









从信息论到机器学习的损失函数
信息论
最大互信息原则:多层神经网络的突触连接以这样一种方式进行;在网络的每个处理阶段 ,当进行信号变换时,为保留的信息量达到最大,要遵从一定的约束条件。
感知系统的信息论作用:感知机制的一个主要功能是减小刺激的冗余,以一种比它冲击接收器的形式更经济的公式对信息进行描述或编码。
一个随机变量x的每一个出现可看作一个消息。严格说,如果随机变量x的幅度值是连续的,则它带着无穷的信息,但这是没有意义的,这就是可以把x的值一致量化到有限的离散水平。把x看成是离散的随机变量,其模型为
x
=
{
x
k
∣
k
=
0
,
±
1
,
⋯
,
±
k
}
x=\left\{x_{k} | k=0, \pm 1, \cdots, \pm k\right\}
x={xk∣k=0,±1,⋯,±k}
让事件
x
=
x
k
x=x_{k}
x=xk以
p
k
=
p
(
x
=
x
k
)
p_{k}=p\left(x=x_{k}\right)
pk=p(x=xk) 的概率发生,其中这个概率在0-1之间,且
∑
k
=
−
k
k
p
k
=
1
\sum_{k=-k}^{k} p_{k}=1
k=−k∑kpk=1
首先,我们定义观察到具有概率p_k 的事件
x
=
x
k
x=x_{k}
x=xk后获得的信息增益量为对数函数
I
(
x
k
)
=
log
(
1
p
k
)
=
−
log
p
k
I\left(x_{k}\right)=\log \left(\frac{1}{p_{k}}\right)=-\log p_{k}
I(xk)=log(pk1)=−logpk
(即信息量与事件发生概率成反比)底数为𝑒时,单位是奈特,底数为2时;单位是比特或香农。由此得到,
I
(
x
k
)
=
0
I\left(x_{k}\right)=0
I(xk)=0 ,当
p
k
=
1
p_{k}=1
pk=1 。信息量
I
(
x
k
)
I\left(x_{k}\right)
I(xk)也是一个具有概率
p
k
p_{k}
pk的离散随机变量。
I
(
x
k
)
I\left(x_{k}\right)
I(xk)全部2𝑘+1个离散数值上的平均值上的平均值定义为:
H
(
X
)
=
E
(
I
(
x
k
)
)
=
∑
k
=
−
k
k
p
k
I
(
x
k
)
=
−
∑
k
=
−
k
k
p
k
log
p
k
H(X)=E\left(I\left(x_{k}\right)\right)=\sum_{k=-k}^{k} p_{k} I\left(x_{k}\right)=-\sum_{k=-k}^{k} p_{k} \log p_{k}
H(X)=E(I(xk))=k=−k∑kpkI(xk)=−k=−k∑kpklogpk
𝐻(𝑋)即为一个可取离散随机变量𝑥的熵,意义为每一个消息所携带的消息的平均量。
==
注:以下用I(a)表示a事件发生的信息量有两个事件a,b:
1、0<p(a)<p(b)<1,则 I(a)>I(b)
2、p(a)=0,则 I(a)->infinity
3、p(a)=1,则 I(a)=0
4、p(a,b)=p(a)p(b),I(a,b)=I(a)+I(b)
经过严格证明满足上述条件的信息函数一定有些形式(充分必要):I(a)=-logp(a) 这里的底数是大于1的均可。
==
接下来引入微分熵的概念,h(x)为连续随机变量的熵定义为x的微分熵
h
(
x
)
=
−
∫
−
∞
∞
p
x
(
x
)
log
p
x
(
x
)
d
x
=
−
E
[
log
p
x
(
x
)
