







一.《第19课 - 编译过程简介》
1. 初识编译器
我们通常所说的编译器其实是一个广义的概念,其实它里面包含了多个子模块,编译的过程由这些子模块协作完成。

编译器的工作过程

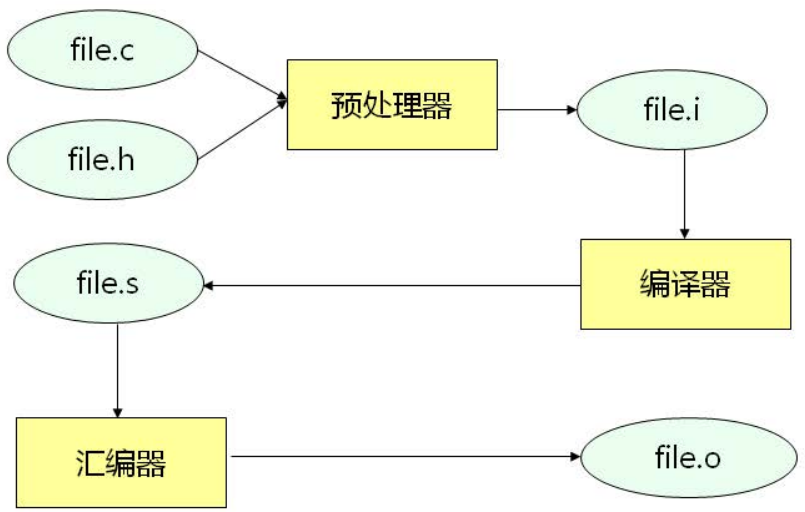
2. 编译器做了什么?
2.1 预处理
预处理由预处理器完成,预处理指令示例:gcc -E file.c -o file.i
(1)处理所有的注释,以空格代替
(2)将所有的 #define 删除,并且展开所有的宏定义
(3)处理条件编译指令 #if,#ifdef,#elif,#else,#endif
(4)处理 #include,展看被包含的文件
(5)保留编译器需要使用的 #pragma 指令
// 19-1.h
/*
This is a header file.
*/
char* p = "Hello World!";
int i = 0;// 19-1.c
#include "19-1.h"
// Begin to define macro
#define GREETING "Hello world!"
#define INC(x) x++
// End
int main()
{
p = GREETING;
INC(i);
return 0;
}gcc -E 19-1.c -o 19-1.i 的预处理结果
# 1 "19-1.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 1 "<command-line>" 2
# 1 "19-1.c"
# 1 "19-1.h" 1
char* p = "Hello World!";
int i = 0;
# 2 "19-1.c" 2
# 11 "19-1.c"
int main()
{
p = "Hello world!";
i++;
return 0;
}2.2 编译
编译由编译器(狭义)完成,编译指令示例:gcc -S file.i -o file.s
(1)对预处理文件进行词法分析、语法分析和语义分析
- 词法分析:分析关键字、标识符、立即数等是否合法
- 语法分析:分析表达式是否遵循词法规则
- 语义分析:在语法分析的基础上进一步分析表达式是否合法
(2)分析结束后进行代码优化生成相应的汇编代码文件
gcc -S 19-1.i -o 19-1.s 的预处理结果
.file "19-1.c"
.globl p
.section .rodata
.LC0:
.string "Hello World!"
.data
.align 8
.type p, @object
.size p, 8
p:
.quad .LC0
.globl i
.bss
.align 4
.type i, @object
.size i, 4
i:
.zero 4
.section .rodata
.LC1:
.string "Hello world!"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movq $.LC1, p(%rip)
movl i(%rip), %eax
addl $1, %eax
movl %eax, i(%rip)
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 4.8.4-2ubuntu1~14.04.4) 4.8.4"
.section .note.GNU-stack,"",@progbits2.3 汇编
汇编由汇编器完成,汇编指令示例:gcc -c file.s -o file.o file.o是二进制文件
(1)汇编器将汇编代码转变为机器的可执行指令
(2)每条汇编语句几乎都对应一条机器指令
2.4 链接
通过连接器生成最终的可执行文件,链接器具体是如何工作的,我将在下一篇文章中讲解。
二.《第20课 - 链接过程简介》
1. 思考一个问题
在具体工作中,每个软件项目都有很多个.c源文件,每个.c源文件经过编译后生成.o格式的目标文件,那么这些.o文件如何生成最终的可执行程序呢?
这里就要引入C语言的链接器了。
2. 链接器的作用
