







VAE的前世今生
1. 背景知识
1.1 ELBo
1.1.1 为什么引入隐变量 z z z ?
因为我们在现实世界看到的物体可能也产生于高层级的表示,这样的表示或许概括了颜色、大小、形状等的抽象属性。
1.1.2 如何推导ELBo (Evidence Lower Bound)?
无条件的生成模型学习的是如何建模真实分布 p ( x ) p\left (x\right ) p(x) ,所以有:
log p ( x ) ⏟ e v i d e n c e = log p ( x ) ∫ q ϕ ( z ∣ x ) ⏟ approximate posterior d z = ∫ q ϕ ( z ∣ x ) ( log p ( x ) ) d z = E q ϕ ( z ∣ x ) [ log p ( x ) ] = E q ϕ ( z ∣ x ) [ log p ( x , z ) p ( z ∣ x ) ] = E q ϕ ( z ∣ x ) [ log p ( x , z ) q ϕ ( z ∣ x ) p ( z ∣ x ) q ϕ ( z ∣ x ) ] = E q ϕ ( z ∣ x ) [ log p ( x , z ) q ϕ ( z ∣ x ) ] + E q ϕ ( z ∣ x ) [ log q ϕ ( z ∣ x ) p ( z ∣ x ) ] = E q ϕ ( z ∣ x ) [ log p ( x , z ) q ϕ ( z ∣ x ) ] ⏟ ELBo + D K L ( q ϕ ( z ∣ x ) ⏟ approximate posterior ∥ p ( z ∣ x ) ⏟ true posterior ) ⏟ ≥ 0 ≥ E q ϕ ( z ∣ x ) [ log p ( x , z ) q ϕ ( z ∣ x ) ] ⏟ ELBo \begin{align} \log{\underbrace{p\left (x\right )}_{\text evidence}} &= \log{p\left (x\right )}\int \underbrace{q_{\phi}\left (z\vert x\right )}_{\text{approximate posterior}}dz \\ &=\int q_{\phi}\left (z\vert x\right )\left (\log{p\left (x\right )}\right )dz \\ &=\mathbb{E}_{q_{\phi}\left (z\vert x\right )}\left [\log{p\left (x\right )}\right ] \\ &=\mathbb{E}_{q_{\phi}\left (z\vert x\right )}\left [\log{\frac{p\left (x,z\right )}{p\left (z\vert x\right )}}\right ] \\ &=\mathbb{E}_{q_{\phi}\left (z\vert x\right )}\left [ \log{\frac{p\left (x,z\right )q_{\phi}\left (z\vert x\right )}{p\left (z\vert x\right )q_{\phi}\left (z\vert x\right )}}\right ] \\ &=\mathbb{E}_{q_{\phi}\left (z\vert x\right )}\left [\log{\frac{p\left (x, z\right )}{q_{\phi}\left (z\vert x\right )}}\right ] + \mathbb{E}_{q_{\phi}\left (z\vert x\right )}\left [\log{\frac{q_{\phi}\left (z\vert x\right )}{p\left (z\vert x\right )}}\right ] \\ &=\underbrace{\mathbb{E}_{q_{\phi}\left (z\vert x\right )}\left [\log{\frac{p\left (x,z\right )}{q_{\phi}\left (z\vert x\right )}}\right ]}_{\text{ELBo}} + \underbrace{D_{KL}\left (\underbrace{q_{\phi}\left (z\vert x\right )}_{\text{approximate posterior}} \Vert \underbrace{p\left (z\vert x\right )}_{\text{true posterior}}\right )}_{\geq 0} \\ &\geq \underbrace{\mathbb{E}_{q_{\phi}\left (z\vert x\right )}\left [\log{\frac{p\left (x, z\right )}{q_{\phi}\left (z\vert x\right )}}\right ]}_{\text{ELBo}} \end{align} logevidence p(x)=logp(x)∫approximate posterior qϕ(z∣x)dz=∫qϕ(z∣x)(logp(x))dz=Eqϕ(z∣x)[logp(x)]=Eqϕ(z∣x)[logp(z∣x)p(x,z)]=Eqϕ(z∣x)[logp(z∣x)qϕ(z∣x)p(x,z)qϕ(z∣x)]=Eqϕ(z∣x)[logqϕ(z∣x)p(x,z)]+Eqϕ(z∣x)[logp(z∣x)qϕ(z∣x)]=ELBo Eqϕ(z∣x)[logqϕ(z∣x)p(x,z)]+≥0 DKL approximate posterior qϕ(z∣x)∥true posterior p(z∣x) ≥ELBo Eqϕ(z∣x)[logqϕ(z∣x)p(x,z)]
1.1.3 为什么要去最大化ELBo?