]
h(x)=-\int_{-\infty}^{\infty} p_{x}(x) \log p_{x}(x) d x=-E\left[\log p_{x}(x)\right]
h(x)=−∫−∞∞px(x)logpx(x)dx=−E[logpx(x)]
其与H(x)联系为
H
(
x
)
=
h
(
x
)
−
lim
δ
→
0
log
p
x
(
x
)
H(x)=h(x)-\lim _{\delta \rightarrow 0} \log p_{x}(x)
H(x)=h(x)−δ→0limlogpx(x)上式中x为单值变量。
最大熵原则:当根据不完整的信息作为依据进行推断时,应该由满足分布限制条件的具有最大熵的概率分布推得。熵的概念在概率分布空间定义一种度量,使得具有较高熵的分布比其他的分布具有更大的值。
互信息
考虑一对连续随机变量𝑋和𝑌,这两者是相关的。由
p
(
x
,
y
)
=
p
(
x
)
p
(
y
∣
x
)
p(x, y)=p(x) p(y | x)
p(x,y)=p(x)p(y∣x)以及微分熵的定义
h
(
X
,
Y
)
=
h
(
X
)
+
h
(
Y
∣
X
)
=
h
(
Y
)
+
h
(
X
∣
Y
)
h(X, Y)=h(X)+h(Y | X)=h(Y)+h(X | Y)
h(X,Y)=h(X)+h(Y∣X)=h(Y)+h(X∣Y)
h(X,Y)为X和Y的联合微分熵,h(Y|X)为条件微分熵。
令
I
(
X
;
Y
)
=
h
(
X
)
−
h
(
X
∣
Y
)
=
−
∫
−
∞
∞
∫
−
∞
∞
P
X
,
Y
(
x
,
y
)
log
P
X
(
x
)
d
x
d
y
+
∫
−
∞
∞
∫
−
∞
∞
P
X
,
Y
(
x
,
y
)
log
P
X
(
x
/
y
)
d
x
d
y
=
∫
−
∞
∞
P
X
,
Y
(
x
,
y
)
log
(
P
X
,
Y
(
x
,
y
)
P
X
(
x
)
P
Y
(
y
)
)
d
x
d
y
\begin{aligned} I(X ; Y)=& h(X)-h(X | Y)=-\int_{-\infty}^{\infty} \int_{-\infty}^{\infty} P_{X, Y}(x, y) \log P_{X}(x) d x d y \\ &+\int_{-\infty}^{\infty} \int_{-\infty}^{\infty} P_{X, Y}(x, y) \log P_{X}(x / y) d x d y \\=& \int_{-\infty}^{\infty} P_{X, Y}(x, y) \log \left(\frac{P_{X, Y}(x, y)}{P_{X}(x) P_{Y}(y)}\right) d x d y \end{aligned}
I(X;Y)==h(X)−h(X∣Y)=−∫−∞∞∫−∞∞PX,Y(x,y)logPX(x)dxdy+∫−∞∞∫−∞∞PX,Y(x,y)logPX(x/y)dxdy∫−∞∞PX,Y(x,y)log(PX(x)PY(y)PX,Y(x,y))dxdy
这一熵差称为系统输入𝑥和系统输出𝑌之间的互信息,意义为观察系统输出𝑌所决定的系统输入𝑥的不确定性。
相对熵
对于同一个随机变量𝑥有两个单独的概率分布𝑃(𝑋)和𝑄(𝑋)。即针对同一事件,有两个概率分布𝑃(代表真实概率)和𝑄(代表模型概率)可以用相对熵来衡量这两个分布差异:
D
p
∥
q
=
∫
−
∞
∞
P
X
(
x
)
log
(
P
X
(
x
)
Q
X
(
x
)
)
d
x
=
E
x
∼
p