链接器的主要作用就是处理各个模块(目标文件和库文件)之间的相互引用,使得各个模块之间能够正确的衔接。
3. 静态链接
由链接器在链接时将库的内容直接加入到可执行程序中(库中,只有被使用的函数才会被链接进去,未使用的不会被链接到可执行程序中!)。
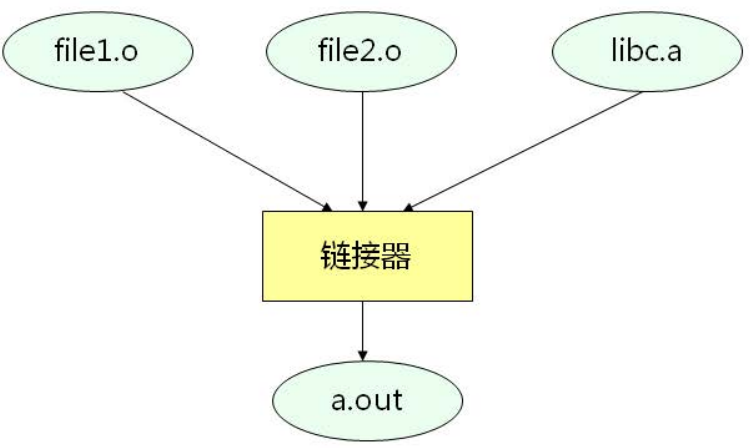
Linux下静态库的创建和使用:
- 编译静态库源码: gcc -c lib.c -o lib.o
- 生成静态库文件: ar -q lib.a lib.o
- 使用静态库编译: gcc main.c lib.a -o main.out
【slib.c静态库文件】
1 char* name()
2 {
3 return "Static Lib";
4 }
5
6
7 int add(int a, int b)
8 {
9 return a + b;
10 }
【slib.c静态库文件】【20-1.c】
1 #include <stdio.h>
2
3 extern char* name();
4 extern int add(int a, int b);
5
6 int main()
7 {
8 printf("Name: %s\n", name());
9 printf("Result: %d\n", add(2, 3));
10
11 return 0;
12 }
【20-1.c】
4. 动态链接
可执行程序在运行时才动态加载库进行链接,库的内容不会进入可执行程序当中。
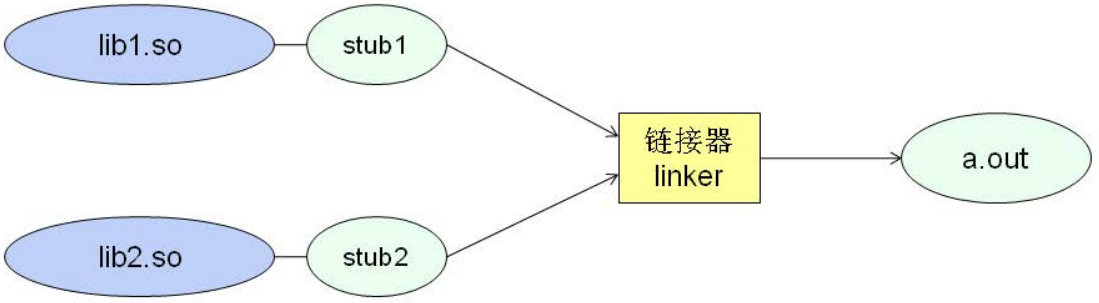
Linux下动态库的创建和使用:
- 编译动态库源码: gcc -shared -fPIC dlib.c -o dlib.so
- 使用动态库编译: gcc main.c -ldl -o main.out // 使用dlopen、dlsym、dlclose需要用到dl这个动态链接库,-ldl
- 动态库相关的系统调用
— dlopen:打开动态库文件
— dlsym: 查找动态库中的函数并返回调用地址
— dlclose:关闭动态库文件
【dlib.c动态库文件】
1 char* name()
2 {
3 return "Dynamic Lib";
4 }
5
6 int add(int a, int b)
7 {
8 return a + b;
9 }
【dlib.c动态库文件】【20-2.c】
1 #include <stdio.h>
2 #include <dlfcn.h>
3
4 int main()
5 {
6 void* pdlib = dlopen("./dlib.so", RTLD_LAZY); // 打开动态链接库
7
8 char* (*pname)(); // 定义函数指针
9 int (*padd)(int, int);
10
11 if( pdlib != NULL )
12 {
13 // 在动态链接库中查找相应的函数入口地址
14 pname = dlsym(pdlib, "name");
15 padd = dlsym(pdlib, "add");
16
17 if( (pname != NULL) && (padd != NULL) )
18 {
19 printf("Name: %s\n", pname());
20 printf("Result: %d\n", padd(2, 3));
21 }
22
23 dlclose(pdlib); // 关闭动态链接库
24 }
25 else
26 {
27 printf("Cannot open lib ...\n");
28 }
29
30 return 0;
31
32 }
【20-2.c】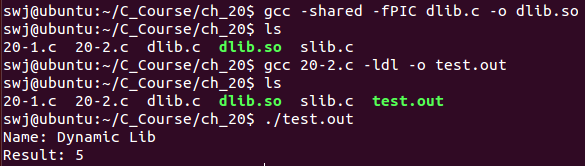
为什么需要动态链接库呢?
方便程序的更新,当程序有bug或者程序功能需要更新时,不用更新应用程序,只需要更新动态库文件即可,非常方便;如果是静态链接的话无法更新部分应用程序,需要全部重新编译!
三.《第21课 - 宏定义与使用分析》
四.《第22课 - 条件编译使用分析》
1. 基本概念
(1)c 程序的编译一般经过如下四个过程

