








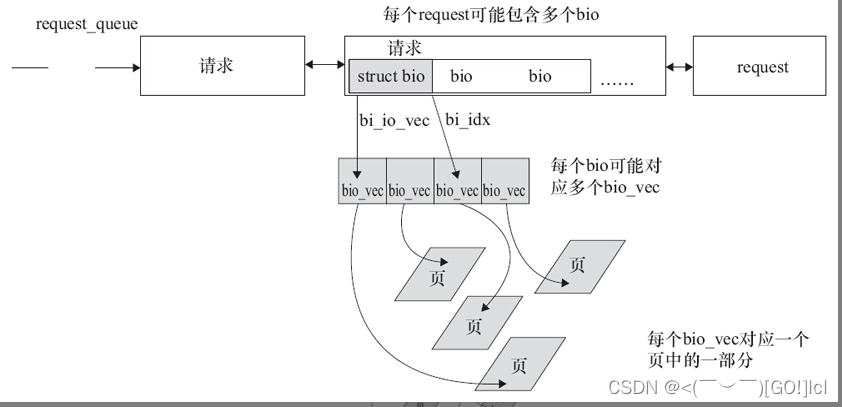
通常一个bio对应上层传递给块层的I/O请求;每个bio结构体实例及其包含的bvec_iter、bio_vec结构体实例描述了该I/O请求的开始扇区、数据方向(读还是写),数据放入的页,
其定义如代码清单13.3所示。
struct bvec_iter
{
sector_t bi_sector;
unsigned int bi_size;
unsigned int bi_idx;
unsigned int bi_bvec_done;
}
struct bio
{
struct bio *bi_next;
struct block_device *bi_bdev;
unsigned long bi_flags;
unsigned long bi_rw;
......
struct bvec_iter bi_iter;
struct bio_vec *bi_io_vec;
struct bio_set *bi_pool;
struct bio_vec bi_inline_vecs[0];
}
与bio对应的数据每次存放的内存不一定是连续的,bio_vec结构体用来描述与这个bio请求对应的所有的内存,他可能不总是在一个页面里面,因此需要一个向量。向量中的每个元素实际是一个[page,offset,len],我们称它为一个片段。
struct bio_vec
{
struct page *bv_page;
unsigned int bv_len;
unsigned int bv_offset;
}
I/O调度算法可将连续的bio合并成一个请求,请求是bio经由I/O调度进行调整后的结果,这是请求和bio的区别。因此,一个request(请求)可以包含多个bio,当bio被提交给I/O调度器时,I/O调度器可能会将这个bio插入现存的请求中,也可能生成新的请求。
每个块设备或者块设备分区都对应有自己的request_queue,从I/O调度器合并和排序出来的请求会被分发(Dispatch)到设备级的request_queue。
下面看一下驱动中涉及到处理bio,request和request_queue的主要API。
(1)初始化请求队列
request_queue_t *blk_init_queue(request_fn_proc *rfn,spinlock_t *lock);
第一个参数是请求处理函数的指针,
第二个参数是控制访问队列权限的自旋锁,
这个函数会发生内存分配的行为,他可能会失败,因此一定要检查他的返回值。这个函数一般在块设备的初始化过程中调用。
(2)清除请求队列
void blk_cleanup_queue(request_queue_t *q);
这个函数完成请求队列返回给系统的任务,一般在块设备驱动卸载过程中调用。
(3)分配请求队列
request_queue_t *blk_alloc_queue(int gfp_mask);
对于RAMDISK这种完全随机访问的非机械设备,并不需要复杂的I/O调度,这个时候可以直接踢开I/O调度器,使用如下函数来绑定请求队列和制造请求函数(make_request_fn)。
void blk_queue_make_request(request_queue_t *q,make_request_fn *mfn);
blk_alloc_queue()和blk_queue_make_request()结合起来使用的逻辑一般是:
xxx_queue = blk_alloc_queue(GFP_KERNEL);
blk_queue_make_request(xxx_queue,xxx_make_request);
(4)提取请求
struct request *blk_peek_request(struct request_queue *q);
上述函数用于返回下一个要处理的请求(由I/O调度器决定),如果没有请求则返回NULL。他不会清除请求,而是仍然将这个请求保留在队列上。原先的老的函数elv_next_request()已经不再存在。
(5)启动请求
void blk_start_request(struct request *req);
从请求队列中移除请求,原先的老的API blkdev_dequeue_request()会在blk_start_request()内部被调用。
我们可以考虑使用blk_fetch_request()函数,他同时做完了blk_peek_request()(提取请求)和blk_start_request()的工作。
struct request *blk_fetch_request(struct request_queue *q)
{
struct request *rq;
rq = blk_peek_request(q);
if(rq)
{
blk_start_request(rq);
}
return rq;
}
(6)遍历bio和片段
_rq_for_each_bio()遍历一个请求的所有bio。
#define _rq_for_each_bio(_bio,rq) \
if(rq->bio)
{
for(_bio = rq->bio;_bio;_bio=_bio->bi_next);
}
bio_for_each_segment()遍历一个bio的所有bio_vec。
rq_for_each_segment()迭代遍历一个请求所有bio所有segment。
(7)报告完成
void _blk_end_request_all(struct request *rq,int error);
void blk_end_request_all(struct request *rq,int error);
若我们用blk_queue_make_request()绕开I/O调度,但是在bio处理完成后应该使用bio_endio()函数通知处理结束:
#define bio_io_error(bio) bio_endio((bio),-EIO);

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