原因1:因为我们想要模型学习近似后验 q ϕ ( z ∣ x ) q_{\phi}\left (z\vert x\right ) qϕ(z∣x) 无限接近真实后验 p ( z ∣ x ) p\left (z\vert x\right ) p(z∣x),但是无法直接去求公式 (7) 中的 D K L D_{KL} DKL 项:
min ϕ D K L ( q ϕ ( z ∣ x ) ⏟ approximate posterior ⏟ Encoder is learnable ∥ p ( z ∣ x ) ⏟ true posterior ⏟ unknow ) ⏟ untractable \begin{align} \min_{\phi}{\underbrace{D_{KL}\left (\underbrace{\underbrace{q_{\phi}\left (z\vert x\right )}_{\text{approximate posterior}} }_{\text{Encoder is learnable}} \Vert \underbrace{\underbrace{p\left (z\vert x\right )}_{\text{true posterior}}}_{\text{unknow}}\right )}_{\text{untractable}}} \end{align} ϕminuntractable DKL Encoder is learnable approximate posterior qϕ(z∣x)∥unknow true posterior p(z∣x)
原因2:对于任意的样本
x
i
∼
p
(
x
)
x_i \sim p\left (x\right )
xi∼p(x),
p
(
x
i
)
p\left (x_i\right )
p(xi)是个常数,那么通过
max
ϕ
ELBo
\max_{\phi}{\text{ELBo}}
maxϕELBo等价于
min
ϕ
D
K
L
\min_{\phi}{D_{KL}}
minϕDKL
∵
log
p
(
x
i
)
⏟
c
o
n
s
t
a
n
t
=
E
q
ϕ
(
z
∣
x
i
)
[
log
p
(
x
i
,
z
)
q
ϕ
(
z
∣
x
i
)
]
⏟
ELBo
+
D
K
L
(
q
ϕ
(
z
∣
x
i
)
⏟
approximate posterior
∥
p
(
z
∣
x
i
)
⏟
true posterior
)
⏟
≥
0
min
ϕ
D
K
L
⟺
max
ϕ
ELBo
\begin{align} \because\log{\underbrace{p\left (x_i\right )}_{\text constant}} &= \underbrace{\mathbb{E}_{q_{\phi}\left (z\vert x_i\right )}\left [\log{\frac{p\left (x_{i},z\right )}{q_{\phi}\left (z\vert x_i\right )}}\right ]}_{\text{ELBo}} + \underbrace{D_{KL}\left (\underbrace{q_{\phi}\left (z\vert x_i\right )}_{\text{approximate posterior}} \Vert \underbrace{p\left (z\vert x_i\right )}_{\text{true posterior}}\right )}_{\geq 0} \\ \min_{\phi}{D_{KL}} &\iff \max_{\phi}{\text{ELBo}} \end{align}
∵logconstant
p(xi)ϕminDKL=ELBo
Eqϕ(z∣xi)[logqϕ(z∣xi)p(xi,z)]+≥0
DKL
approximate posterior
qϕ(z∣xi)∥true posterior
p(z∣xi)
⟺ϕmaxELBo
2. VAE (Variational Autoencoder)
2.1 为什么Variational?