条件编译是在预处理阶段由预处理器完成的,预处理器根据条件编译指令选择使用哪些代码。
(2)条件编译的行为类似于if ...else...语句,但他们有本质的区别。前者在预处理阶段进行分支判断,后者在程序运行期间进行分支判断
// #include <stdio.h>
#define C 1
int main()
{
const char* s;
#if( C == 1 ) // 条件成立,选择该分支
s = "This is first printf...\n";
#else
s = "This is second printf...\n";
#endif
// printf("%s", s);
return 0;
}使用 gcc -E 命令查看该程序由预处理器处理后的结果
swj@ubuntu:~/c_course/ch_22$ gcc -E test.c
# 1 "test.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 1 "<command-line>" 2
# 1 "test.c"int main()
{
const char* s;s = "This is first printf...\n";
return 0;
}
(3)除了在代码中定义宏,可以通过命令行定义宏 -D后面的宏会在预处理时传递到程序中(D是definition的缩写)
gcc –Dmacro=value file.c // 针对 #if 语句
gcc –Dmacro file.c // 针对 #ifdef 或 ifndef 语句
// 查看gcc的man手册,这种形式下macro的值为1

下面验证-D选项的功能
#include <stdio.h>
int main()
{
const char* s;
#if( C == 1 )
s = "This is first printf...\n";
#else
s = "This is second printf...\n";
#endif
printf("%s", s);
return 0;
}上面代码删除了 #define C 1,转而使用 -D选项传递宏,观察下面的编译命令及程序的输出结果
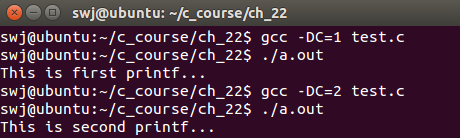
这里再添加一个细节:如果文件中没有 #define C 1 这条语句,命令行也没有使用 -DC=1,那么 gcc test.c 可以编译通过吗?实际测试是OK的。
在预处理器处理 #if( C==1 ) 这条语句时,如果没有定义C,并不会报错,而是认为 C==1 为“假”
2. #include的本质
(1)#include 的本质是将已经存在的头文件的内容嵌入到当前文件中
(2)如果#include包含的头文件中又包含了其它头文件,那么该文件的内容也会被嵌入到当前文件中
下面看一个关于#include的小例子:如下图所示,test.c中包含了test.h和global.h,而test.h又包含了global.h。

