






在本文中,我们描述了这两种基于分类器的组级解码策略与人工和真实fMRI数据集所提供结果的比较。
。第2节介绍了我们的方法,包括针对两个小组级策略的多元分析管道,以及对真实数据集和人工数据集生成模型的描述。第三部分包括定性和定量两种方法对这两种数据获得的结果的比较。
数据在训练集和测试集之间分配,在训练集上学习分类器,并在测试集上评估其泛化性能(通常以分类准确性衡量)。如果结果证明该准确性高于偶然水平,则意味着该算法已识别出数据中的特征组合,以区分与不同实验条件相关的功能模式。换句话说,这表明输入模式包含有关当该对象执行已解码的不同任务时招募的认知过程的信息。然后可以将解码精度用作可用信息量的估计–精度越高,模式越可区分,信息量就越大。
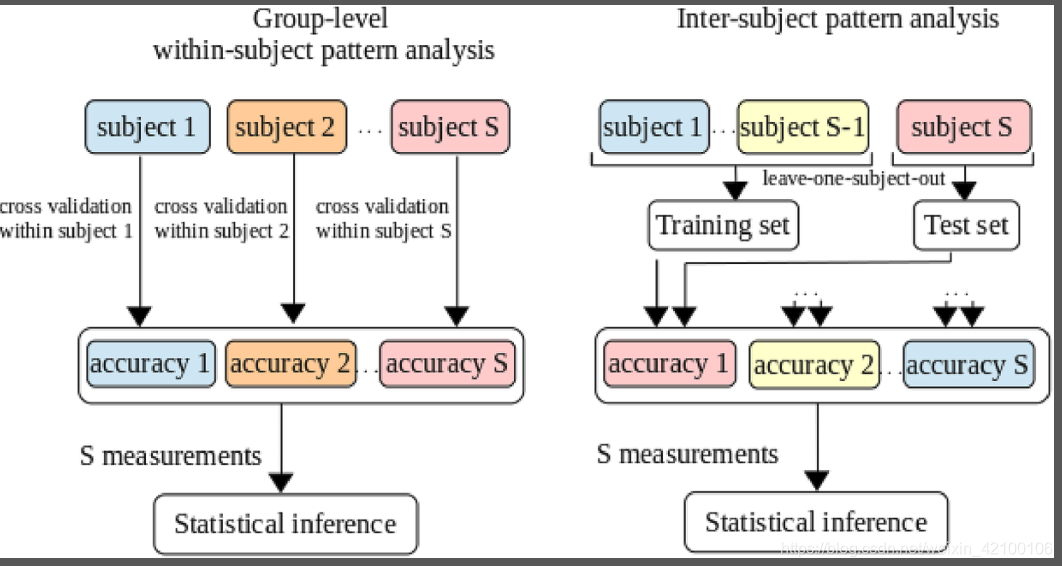

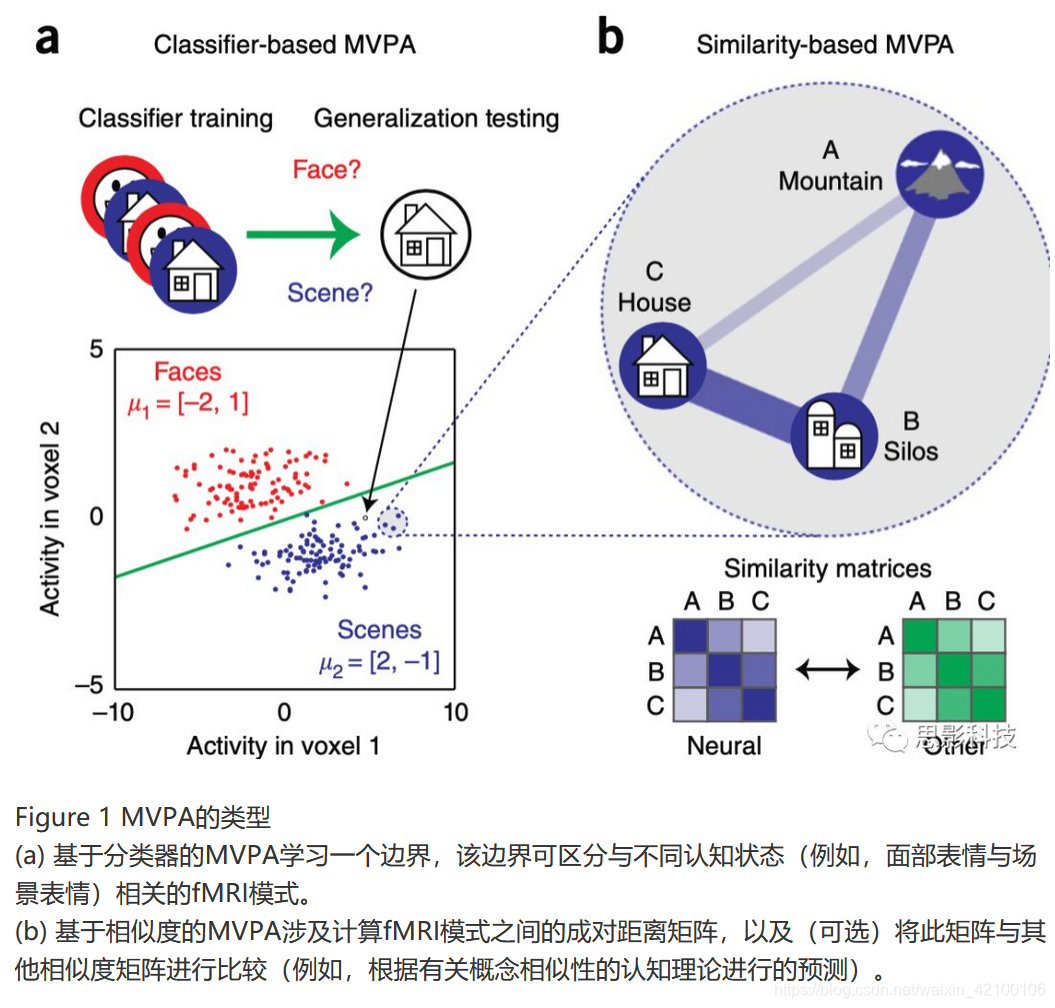
一直困扰我的问题是,MVPA划分的是大脑的功能模式,即所有特征体素一起的活动模式 ,而不是仅仅将体素进行功能活动的分类?
对于Dataset1,解码任务是猜测参与者在试验期间是否使用了他的左手或右手拇指来回答与提供给分类器的激活模式相对应的问题。对于G-MVPA,受试者内部交叉验证遵循“离开两次会话”方案。对于Dataset2,二进制分类任务包括解密呈现给参与者的声音是有声还是无声。对于G-MVPA,因为只有一个会话可用,所以我们使用了8倍交叉验
把什么作为特征值
分解问题
(1)什么是searchlight analysis?
