和linux03上查看topic


至此,验证结束,kafka集群重装完成!















 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