// global.h
1 int global = 10;// test.h
1 #include "global.h"
2
3 const char* NAME = "test.h";
4 char* hello_world(){return "Hello World!\n";}// test.c
// #include <stdio.h>
#include "test.h"
#include "global.h"
int main()
{
const char* s = hello_world();
int g = global;
//printf("%s\n",NAME);
//printf("%d\n",g);
return 0;
}使用gcc编译test.c,编译报错,显示重复定义了global变量,这是由于重复包含了global.h头文件导致的。
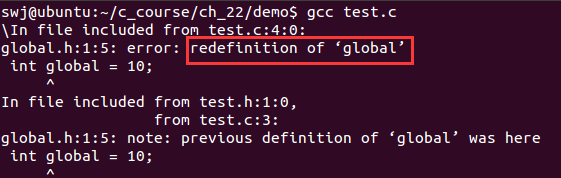
要解决上面这种由于重复包含同一个头文件,导致全局变量、函数声明、类型定义等被重复定义的错误,就需要使用条件编译。
一般格式如下:
#ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// 头文件的内容
#endif当重复包含某个头文件时,由于第一次已经定义了_HEADER_H_,第二次就不会再包含这个文件的内容了。
使用这种方法对 global.h 和 test.h 进行改造
// global.h
1 #ifndef _GLOBAL_H_
2 #define _GLOBAL_H_
3 int global = 10;
4 #endif// test.h
#ifndef _TEST_H_
#define _TEST_H_
#include "global.h"
const char* NAME = "test.h";
char* hello_world(){return "Hello World!\n";}
#endif这样当tes.c重复包含global.h时,由于条件编译的缘故,global.h的内容只会被嵌入一次,不会出现重复包含global变量的错误。
3. 条件编译的意义
(1)条件编译使得我们可以按照不同的条件编译不同的代码段,因而可以产生不同的目标代码
(2)#if...#else...#endif 被预处理器处理;而 if...else... 语句被编译器处理,必然会被编译到目标代码中
(3)实际工程中条件编译主要用于以下两种情况:
① 不同的产品线共用一份代码
② 区分编译 产品的调试版和发布版:市面上的电子产品一般有低配版、中配版、高配版,那相应的软件也要开发三个版本吗?显然不是这样的,我们一般在同一套代码中使用条件编译区分不同的版本。
【产品线区分及调试代码应用】
// product.h
1 #define DEBUG 1 // 区分版本时调试版还是发布版
2 #define HIGH 1 // 区分版本是高配版还是低配版// test.c
#include <stdio.h>
#include "product.h"
#if DEBUG
#define LOG(s) printf("[%s:%d] %s\n",__FILE__,__LINE__,s)
#else
#define LOG(s) NULL // 注意这里的写法
#endif
#if HIGH
void f()
{
printf("This is the high level product!\n");
}
#else
void f()
{
}
#endif
int main()
{
LOG("Enter main()...");
f();
printf("1. Query Information.\n");
printf("2. Record Information.\n");
printf("3. Delete Information.\n");
#if HIGH
printf("4. High Level Query.\n");
printf("5. Mannual Service.\n");
printf("6. Exit.\n");
#else
printf("4. Exit.\n");
#endif
LOG("Exit main()...");
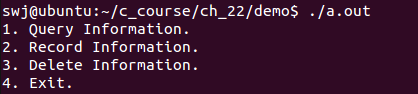
}① DEBUG为1,HIGH为1 ==> 高配调试版
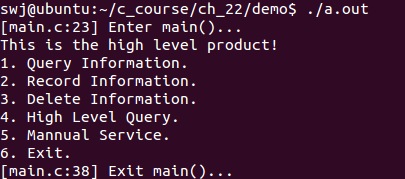
② DEBUG为0,HIGH为1 ==> 高配发布版

③ DEBUG为1,HIGH为0 ==> 低配调试版
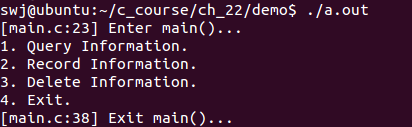
④ DEBUG为1,HIGH为0 ==> 低配发布版
五.《第23课 - #error 和 #line 使用分析》
1. #error 的用法
(1)#error 是一个预处理器指示字,用于生成一个编译错误消息,这个消息最终会传递到编译器(gcc)
在思考这一点的过程中,领悟到了两个点:
① 使用 gcc 编译代码,输出的错误(警告)信息,是由预处理器、编译器、汇编器、链接器产生的。
② gcc表示整个编译过程,它会调用 预处理器程序 -> 编译器程序 -> 汇编器程序 -> 链接器程序
(2)使用方法:#error message // 不需要在message上使用双引号
(3)#error 编译指示字用于自定义程序员特有的编译错误消息。类似的,#warning 用于生成编译警告错误
(4)#error 可用于提示编译条件是否满足。编译过程中的任何错误意味着无法生成最终的可执行程序。
下面我们通过一个示例程序来说明 #error 的用法:
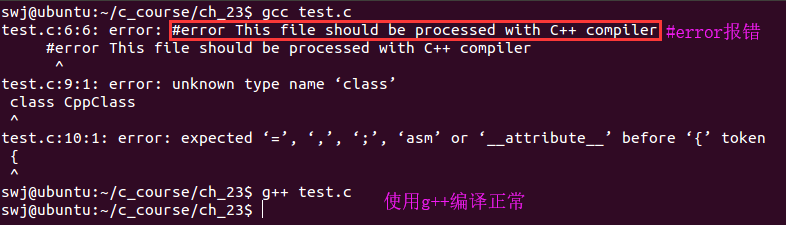
下面是一段C++ 的代码,如果我们错误的使用gcc对其进行编译就会报错
#include <stdio.h>
class CppClass
{
private:
int m_nValue;
public:
CppClass(){};
~CppClass(){};
};
int main()
{
return 0;
}使用gcc编译该代码报错