https://nilearn.github.io/decoding/searchlight.html
searchlight decoding
探照灯分析是在基于信息的功能性大脑映射中引入的(Kriegeskorte等,2006),包括用探照灯扫描大脑。简而言之,在大脑体积上扫描给定半径的球,并测量在相应体素上训练的分类器的预测准确性。
探照灯也不限于分类。回归(如 Kahnt等,2011)和代表性相似性分析(如Clarke和Tyler,2014)是探照灯的其他用途。当前,nilearn仅支持分类和回归。
默认情况下,默认使用的分类器SearchLight是C = 1的LinearSVC,但是可以通过将estimator参数传递给Searchlight轻松地对其进行自定义。
**SearchLight将迭代体积并为每个体素给出一个分数(score function )。**通过在所选体素上运行分类器来计算该分数。为了使该分数尽可能准确(并避免过度拟合),使用了交叉验证。
可以使用“ cv”参数定义交叉验证。由于计算量大,因此将K = 3的K -Fold交叉验证设置为默认值。甲scikit学习交叉验证发生器也可以被传递到设置交叉验证的特定类型。
留一用完的交叉验证(LOROCV)是探照灯的一种常用方法。这种方法是分组交叉验证的特定用例,其中交叉验证的倍数由采集运行确定。交叉验证的给定迭代中保留的折痕由来自单独运行的数据组成,这使训练和验证集正确独立。因此,通常建议使用LOROCV。这可以通过使用LeaveOneGroupOut来执行,然后在拟合估算器时设置组/运行标签。
分类评分函数 score function
每个体素一个特征—通用线性模型a general linear model
每个体素有二维特征:用多元线性回归–multiple linear regression **
当执行全脑分析时,执行的测试数量通常很大(> 50,000体素)。这增加了偶然发现显着激活的可能性,这种现象被统计学家称为多重比较问题。因此,建议考虑多个测试来校正p值**。Bonferroni校正包括将p值乘以测试次数(同时确保p值保持小于1)
思考
目前研究的MVPA都是将所有体素的有个变量作为特征,所有受试者的所有观察次数的体素的这个值作为所有的特征值,进行预测或者分类----我认为这属于ISPA
G-MVPA比较少见,每个人单独作为数据集,进行回归或者分类
预测的,可以根据探测灯分析在不同球状区域体素内的score 进行分析。
但是对于分类,是对个体的行为分类,不是对体素!
个人认为这篇文章的G-MVPA是新的算法,ISPA是广泛使用的MVPA形式。
ISPA可解释性:
使用ISPA检测到的显著effect意味着某些信息在整个人群中是一致的。更详细地讲,这意味着根据作为解码分析目标的实验条件的多元模式的调制在整个种群中是一致的。
conclusion
本文比较了两种策略,这些策略允许对基于任务的功能性神经影像实验进行基于group级解码的多元模式分析:第一种是将个体内解码结果进行汇总的标准方法,第二种是直接寻求在个体间方案中在组级别解码神经模式。两种策略都显示出有效,但是它们只能提供部分一致的结果。个体间模式分析提供了更高的检测能力,可以检测出较弱的分布效应并有助于解释,而基于信息的方法所提供的结果则有必要进行进一步的研究以提高潜在的歧义性。此外,由于它允许从功能性神经影像学模式中识别成组不变式,因此受试者间模式分析(ISPA)是识别神经标志物的一种选择工具。 (2015)或大脑签名Kragel等。 (2018年),使其成为用于人口方面多元分析的通用方案。
回归可以认为是预测、拟合等等
Mumford 2012
关于GLM 的β map
abstract
在任务执行过程中使用多体素模式分析(MVPA)来预测受试者的认知状态已成为fMRI研究的重点。这些分析的输入由对应于不同任务或刺激类型的激活模式组成。这些激活模式对于封闭试验或与慢事件相关的设计而言,计算起来非常简单,但对于快速事件相关的设计,相邻试验的诱发BOLD信号会在时间上重叠,从而使特定试验所特有的信号识别变得复杂。快速事件相关的设计通常是首选的,因为它们允许呈现更多的刺激并且受试者倾向于更加专注于任务,因此能够在MVPA分析中使用这些类型的设计将是有益的。本工作比较了8种不同的模型,以估计随事件间隔和信噪比而变化的一系列快速事件相关设计的逐次尝试激活模式。最有效的方法是通过一个通用线性模型来获得每个试验的估算值,该线性模型包括该试验的回归变量以及所有其他试验的另一个回归变量。通过对模拟数据和真实数据的分析,我们发现该模型相对于获取激活模式的标准方法显示出一些改进。最终的逐次试验估算值更能代表真实的激活幅度,从而在信噪比较高的快速事件相关设计中提高了分类精度。这为功能磁共振成像研究提供了潜力,可以同时优化单变量和MVPA方法。
introduction
在任务执行过程中使用多体素模式分析(MVPA)来预测受试者的认知状态已成为功能性MRI研究的重点(Mur等,2009)。通常,这些分析尝试使用BOLD fMRI图像对获取这些图像时遇到的任务或刺激条件进行分类。例如,Haxby等 (2001)使用分类器基于激活模式与一组已知对象类别的独立扫描运行的相似性来识别对象正在查看的八个对象类别中的哪一个(例如,面孔,房屋)。这些激活模式对于随时间推移被阻塞或间隔开的试验(即与慢事件相关的设计)进行估算非常简单,但是对于与快速事件相关的设计,**附近试验的BOLD信号会在时间上重叠,**从而确定具体试验所特有的信号要困难得多。寻找一种模型来准确估计特定于试验的信号以进行更快的事件相关设计,将为针对MVPA或代表性相似性分析的研究提供更大的灵活性.
