









🎈个人公众号:🎈 :✨✨✨ 可为编程✨ 🍟🍟
🔑个人信条:🔑 知足知不足 有为有不为 为与不为皆为可为🌵
🍉本篇简介:🍉本篇记录Redis缓存穿透深度剖析命令操作,如有出入还望指正。
当系统中引入redis缓存后,一个请求进来后,会先从redis缓存中查询,缓存有就直接返回,缓存中没有就去db中查询,db中如果有就会将其丢到缓存中,但是有些key对应更多数据在db中并不存在,或者缓存大批量失效了,每次针对此次key的请求从缓存中取不到,请求都会压到db,从而可能压垮db。因此本篇就针对Redis缓存使用中存在的问题进行梳理,针对问题按照代码模拟现实场景并给出解决方案。
概述
当系统中引入redis缓存后,一个请求进来后,会先从redis缓存中查询,缓存有就直接返回,缓存中没有就去db中查询,db中如果有就会将其丢到缓存中,但是有些key对应更多数据在db中并不存在,或者缓存大批量失效了,每次针对此次key的请求从缓存中取不到,请求都会压到db,从而可能压垮db。因此本篇就针对Redis缓存使用中存在的问题进行梳理,针对问题按照代码模拟现实场景并给出解决方案。
关注公众号【可为编程】回复【加群】进入微信交流群一起学习!!!
缓存穿透
缓存穿透定义
穿透,顾名思义穿透缓存肯定是到数据库了,肯定是查询数据库不存在的数据,因为如果数据库中存在,查询一遍就存入到缓存了,就不会再次和数据库进行IO操作了。正因为数据库没有数据,导致每次请求都要到数据库中,失去了缓存的意义。总结一下造成缓存穿透的条件有:
1、数据库中没有符合请求条件的数据
2、请求穿透缓存频繁请求数据库
3、每次查询的值都不在redis中
缓存穿透场景
Redis起到保护数据库的作用,提升查询效率,如果连数据库都不存在对应数据,同时也就不会写入到Redis中,频繁查询就会和数据库进行频繁IO操作。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用大量此类攻击可能压垮数据库。那么有人会想了,可不可以做个校验呢?如果缓存中不存在用户信息,那么就存一下该用户信息,保证不到数据库不就不会压垮数据库了嘛,确实是这样。
关注公众号【可为编程】回复【面试】领取年度最新面试题大全!!!
缓存穿透场景模拟
下面我根据现实的场景模拟一下,首先先去查询缓存,如果缓存不存在就去检索数据库,存在即返回。
Controller
@GetMapping("list")
public String list(@Param("id") Integer id) {
String re = redisUtils.get("test");
//2. 缓存中没有数据,查询数据库
System.out.println("缓存命中...");
if (StringUtils.isEmpty(re)) {
//2. 缓存中没有数据,查询数据款
System.out.println("缓存不命中...查询数据库");
Test test = testService.queryTest(id);
return JSON.toJSONString(test);
}
System.out.println(re);
return re;
}
service
public Test queryTest(Integer id) {
Test row = testMapper.queryTest(id);
System.out.println("查询数据库");
return row;
}
我们请求参数id传一个数据库不存在该条数据的id,肯定直接打到数据库。

数据库中也没有该数据,如果处于高并发情况下这种场景直接造成数据库宕机,因此我们可以将查询出来的null结果存入到缓存,只需要第一次查询的时候检索数据库,后面直接命中缓存返回结果。修改service。
public Test queryTest(Integer id) {
Test row = testMapper.queryTest(id);
System.out.println("查询数据库");
//查询数据库后将对象存入缓存
redisUtils.set("test", JSON.toJSONString(row));
redisUtils.expire("test", 30, TimeUnit.MINUTES);
return row;
}