那如何解决这个问题呢?答案就是使用 条件编译 + #error
#include <stdio.h>
// __cplusplus宏是C++编译器内置的一个宏,C编译器中是没有的
// 如果使用C编译器编译该程序#error就会报编译报错
#ifndef __cplusplus
#error This file should be processed with C++ compiler
#endif
class CppClass
{
private:阿
int m_nValue;
public:
CppClass(){};
~CppClass(){};
};
int main()
{
return 0;
}
在上篇文章的最后,我们分析了一个通过条件编译区分产品版本的小程序,在那个代码中我们没有考虑一种情况,那就是如果没有定义PRODUCT这个宏会怎么样?
#include <stdio.h>
void f()
{
#if (PRODUCT == 1)
printf("This is a low level product!\n");
#elif (PROUDCT == 2)
printf("This is a middle level product!\n");
#elif (PRODUCT == 3)
printf("This is a high level product!\n");
#endif
}
int main()
{
f();
printf("1. Query Information.\n");
printf("2. Record Information.\n");
printf("3. Delete Information.\n");
#if (PRODUCT == 1)
printf("4. Exit.\n");
#elif (PRODUCT == 2)
printf("4. High Level Query.\n");
printf("5. Exit.\n");
#elif (PRODUCT == 3)
printf("4. High Level Query.\n");
printf("5. Mannual Service.\n");
printf("6. Exit.\n");
#endif
return 0;
}如果我们在编译该程序时没有通过-DPRODUCT指定这个宏的值,编译并不会报错但是执行结果就有问题了。

使用 #error 完善该程序,如果没有定义PRODUCT或者PRODUCT的值不为1、2、3中的一个,程序在编译时就会报错。
#include <stdio.h>
void f()
{
#if (PRODUCT == 1)
printf("This is a low level product!\n");
#elif (PROUDCT == 2)
printf("This is a middle level product!\n");
#elif (PRODUCT == 3)
printf("This is a high level product!\n");
#else
// 如果PRODUCT未定义或定义了但!=1 != 2 != 3
#error The PRODUCT macro is NOT defined!
#endif
}
int main()
{
f();
printf("1. Query Information.\n");
printf("2. Record Information.\n");
printf("3. Delete Information.\n");
#if (PRODUCT == 1)
printf("4. Exit.\n");
#elif (PRODUCT == 2)
printf("4. High Level Query.\n");
printf("5. Exit.\n");
#elif (PRODUCT == 3)
printf("4. High Level Query.\n");
printf("5. Mannual Service.\n");
printf("6. Exit.\n");
#else
// 如果PRODUCT未定义或定义了但!=1 != 2 != 3
#error The PRODUCT macro is NOT defined!
#endif
return 0;
}
2. #line 的用法
(1)#line 用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
(2)用法:
① #line number newFilename
② #line number // 不改变文件名,只改变行号
(3)#line 编译指示字的本质是重定义 __LINE__ 和 __FILE__
1 #include <stdio.h>
2
3 int main()
4 {
5 printf("%s : %d\n", __FILE__, __LINE__);
6
7 #line 1 "new_line.c" // 这里改变了行号和文件名,行号为1(下一行行号为1)、文件名为new_line.c(注意这里需要使用用双引号)
8
9 printf("%s : %d\n", __FILE__, __LINE__);
10
11 return 0;
12 }// 输出结果
swj@ubuntu:~/c_course/ch_23$ ./a.out line.c : 5 new_line.c : 2#line 是C语言早期的产物(在当今的软件工程中已经不使用了),那时候代码量比较小,通常放到一个文件中。如果这个程序由几个人分工协作完成的话,就是每个人先各写各的,最后再统一放到一个文件中。
那如果编译发生错误,如何知道错误的代码是谁写的呢?这个就要使用 #line 预处理指令了。
#include <stdio.h>
// The code section is written by A.
// Begin
#line 1 "a.c"
// End
// The code section is written by B.
// Begin
#line 1 "b.c"
// End
// The code section is written by Scott.
// Begin
#line 1 "scott_shi.c"
int main()
{
printf("%s : %d\n", __FILE__, __LINE__);
printf("%s : %d\n", __FILE__, __LINE__) // 这里编译会报错
return 0;
}
// End编译报错,提示是 scott_shi.c 这个文件的 第9行 发生错误,这样就定位了是哪个人写的。