因为我们优化的 q ϕ ( z ∣ x ) q_{\phi}\left (z\vert x\right ) qϕ(z∣x) 服从某一分布族,该分布族被 ϕ \mathbf{\phi} ϕ 参数化,这就是 Variational 的来源。
2.2 为什么Autoencoder?
因为模型会像AE (Autoencoder) 模型一样压缩数据维度,提取数据中的有效信息。
2.3 VAE的优化目标是什么?
max ϕ E q ϕ ( z ∣ x ) [ log p ( x , z ) q ϕ ( z ∣ x ) ] ⏟ ELBo = max ϕ , θ E q ϕ ( z ∣ x ) [ log p θ ( x ∣ z ) p ( z ) q ϕ ( z ∣ x ) ] = max ϕ , θ E q ϕ ( z ∣ x ) [ log p θ ( x ∣ z ) ] + E q ϕ ( z ∣ x ) [ p ( z ) q ϕ ( z ∣ x ) ] = max ϕ , θ E q ϕ ( z ∣ x ) [ log p θ ( x ∣ z ) ⏟ Decoder ] ⏟ resconstraction term − D K L ( q ϕ ( z ∣ x ) ⏟ Encoder ∥ p ( z ) ⏟ prior ) ⏟ prior matching term ≈ Monte Carlo Estimate max ϕ , θ ∑ l = 1 L log p θ ( x ∣ z l ) − D K L ( q ϕ ( z ∣ x ) ⏟ ∼ N ( μ , σ 2 ) ∥ p ( z ) ⏟ ∼ N ( 0 , 1 ) ) = max ϕ , θ ∑ l = 1 L log p θ ( x ∣ z l ) − 1 2 ( − log σ 2 + μ 2 + σ 2 − 1 ) \begin{align} &\max_{\phi}\underbrace{\mathbb{E}_{q_{\phi}\left (z\vert x\right )}\left [\log{\frac{p\left (x, z\right )}{q_{\phi}\left (z\vert x\right )}}\right ]}_{\text{ELBo}} \\ &= \max_{\phi,\theta}\mathbb{E}_{q_{\phi}\left (z\vert x\right )}\left [\log{\frac{p_{\theta}\left (x\vert z\right )p\left (z\right )}{q_{\phi}\left (z\vert x\right )}}\right ] \\ &=\max_{\phi,\theta}\mathbb{E}_{q_{\phi}\left (z\vert x\right )}\left [\log{p_{\theta}\left (x\vert z\right )}\right ] + \mathbb{E}_{q_{\phi}\left (z\vert x\right )}\left [\frac{p\left (z\right )}{q_{\phi}\left (z\vert x\right )}\right ]\\ &=\max_{\phi,\theta}\underbrace{\mathbb{E}_{q_{\phi}\left (z\vert x\right )}\left [\log{\underbrace{p_{\theta}\left (x\vert z\right )}_{\text{Decoder}}}\right ]}_{\text{resconstraction term}} - \underbrace{D_{KL}\left (\underbrace{q_{\phi}\left (z\vert x\right )}_{\text{Encoder}} \Vert \underbrace{p\left (z\right )}_{\text{prior}}\right )}_{\text{prior matching term}} \\ &\overset{\text{Monte Carlo Estimate}}{\approx}\max_{\phi,\theta}\sum_{l=1}^{L}\log{p_{\theta}\left (x\vert z^{l}\right )} - D_{KL}\left (\underbrace{q_{\phi}\left (z\vert x\right )}_{\sim N\left (\mu,\sigma^2\right )}\Vert \underbrace{p\left (z\right )}_{\sim N\left (0,1\right )}\right )\\ &=\max_{\phi,\theta}\sum_{l=1}^{L}\log{p_{\theta}\left (x\vert z^{l}\right )} - \frac{1}{2}\left (-\log{\sigma^2} + \mu^2 + \sigma^2 - 1\right ) \end{align} ϕmaxELBo Eqϕ(z∣x)[logqϕ(z∣x)p(x,z)]=ϕ,θmaxEqϕ(z∣x)[logqϕ(z∣x)pθ(x∣z)p(z)]=ϕ,θmaxEqϕ(z∣x)[logpθ(x∣z)]+Eqϕ(z∣x)[qϕ(z∣x)p(z)]=ϕ,θmaxresconstraction term Eqϕ(z∣x) logDecoder pθ(x∣z) −prior matching term DKL Encoder qϕ(z∣x)∥prior p(z) ≈Monte Carlo Estimateϕ,θmaxl=1∑Llogpθ(x∣zl)−DKL ∼N(μ,σ2) qϕ(z∣x)∥∼N(0,1) p(z) =ϕ,θmaxl=1∑Llogpθ(x∣zl)−21(−logσ2+μ2+σ2−1)
由等式 (15) (16) 可知,优化目标主要包括了两项:重构项 (reconstruction term) 迫使模型的解码器 (Decoder) 学习由隐变量 z z z 恢复原始样本的能力;先验匹配项 (prior matching term) 迫使模型的编码器 (Encoder) 学习将原始样本转换到先验分布 (标准正态分布) 的能力。
2.4 VAE模型架构
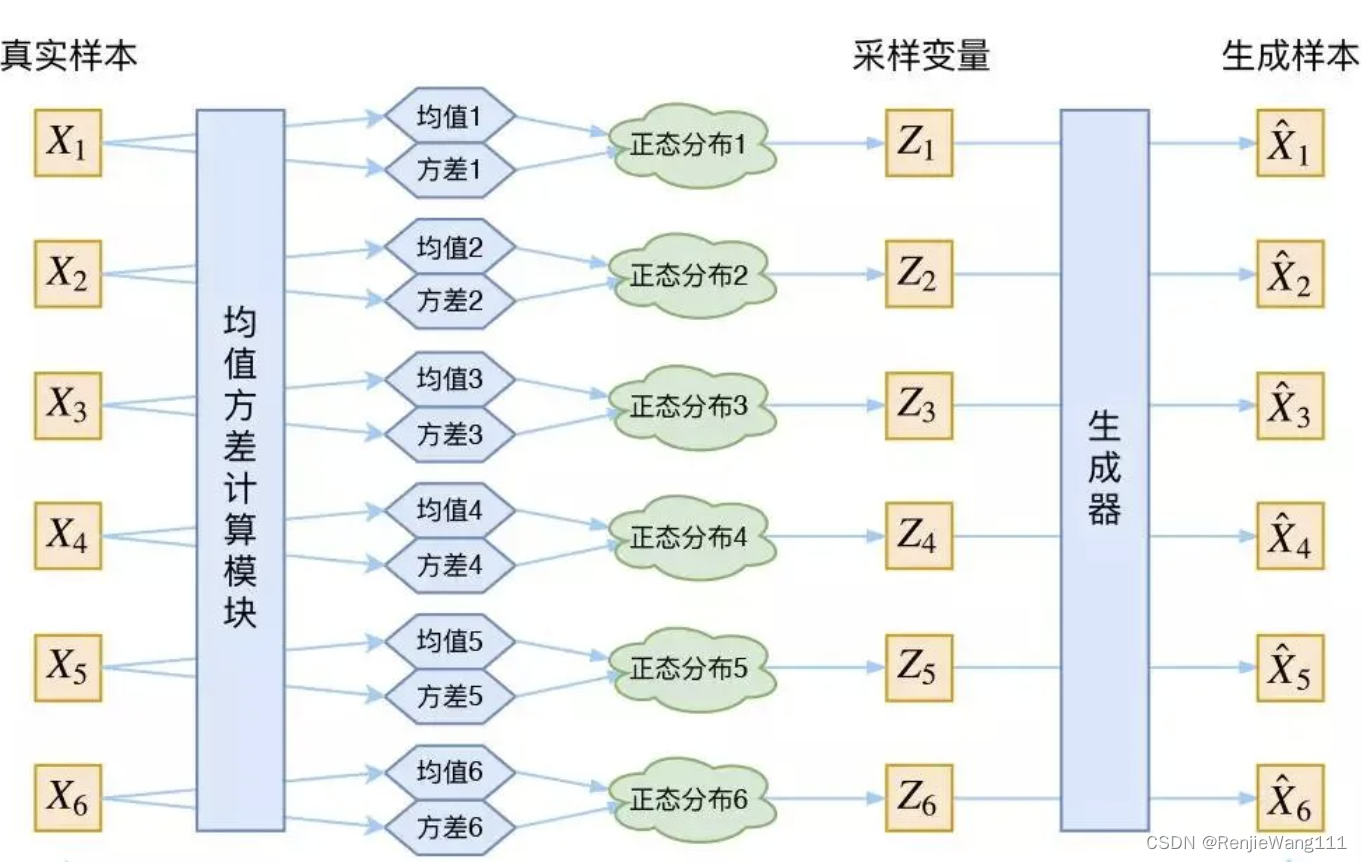