[
log
(
P
X
(
x
)
Q
X
(
x
)
)
]
=
E
x
∼
P
[
log
P
(
x
)
−
log
Q
(
x
)
]
D_{p \| q}=\int_{-\infty}^{\infty} P_{X}(x) \log \left(\frac{P_{X}(x)}{Q_{X}(x)}\right) d x=E_{x \sim p}\left[\log \left(\frac{P_{X}(x)}{Q_{X}(x)}\right)\right]=E_{x \sim P}[\log P(x)-\log Q(x)]
Dp∥q=∫−∞∞PX(x)log(QX(x)PX(x))dx=Ex∼p[log(QX(x)PX(x))]=Ex∼P[logP(x)−logQ(x)]
相对熵又被称为KL散度。
==
注:
由
I
(
X
;
Y
)
=
∫
−
∞
∞
∫
−
∞
∞
P
X
,
Y
(
x
,
y
)
log
(
P
X
,
Y
(
x
,
y
)
P
X
(
x
)
P
Y
(
y
)
)
d
x
d
y
由I(X ; Y)=\int_{-\infty}^{\infty} \int_{-\infty}^{\infty} P_{X, Y}(x, y) \log \left(\frac{P_{X, Y}(x, y)}{P_{X}(x) P_{Y}(y)}\right) d x d y
由I(X;Y)=∫−∞∞∫−∞∞PX,Y(x,y)log(PX(x)PY(y)PX,Y(x,y))dxdy
= D P X , Y ∥ P X ( x ) P Y ( y ) =D_{P_{X, Y} \| P_{X}(x) P_{Y}(y)} =DPX,Y∥PX(x)PY(y)
即𝑋和𝑌之间的互信息𝐼(𝑋;𝑌)等于联合概率密度函数 P X , Y ( x , y ) P_{X, Y}(x, y) PX,Y(x,y)以及概率密度函数𝑃_𝑋 (𝑥)和𝑃_𝑌 (𝑦)的积的相对熵。
==
交叉熵
H ( P , Q ) = H ( P ) + D K L ( P ∥ Q ) H(P, Q)=H(P)+D_{K L}(P \| Q) H(P,Q)=H(P)+DKL(P∥Q)
= − E x ∼ p [ log P ( x ) ] + E x ∼ p [ log P ( x ) Q ( x ) ] =-E_{x \sim p}[\log P(x)]+E_{x \sim p}\left[\log \frac{P(x)}{Q(x)}\right] =−Ex∼p[logP(x)]+Ex∼p[logQ(x)P(x)]
= − E x ∼ p [ log Q ( x ) ] = − ∫ − ∞ ∞ P ( x ) log Q ( x ) d x =-E_{x \sim p}[\log Q(x)]=-\int_{-\infty}^{\infty} P(x) \log Q(x) d x =−Ex∼p[logQ(x)]=−∫−∞∞P(x)logQ(x)dx
或是 = − ∑ x P ( x ) log Q ( x ) =-\sum_{x} P(x) \log Q(x) =−x∑P(x)logQ(x)
==
注:并且由此式可以看出只有当𝑃(𝑥)与𝑄(𝑥)完全一致时 𝐻(𝑃,𝑄)=𝐻(𝑃),其他情况都是𝐻(𝑃,𝑄)>𝐻(𝑃);
综上相对熵与交叉熵,我们衡量两个分布的差异本来是用相对熵(𝐾𝐿散度),但是当𝑃(𝑥)固定时,即事件𝑥满足的先验分布一定时,由𝐻(𝑃,𝑄)=𝐻(𝑃)+𝐷_𝐾𝐿 (𝑃||𝑄)也即𝐻(𝑃)不变,那么我们可以用𝐻(𝑃,𝑄)即𝑃和𝑄的交叉熵来代替相对熵来评估模型!!!