六.《第24课 - #pragma 使用分析》
1. #pragma简介
(1)#pragma 是一条预处理器指令
(2)#pragma 指令比较依赖于具体的编译器,在不同的编译器之间不具有可移植性,表现为两点:
① 编译器A支持的 #pragma 指令在编译器B中也许并不支持,如果编译器B碰到这条不认识的指令就会忽略它。比如下文中介绍的 #pragma once指令,gcc编译器和VS编译器是支持的,但bcc编译器就不支持。
② 同一条 #pragma指令,不同的编译器可能会有不同的解读。
(3)一般用法:#pragma parameter // 注意,不同的 parameter参数 语法和含义是不同的
2. #pragma message指令
(1)message参数在大多数的编译器中都有相似的实现
(2)message参数在编译时输出消息到编译输出窗口中
(3)message用于条件编译可提示代码的版本信息
(4)与 #error 和 #warning不同,#pragma message仅仅代表一条编译消息,不代表程序错误。
【#pragma使用示例】
#include <stdio.h>
#if defined(ANDROID20)
#pragma message("Compile Android SDK 2.0...")
#define VERSION "Android 2.0"
#elif defined(ANDROID23)
#pragma message("Compile Android SDK 2.3...")
#define VERSION "Android 2.3"
#elif defined(ANDROID40)
#pragma message("Compile Android SDK 4.0...")
#define VERSION "Android 4.0"
#else
#error Compile Version is not provided!
#endif
int main()
{
printf("%s\n", VERSION);
return 0;
}使用 gcc 编译并观察输出结果

使用VS2010的编译器和BCC编译器分别对上述的示例代码进行编译,可以看到结果和gcc编译器的稍有不同,这也验证了上面说的,不同的编译器对同一条 #pragma 指令会有不同的解读。
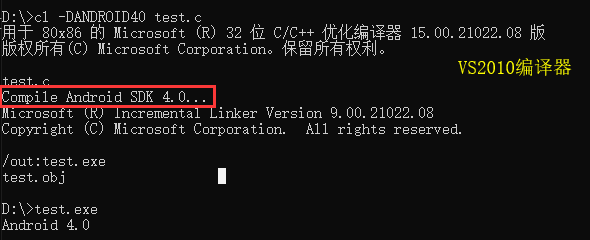

使用 gcc -E 24-1.c -DANDROID40 编译代码,发现 #pragma message 并不是在预处理的时候输出的。
# 1 "24-1.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 1 "<command-line>" 2
# 1 "24-1.c"
# 10 "24-1.c"
# 10 "24-1.c"
#pragma message("Compile Android SDK 4.0...")
# 10 "24-1.c"
int main()
{
return 0;
}此时使用 gcc -S 24-1.c -DANDROID40 编译代码,发现编译报错,说明#pragma message是由编译器(狭义)输出的。
24-1.c:10:13: note: #pragma message: Compile Android SDK 4.0...
#pragma message("Compile Android SDK 4.0...")
^
如果程序中有多个 #pragma message,由于编译器对每个c文件是自上而下编译的,所以会自上而下输出。
在做上面这个测试时,很疑惑为什么 #pragma经过预处理器处理后是原样输出,这样为啥还叫预处理指令?
咨询了唐老师,其实是自己钻了牛角尖,这里预处理器的处理方式就是将#pragma原封不动的交给编译器(狭义),不能机械的认为预处理指令完全要预处理器处理。
3. #pragma once指令
(1)#pragma once用于保证头文件只被编译一次
(2)#pragma once是编译器相关的,不一定被支持(下面的示例程序,gcc编译器和VS2010编译器可以编译通过,但BCC32编译器却编译失败)
(3)在第22课分析条件编译时,我们介绍了使用条件编译来防止头文件被多次包含。那 #pragma once 和条件编译有什么区别呢?
参考博客:十四、C高级 - 预编译关键字 #pragma |向往媛 - 网络笔记 (博客截图)