分类研究问题:
(1)特征选择上,或减少分类分析中使用的体素集以提高分类准确性(Chen等,2006; De Martino等,2008; Mourao-Miranda等,2006)
(2)选取性能不同的分类模型(Carlson等,2003; Cox和Savoy,2003; LaConte等,2005; Misaki等,2010)
(3)比较了使用不同类型的激活估计(例如,使用BOLD信号的幅度与t统计量的比较以及对数据进行标准化的不同策略)在分类准确性方面的优势(Misaki等,2010)
共线性
共线性,即同线性或同线型。统计学中,*共线性即多重共线性*。
多重共线性(Multicollinearity)是*指线性回归模型中的解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。*
一般来说,由于经济数据的限制使得模型设计不当,导致设计矩阵中解释变量间存在普遍的相关关系。完全共线性的情况并不多见,一般出现的是在一定程度上的共线性,即近似共线性。
影响:
太多相关度很高的特征并没有提供太多的信息量,并没有提高数据可以达到的上限,相反,数据集拥有更多的特征意味着更容易收到噪声的影响,更容易收到特征偏移的影响等等,简单举个例子,N个特征全都不受到到内在或者外在因素干扰的概率为k,则2N个特征全部不受到内在或外在因素干扰的概率必然远小于k。这个问题实际上对于各类算法都存在着一定的不良影响;
brain decoding