3. VAE的训练
训练过程将批量的图片送入模型中,每张图片由 Encoder 产生 μ \mu μ 和 σ \sigma σ,进而生成服从 N ( μ , σ 2 ) N\left (\mu, \sigma^2\right ) N(μ,σ2) 的隐变量 z z z,最后经过 Decoder 生成图片,整体流程如下:
x ⏟ x ∼ p ( x ) → Encoder ⏟ q ϕ ( z ∣ x ) → μ , σ → z ∼ N ( μ , σ 2 ) ⏟ z = μ + σ ⊙ ϵ , with ϵ ∼ N ( 0 , I ) ⏟ reparameterization trick → Decoder ⏟ p θ ( x ∣ z ) → x ^ \underbrace{x}_{x \sim p\left (x\right )} \rarr\underbrace{\text{Encoder}}_{q_{\phi}\left (z\vert x\right )}\rarr \mu,\sigma \rarr \underbrace{\underbrace{z\sim \mathbf{N\left (\mu,\sigma^2\right )}}_{z=\mu + \sigma \odot \epsilon, \text{with } \epsilon \sim N\left (0,I\right )}}_{\text{reparameterization trick}} \rarr \underbrace{\text{Decoder}}_{p_{\theta}\left (x\vert z\right )}\rarr\hat{x} x∼p(x) x→qϕ(z∣x) Encoder→μ,σ→reparameterization trick z=μ+σ⊙ϵ,with ϵ∼N(0,I) z∼N(μ,σ2)→pθ(x∣z) Decoder→x^
其中,训练过程中会采用重参数化技巧 (reparameterization trick) 使得整个过程可导,因为这样 μ \mu μ 和 σ \sigma σ 变成可导的参数,变化的 ϵ \epsilon ϵ 被看作不用求导的常数,不被算在梯度图中。
4. VAE的推理
推理只需要从标准正态分布中采样隐变量 z z z 即可以生成新的样本,因为 VAE 目标函数中的先验匹配项迫使 z z z 逐渐逼近标准正态分布,整体流程如下:
z ⏟ z ∼ N ( 0 , I ) → Decoder ⏟ p θ ( x ∣ z ) → x ^ ⏟ new sample \underbrace{z}_{\mathbf{z \sim N\left (0,I\right )}} \rarr \underbrace{\text{Decoder}}_{p_{\theta}\left (x \vert z\right )} \rarr \underbrace{\hat{x}}_{\text{new sample}} z∼N(0,I) z→pθ(x∣z) Decoder→new sample x^















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