// test.c
#include <stdio.h>
#include "global.h"
#include "global.h"
int main()
{
printf("g_value = %d\n", g_value);
return 0;
}// global.h
1 #pragma once
2
3 int g_value = 1;使用 gcc 编译 ==> 编译通过
swj@ubuntu:~/c_course/ch_24$ gcc test.c swj@ubuntu:~/c_course/ch_24$ ./a.out g_value = 1
使用 VS2010 编译 ==> 编译通过
D:\>cl test.c
用于 80x86 的 Microsoft (R) 32 位 C/C++ 优化编译器 15.00.21022.08 版
版权所有(C) Microsoft Corporation。保留所有权利。test.c
Microsoft (R) Incremental Linker Version 9.00.21022.08
Copyright (C) Microsoft Corporation. All rights reserved./out:test.exe
test.objD:\>test.exe
g_value = 1
使用 BCC32 编译 ==> 编译失败
D:\>bcc32 test.c Borland C++ 5.5.1 for Win32 Copyright (c) 1993, 2000 Borland test.c: Error E2445 global.h 4: Variable 'g_value' is initialized more than once // g_value重定义 *** 1 errors in Compile ***
BCC32编译器不支持 #pragma once,遇到 #pragma once之后直接忽略它。
在实际工程中,如果既想有效率又想有移植性,那怎么做呢?一般使用如下的做法。
#pragma once
ifndef _HEADER_FILE_H_
#define _HEADER_FILE_H_
// source code
#endif(1)什么是内存对齐?
不同类型的数据在内存中按照一定的规则排列,而不一定是顺序的一个接一个的排列。
我们看下面这个例子,struct Test1 和 struct Test2 的成员都是相同的,只是在结构体中的位置不同,那两个结构体占用的内存大小相同吗?
#include <stdio.h>
#pragma pack(2)
struct Test1
{
char c1;
short s;
char c2;
int i;
};
#pragma pack()
#pragma pack(4)
struct Test2
{
char c1;
char c2;
short s;
int i;
};
#pragma pack()
int main()
{
printf("sizeof(Test1) = %zu\n", sizeof(struct Test1));
printf("sizeof(Test2) = %zu\n", sizeof(struct Test2));
return 0;
}程序的输出结果如下,可见两个结构体的大小并不相同!!!

(2)为什么需要内存对齐?
① CPU对内存的读取不是连续的,而是分成块读取的,块的大小只能是1、2、4、8、16...字节
② 当读取操作的数据未对齐,则需要两次总线周期来访问内存,此性能会大打折扣
③ 某些硬件平台只能从规定的相对地址处读取特定类型的数据,否则产生硬件异常
(3)#pragma pack( )的功能
#pragma pack( ) 可以改变编译器的默认对齐方式(编译器默认为4字节对齐)
下面我们介绍结构体内存对齐的规则(重要!重要!重要!)
- 第一个成员起始于 0偏移处
- 对齐参数:每个结构体成员按照 其类型大小 和 pack参数 中较小的一个进行对齐(如果该成员也为结构体,那就取其内部长度最大的数据成员作为其大小)
- 偏移地址必须能够被对齐参数整除 (0可以被任何非0的整数整除)
- 结构体总长度必须为所有对齐参数的整数倍
我们根据这个规则来分析一下前面 struct Test1 和 struct Test2 结构体
#pragma pack(2) // 以2字节对齐
struct Test1
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
short s; // 2 2 2
char c2; // 1 4 1
int i; // 2 6 4
}; // 在2字节对齐下,该结构体大小为10字节
#pragma pack()
#pragma pack(4) // 以4字节对齐
struct Test2
{ // 对齐参数 偏移地址 大小
char c1; // 1 0 1
char c2; // 1 1 1
short s; // 2 2 2
int i; // 4 4 4
}; // 在4字节对齐下,该结构体大小为8字节
#pragma pack()分析结果和前面程序的输出结果相同,结构体成员在内存中的位置如下图所示:
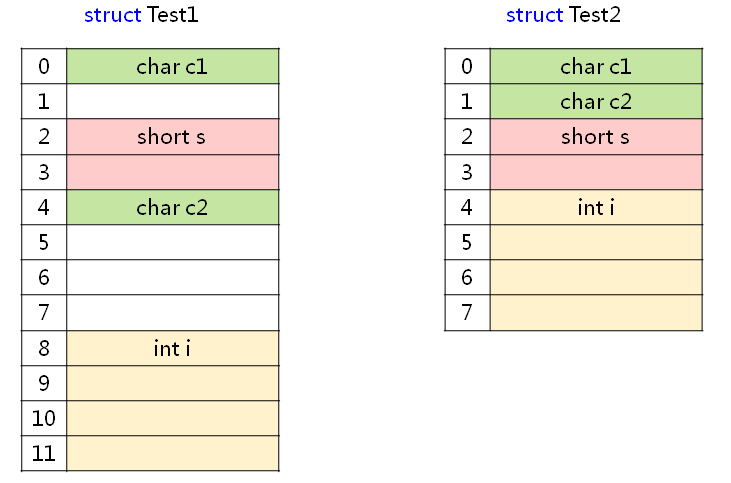
上面这个例子比较简单,我们再来看一下微软的一道笔试题
#include <stdio.h>
#pragma pack(8) // 以8字节对齐
struct S1
{ // 对齐参数 偏移地址 大小
short a; // 2 0 2
long b; // 8 8 8
}; // 在8字节对齐下,该结构体大小为16字节
struct S2 // 结构体中包含了一个结构体成员,取其内部长度最大的数据成员作为其大小
{ // 对齐参数 偏移地址 大小
char c; // 1 0 1
struct S1 d; // 8 8 16
double e; // 8 24 8
}; // 在8字节对齐下,该结构体大小为32字节
#pragma pack()
int main()
{
printf("%d\n", sizeof(struct S1));
printf("%d\n", sizeof(struct S2));
return 0;
}使用gcc编译,程序执行结果如下,和我们分析的结果相同