第一次查询数据库并存入缓存,第二次直接查询缓存,看似没有问题,逻辑很合理,但是在高并发的场景下就会出问题了,我们采用Jmater进行压力测试,模拟100个并发请求同时请求查询接口。
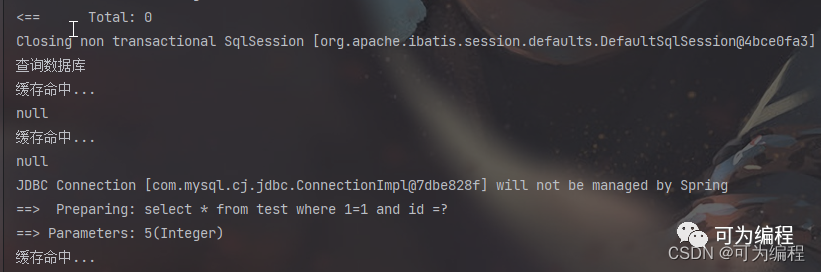
因为多线程场景下存在线程抢占机制,都在查询缓存然后查询数据库,第一个线程来了,看到缓存没有,就去查询数据库,第二个线程来了发现缓存还没有,继续查询数据库,当在查询出来数据与存入缓存环节的空隙时间内,多个请求已经打到数据库了,所以我们要保证并发情况下的操作原子性。由于springboot所有的组件都是单例的,即使有批量请求也让他访问查询和存入缓存的操作是使用同一把锁,所以可以使用synchronized (this)来加锁,第一个请求来时获取锁,查询数据库,在查询之前再次确认下缓存中是否有数据,如果没有则从数据库中查询,获取到数据后存入缓存中。
修改service方法实现
public Test queryTest(Integer id) {
//只要是同一把锁就可以锁住所有的线程
//1. synchronized (this): springboot所有的组件都是单例的,即使有批量请求也是使用同一把锁
synchronized (this) {
//关注公众号【可为编程】回复【面试】领取年度最新面试题大全!!!
//得到锁以后,应该先去缓存中确定一次,如果没有再进行查询
String test = redisUtils.get("test");
if (!StringUtils.isEmpty(test)) {
//缓存不为空直接返回
return (Test) JSON.toJSON(test);
}
//将数据库的多次查询变为一次
Test row = testMapper.queryTest(id);
System.out.println("查询数据库");
//查询数据库后将对象存入缓存
redisUtils.set("test", JSON.toJSONString(row));
redisUtils.expire("test", 30, TimeUnit.MINUTES);
return row;
}
}
我们再次执行之后就发现不会出现刚才那种场景了,只查询了一次数据库,其他请求都没有打到数据库上面。
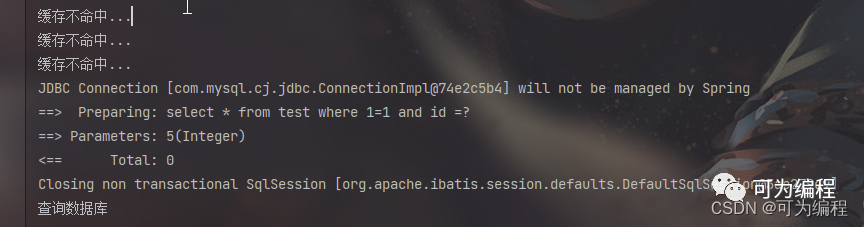
缓存不命中...
缓存不命中...
关注公众号【可为编程】回复【面试】领取年度最新面试题大全!!!
==> Parameters: 5(Integer)
从缓存中获取数据时出现异常,key:test,value:null
java.lang.NullPointerException: null
<== Total: 0
查询数据库
缓存命中...
null
缓存不命中...
缓存不命中...
缓存不命中...
缓存不命中...
缓存命中...
null
缓存命中...
null
多次执行的结果是不一样的,线程的优先级和时间片分配可能影响线程的执行顺序和时长,进而影响多线程程序的结果。在实际的生产环境中我们主要是采用消息中间件来接受并发请求,按顺序逐一进行处理,同时引入多线程提高任务执行效率。
关注公众号【可为编程】回复【面试】领取年度最新面试题大全!!!
缓存穿透解决方案
可以在缓存中存一个空字符串,或者其他特殊字符串用于标识该条为空的数据,然后当应用拿到这个特殊字符串的时候表示数据库没有值,就没必要再去查询数据库了。但是存特殊字符的办法只适用于重复查询同一个不存在的值的情况,如果每次请求,ID都是可变的,并假设ID符合规则,但是每次变化的值都不存在于数据库中,那请求还是会打到数据库中。伪代码如下:
while(true){
where id = random();
}
所以总结一下几个比较好的解决方案:
关注公众号【可为编程】回复【面试】领取年度最新面试题大全!!!
1、对空值缓存
如果一个查询返回的数据为空(不管数据库是否存在),我们仍然把这个结果(null)进行缓存,给其设置一个很短的过期时间,最长不超过五分钟。不然新增了这条数据后,查询还是查不到,保证在后续新增之后不会影响数据查询。
2、设置可访问的名单(白名单)
使用redis中的bitmaps类型定义一个可以访问的名单,名单id作为bitmaps的偏移量,每次访问和bitmap里面的id进行比较,如果访问的id不在bitmaps里面,则进行拦截,不允许访问
(3)采用布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的,它实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)。
布隆过滤器可以用于检测一个元素是否在一个集合中,它的优点是空间效率和查询的时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
将所有可能存在的数据哈希到一个足够大的bitmaps中,一个一定不存在的数据会被这个bitmaps拦截掉,从而避免了对底层存储系统的查询压力。后面会单独对其进行介绍。
(4)进行实时监控
当发现redis的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制对其提供服务(比如:IP黑名单)
今天写太慢了,明天争取将缓存雪崩和缓存击穿一起写出来,重在学习,重在消化。
















 1109
1109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