==
logistic回归
在𝑙𝑜𝑔𝑖𝑠𝑡𝑖𝑐回归中𝑠𝑖𝑔𝑚𝑜𝑖𝑑函数的输出了表征了当前样本标签为1的概率:
h
θ
(
x
)
=
P
(
y
=
1
∣
x
)
h_{\theta}(x)=P(y=1 | x)
hθ(x)=P(y=1∣x)
因此,样本标签为0的概率就可以表达成:
1
−
h
θ
(
x
)
=
P
(
y
=
0
∣
x
)
1-h_{\theta}(x)=P(y=0 | x)
1−hθ(x)=P(y=0∣x)
代入交叉熵损失函数中,即为:
y
log
h
θ
(
x
)
+
(
1
−
y
)
log
(
1
−
h
θ
(
x
)
)
y \log h_{\theta}(x)+(1-y) \log \left(1-h_{\theta}(x)\right)
yloghθ(x)+(1−y)log(1−hθ(x))
由于上式是在最后一层所分出的一个类的一个样本的𝑙𝑜𝑠𝑠 𝑓𝑢𝑛𝑐𝑡𝑖𝑜𝑛
那么整个样本的cost 𝑓𝑢𝑛𝑐𝑡𝑖𝑜𝑛为:
J ( θ ) = − 1 m [ ∑ i = 1 m ∑ k = 1 K y k ( i ) log h θ ( x ( i ) ) k + ( 1 − y k ( i ) ) log ( 1 − h θ ( x ( i ) ) k ) ] J(\theta)=-\frac{1}{m}\left[\sum_{i=1}^{m} \sum_{k=1}^{K} y_{k}^{(i)} \log h_{\theta}\left(x^{(i)}\right)_{k}+\left(1-y_{k}^{(i)}\right) \log \left(1-h_{\theta}\left(x^{(i)}\right)_{k}\right)\right] J(θ)=−m1[i=1∑mk=1∑Kyk(i)loghθ(x(i))k+(1−yk(i))log(1−hθ(x(i))k)]
(由于平方误差函数用于线性回归中很好,但是当用于逻辑回归时呈现的是非凸状态,有很多鞍点,不容易取到最值,所以在逻辑回归中,最常用的是交叉熵代价函数,在神经网络中也会用到。)
从最大似然角度看,设
P
(
y
^
(
i
)
=
1
∣
x
(
i
)
;
θ
)
=
h
θ
(
x
(
i
)
)
P\left(\widehat{y}^{(i)}=1 | x^{(i)} ; \theta\right)=h_{\theta}\left(x^{(i)}\right)
P(y
(i)=1∣x(i);θ)=hθ(x(i))
则 P ( y ^ ( i ) = 0 ∣ x ( i ) ; θ ) = 1 − h θ ( x ( i ) ) P\left(\widehat{y}^{(i)}=0 | x^{(i)} ; \theta\right)=1-h_{\theta}\left(x^{(i)}\right) P(y (i)=0∣x(i);θ)=1−hθ(x(i))
将上述两种情况整合到一起:
P
(
y
∣
x
)
=
y
^
y
(
1
−
y
^
)
1
−
y
P(y | x)=\hat{y}^{y}(1-\hat{y}) ^{1-y}
P(y∣x)=y^y(1−y^)1−y
那么对于多个样本的概率函数推导为:
p
(
y
∣
x
)
=
[
p
(
y
^
(
i
)
=
1
∣
x
(
i
)
;
Θ
)
]
y
(
i
)
[
p
(
y
^
(
i
)
=
0
∣
x
(
i
)
;
Θ
)
]
(
1
−
y
(
i
)
)
p(y | x)=\left[p\left(\widehat{y}^{(i)}=1 | x^{(i)} ; \Theta\right)\right] y^{(i)}\left[p\left(\widehat{y}^{(i)}=0 | x^{(i)} ; \Theta\right)\right]\left(1-y^{(i)}\right)
p(y∣x)=[p(y
(i)=1∣x(i);Θ)]y(i)[p(y