【这里和唐老师课程中的结果不同,唐老师使用的编译器不支持8字节对齐,即 #pragma pack(8),我的这个gcc支持。】
我们再使用 VS2010编译器 和 BCC32编译器 测试一下上面的代码
VS2010编译器
D:\>cl test.c
用于 80x86 的 Microsoft (R) 32 位 C/C++ 优化编译器 15.00.21022.08 版
版权所有(C) Microsoft Corporation。保留所有权利。test.c
Microsoft (R) Incremental Linker Version 9.00.21022.08
Copyright (C) Microsoft Corporation. All rights reserved./out:test.exe
test.objD:\>test.exe // 这里和gcc结果不同是因为在该平台下sizeof(long) = 4
8
24
BCC32编译器
D:\>bcc32 test.c
Borland C++ 5.5.1 for Win32 Copyright (c) 1993, 2000 Borland
test.c:
Turbo Incremental Link 5.00 Copyright (c) 1997, 2000 BorlandD:\>test.exe // 这里和gcc结果不同是因为在该平台下sizeof(long) = 4
8
24
七.《第25课 - # 和 ## 操作符使用分析》
1. # 运算符
(1)# 运算符用于在预处理期将宏参数转换为字符串,即加上双引号 (# 运算符的操作对象是宏参数)
(2)# 的转换作用是在预处理期完成的,因此只在宏定义中有效;编译器并不知道 # 的转换作用
(3)在有参宏中,# 只能和宏参数连用,不能和其它东西连用,比如 #define INC(i) {i++; #hhh} // 这个预处理器会报错,error: '#' is not followed by a macro parameter
#include <stdio.h>
#define STRING(x) #x // 将宏参数x转换为字符串
int main()
{
printf("%s\n", STRING(Hello World!)); // "Hello World!"
printf("%s\n", STRING(100)); // "100"
printf("%s\n", STRING(while)); // "while"
printf("%s\n", STRING(return)); // "return"
return 0;
}gcc -E 25-1.c 查看预处理结果,可以看到宏参数转变为了字符串格式
scott@scott-ubuntu:~/c_course/ch_25$ gcc -E 25-1.c
# 1 "25-1.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 1 "<command-line>" 2
# 1 "25-1.c"
int main()
{
printf("%s\n", "Hello World!");
printf("%s\n", "100");
printf("%s\n", "while");
printf("%s\n", "return");
return 0;
}【# 运算符的妙用】
#include <stdio.h>
// 打印被调用的函数的函数名,然后调用该函数
#define CALL(f,p) (printf("Call function %s\n",#f),f(p))
int square(int n)
{
printf("Call function %s\n", __func__)
return n*n;
}
int func(int x)
{
return x;
}
int main()
{
int iRet = 0;
iRet = CALL(square, 4); // Call function square
printf("result = %d\n", iRet); // result = 16
iRet = CALL(func, 10); // Call function func
printf("result = %d\n", iRet); // result = 10
return 0;
}2. ## 运算符
(1)## 运算符用于在预处理期粘连两个标识符 (## 运算符的操作对象是标识符)
(2)## 的连接作用是在预处理器完成的,因此只在宏定义中有效;编译器并不知道 ## 的连接作用
【## 运算符的基本用法】
#include <stdio.h>
#define NAME(n) name##n
int main()
{
int NAME(1); // name1;
int NAME(2); // name2;
NAME(1) = 1;
NAME(2) = 2;
printf("%d\n", NAME(1)); // 1
printf("%d\n", NAME(2)); // 2
return 0;
}【## 运算符的工程应用】
#include <stdio.h>
/*
typedef struct _tag_Student Student;
struct _tag_Student {
int id;
char *name;
};
*/
// 当工程中有很多结构体时,这样可以提高代码编写效率
#define Struct(arg) typedef struct _tag_##arg arg;\
struct _tag_##arg
Struct(Student) {
int id;
char *name;
};
int main()
{
Student s1;
Student s2;
s1.id = 0;
s1.name = "Scott";
s2.id = 0;
s2.name = "Fugui";
printf("s1.id = %d\n", s1.id);
printf("s1.name = %s\n", s1.name);
printf("s2.id = %d\n", s2.id);
printf("s2.name = %s\n", s2.name);
return 0;
}














 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