超详细MVPA 讲解及实例:
(1)https://nilearn.github.io/auto_examples/plot_decoding_tutorial.html#sphx-glr-auto-examples-plot-decoding-tutorial-py
(2)https://nilearn.github.io/decoding/decoding_intro.html
(3)https://nilearn.github.io/decoding/searchlight.html
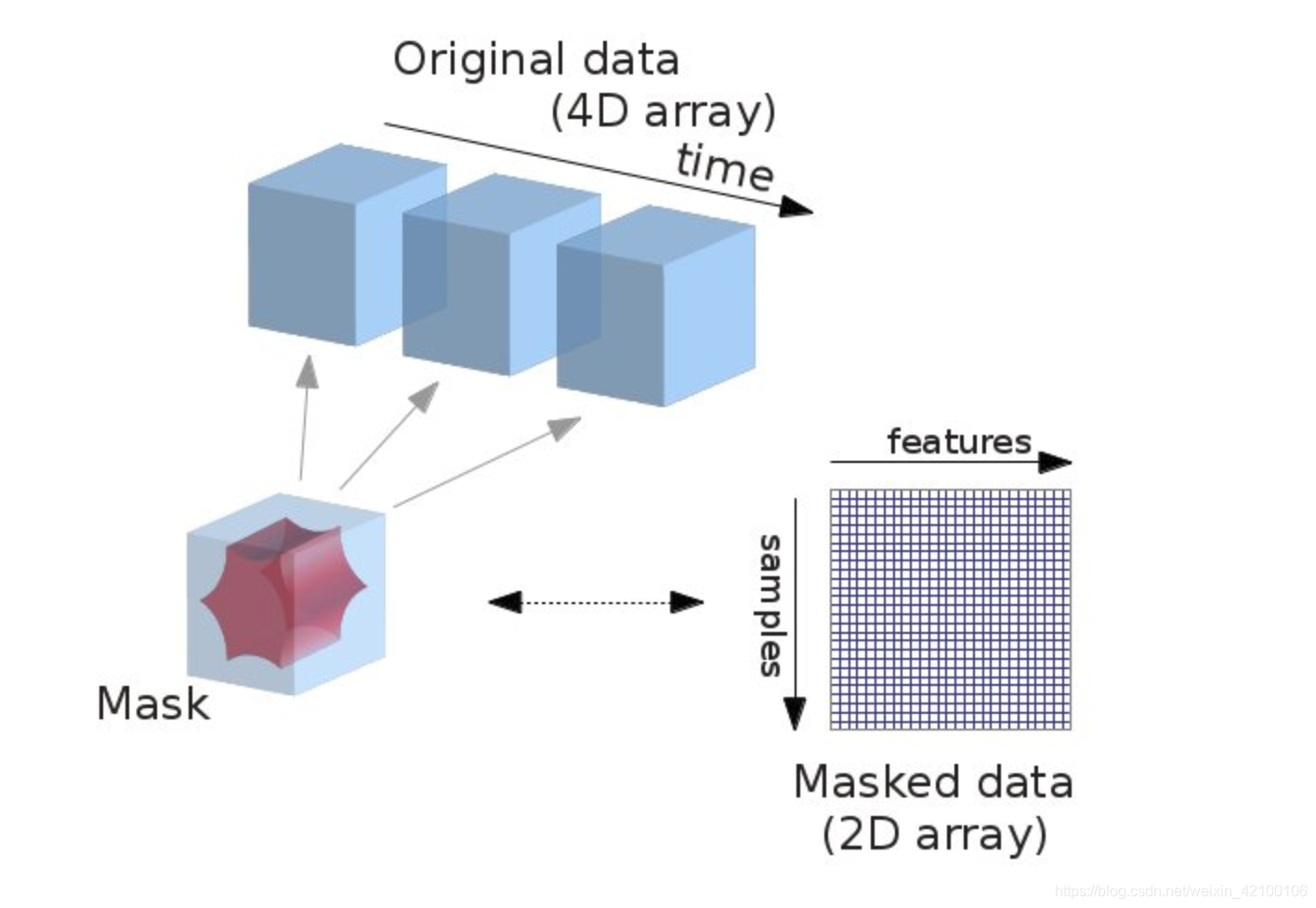 此例子,每个体素一个权重,一个采样点(也就是数据集)有一个标签(即行为状态)。(不一定是一个人,可能是一个受试者的一个采样点)
此例子,每个体素一个权重,一个采样点(也就是数据集)有一个标签(即行为状态)。(不一定是一个人,可能是一个受试者的一个采样点)
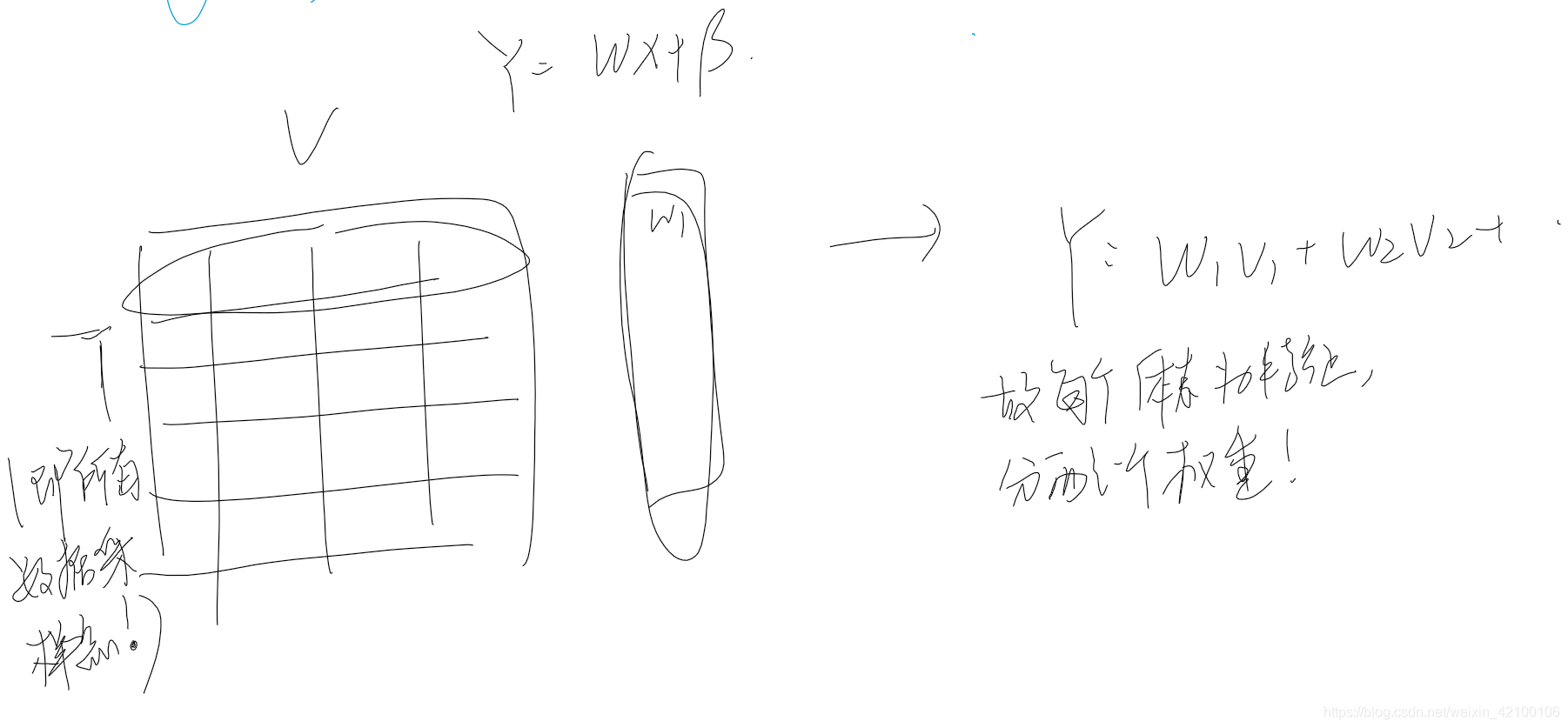 其中第二个链接的下图部分:是在MVPA之前利用GLM构造beta 体素map,将这个map作为特征输入解码器,用于快速时间里面BOLD信号序列的区分。
其中第二个链接的下图部分:是在MVPA之前利用GLM构造beta 体素map,将这个map作为特征输入解码器,用于快速时间里面BOLD信号序列的区分。
但也可以直接用原始的时间序列。
但是目前我还不清楚为什么这么做,以及这么做有什么好处

同时,通过多篇文章的研读,MVPA的应用不限于这种形式。
cross-validation—cv
GLM 就是一种回归的机器学习模型,与LASSO回归相似,design matrix就是特征向量。
https://nilearn.github.io/auto_examples/plot_decoding_tutorial.html#sphx-glr-auto-examples-plot-decoding-tutorial-py
详细介绍brain decoding
研究一下MVPA工具箱
参考
http://www.360doc.com/content/20/0401/07/42745377_903106177.shtml
Mumford, J.A., Turner, B.O., Ashby, F.G., Poldrack, R.A., 2012. Deconvolving BOLD activation in
event-related designs for multivoxel pattern classification analyses. NeuroImage 59, 2636–2643.
doi:10.1016/j.neuroimage.2011.08.076.

















 8759
8759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