(i)=0∣x(i);Θ)](1−y(i))
将概率取对数,其单调性不变:
log
P
(
y
^
(
i
)
=
1
∣
x
(
i
)
;
θ
)
=
log
h
θ
(
x
(
i
)
)
\log P\left(\widehat{y}^{(i)}=1 | x^{(i)} ; \theta\right)=\log h_{\theta}\left(x^{(i)}\right)
logP(y
(i)=1∣x(i);θ)=loghθ(x(i))
log P ( y ^ ( i ) = 0 ∣ x ( i ) ; θ ) = log ( 1 − h θ ( x ( i ) ) ) \log P\left(\widehat{y}^{(i)}=0 | x^{(i)} ; \theta\right)=\log \left(1-h_{\theta}\left(x^{(i)}\right)\right) logP(y (i)=0∣x(i);θ)=log(1−hθ(x(i)))
log p ( y ∣ x ) = log { [ p ( y ^ ( i ) = 1 ∣ x ( i ) ; Θ ) ] y ( i ) ∗ [ p ( y ^ ( i ) = 0 ∣ x ( i ) ; Θ ) ] ( 1 − y ( i ) ) } \log p(y | x)=\log \left\{\left[p\left(\widehat{y}^{(i)}=1 | x^{(i)} ; \Theta\right)\right] y^{(i) *}\left[p\left(\widehat{y}^{(i)}=0 | x^{(i)} ; \Theta\right)\right]\left(1-y^{(i)}\right)\right\} logp(y∣x)=log{[p(y (i)=1∣x(i);Θ)]y(i)∗[p(y (i)=0∣x(i);Θ)](1−y(i))}
= y ( i ) log P ( y ^ ( i ) = 1 ∣ x ( i ) ; θ ) + ( 1 − y ( i ) ) log P ( y ^ ( i ) = 0 ∣ x ( i ) ; θ ) = y ( i ) log h θ ( x ( i ) ) + ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) \begin{array}{l}{=y^{(i)} \log P\left(\widehat{y}^{(i)}=1 | x^{(i)} ; \theta\right)+\left(1-y^{(i)}\right)\log P\left(\widehat{y}^{(i)}=0 | x^{(i)} ; \theta\right)} \\ {=y^{(i)} \log h_{\theta}\left(x^{(i)}\right)+\left(1-y^{(i)}\right) \log \left(1-h_{\theta}\left(x^{(i)}\right)\right)}\end{array} =y(i)logP(y (i)=1∣x(i);θ)+(1−y(i))logP(y (i)=0∣x(i);θ)=y(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))
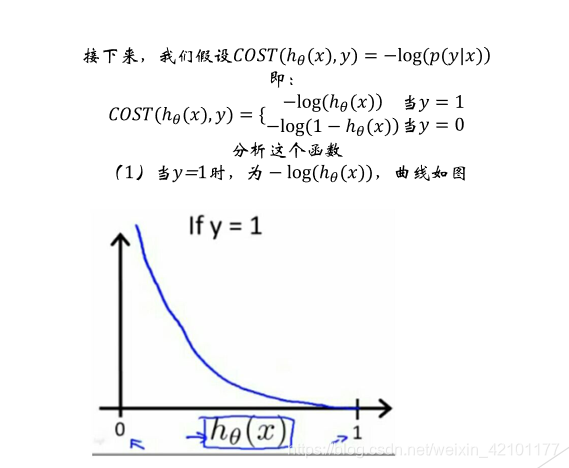
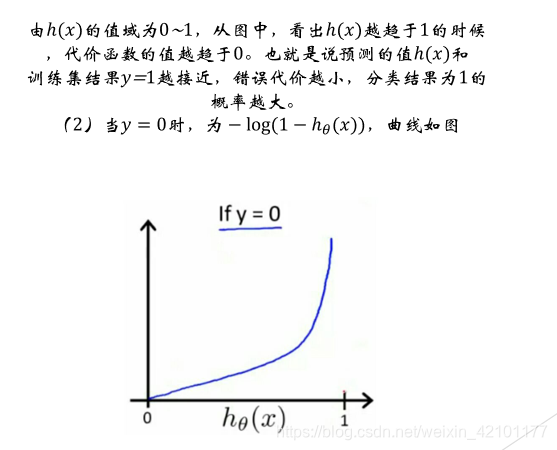
当ℎ(𝑥)的值趋于0时,代价函数的值越趋于0,也就是预测的值和训练集真实值越接近,错误代价越小,此时,分类为0的概率1−ℎ(𝑥)接近于1。综上所述,所设函数符合代价函数要求,即所设函数可以作为代价函数
由以上表征正确的概率含义可知,我们希望其值越大,模型对数据的表达能力@越好。而我们在参数更新或衡量模型优劣时是需要一个能充分反映模型表现误@差的损失函数或者代价函数的,而且我们希望损失函数越小越好。由这两个矛@盾,我们不妨让代价函数为上述组合对数函数的相反数:
J
(
θ
)
=
−
1
m
∑
i
=
1
m
∑
k
=
1
K
[
y
k
(
i
)
log
h
θ
(
x
(
i
)
)
k
+
(
1
−
y
k
(
i
)
)
log
(
1
−
h
θ
(
x
(
i
)
)
k
)
]
J(\theta)=-\frac{1}{m} \sum_{i=1}^{m} \sum_{k=1}^{K}\left[y_{k}^{(i)} \log h_{\theta}\left(x^{(i)}\right)_{k}+\left(1-y_{k}^{(i)}\right) \log \left(1-h_{\theta}\left(x^{(i)}\right)_{k}\right)\right]
J(θ)=−m1i=1∑mk=1∑K[yk(i)loghθ(x(i))k+(1−yk(i))log(1−hθ(x(i))k)]
此式即为从最大似然角度来形成的交叉熵代价函数。
交叉熵代价函数的另一种推导:
∂ L ∂ b = ∂ L ∂ a ∂ a ∂ z ∂ z ∂ b = ∂ L ∂ a δ ′ ( z ) ∂ ( w x + b ) ∂ b = ∂ L ∂ a δ ′ ( z ) = ∂ L ∂ a a ( 1 − a ) \begin{aligned} \frac{\partial L}{\partial b}&=\frac{\partial L}{\partial a} \frac{\partial a}{\partial z} \frac{\partial z}{\partial b} \\&=\frac{\partial L}{\partial a} \delta^{\prime}(z) \frac{\partial(w x+b)}{\partial b} \\&=\frac{\partial L}{\partial a} \delta^{\prime}(z) \\&=\frac{\partial L}{\partial a} a(1-a) \end{aligned} ∂b∂L=∂a∂L∂z∂a∂b∂z=∂a∂Lδ′(z)∂b∂(wx+b)=∂a∂Lδ′(z)=∂a∂La(1−a)
由
(
δ
′
(
z
)
=
δ
(
z
)
(
1
−
δ
(
z
)
)
)
由(\delta^{\prime}(z)=\delta(z)(1-\delta(z)))
由(δ′(z)=δ(z)(1−δ(z)))
而在均方误差代价函数中推导的b梯度公式为:
∂
L
∂
b
=
(
a
−
y
)
δ
′
(
z
)
\frac{\partial L}{\partial b}=(a-y) \delta^{\prime}(z)
∂b∂L=(a−y)δ′(z)
为了消掉该公式中的
δ
′
(
z
)
\delta^{\prime}(z)
δ′(z) ,我们想找到一个代价函数使得:
∂
L
∂
b
=
(
a
−
y
)
\frac{\partial L}{\partial b}=(a-y)
∂b∂L=(a−y)
即为:
∂
L
∂
a
a
(
1
−
a
)
=
(
a
−
y
)
\frac{\partial L}{\partial a} a(1-a)=(a-y)
∂a∂La(1−a)=(a−y)
对偏微分方程求解,可得:
L
=
−
[
y
ln
a
+
(
1
−
a
)
ln
(
1
−
a
)
]
+
constant
L=-[y \ln a+(1-a) \ln (1-a)]+\text {constant }
L=−[ylna+(1−a)ln(1−a)]+constant
即为交叉熵代价函数。
[参考文档]
1、统计学习方法
2、机器学习与神经网络(机械工业出版社)














 6253
6253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









