







音频编解码
音频编码
编码流程
音频编码用于把PCM数据通过一定编码器压缩成对应的数据。
 编码架构
编码架构
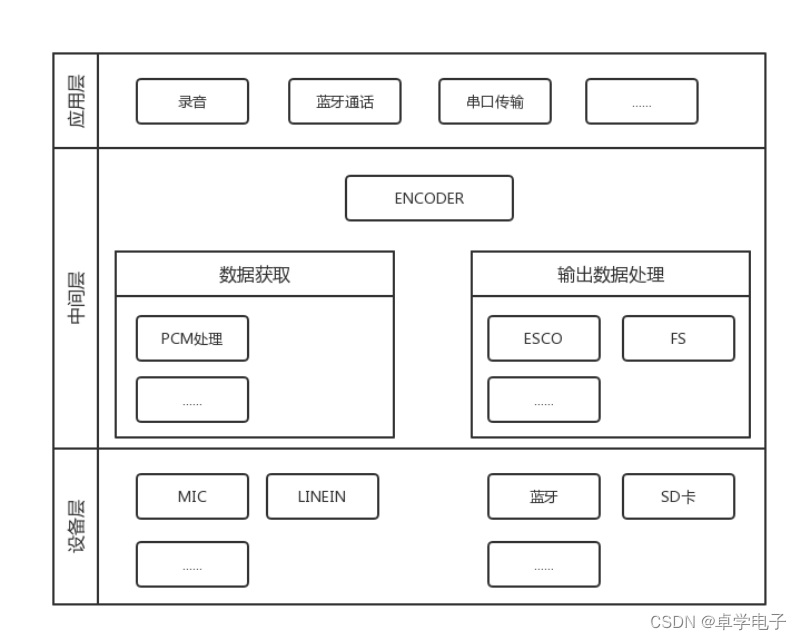
音频解码
音频解码 用于把数据通过一定解码器转换成PCM数据。
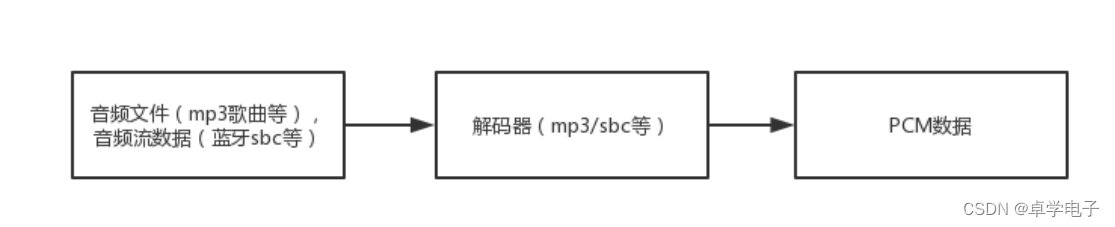
解码架构

编解码格式
按压缩程度区分:
不压缩的格式(UnCompressed Audio Format):PCM数据、wav(PCM类型)。
无损压缩格式(Lossless Compressed Audio Format):FLAC、APE、dts、m4a。
有损压缩格式(Lossy Compressed Audio Format):mp3、wma、wav(ADPCM等
按数据来源区分:
流媒体格式(一帧一帧的数据):sbc、msbc、cvsd、aac。
文件格式(音频文件):mp3、wav、wma、flac、ape、m4a、amr、dts、alac。
既可以用于流媒体解码又可以用于文件解码的格式:MSBC
按技术标准区分:
标准格式(国际通用):mp3、wav、wma、flac、ape、m4a、sbc、msbc、cvsd。
自定义格式(仅本司SDK可以使用):G729(wtg)、G726、MTY、wtgv2。
文件名后缀
一般音频格式都有其固定的文件名后缀,如mp3格式:123.mp3
同一文件名后缀,格式可能不同。如wav后缀,可能是adpcm或者dts格式;mp4后缀,可能是m4a或者alac格式。
同一格式,文件名后缀也可能不同。如dts格式,可能是dts或者wav后缀。
格式检查
一般流媒体格式的数据不需要做格式检查,由应用层指定解码格式,如sbc等。
文件解码格式会有格式检查,格式检查正确后才使用对应的解码器解码,如wma等。
mp3的格式检查较弱,如果是其他格式的音频(如wav)使用mp3解码器格式检查,也有可能检查正确,因此,mp3解码器应放在最后检查
空间冲突
代码里面的空间分配在sdk_ld.c中,编译之后的空间占用可以在sdk.map中查看。
overlay里面的空间是共用的,同时只能一个分支。比如正在使用overlay_wma的时候就不能同时使用overlay_mp3,因此假设需要用mp3解码做提示音的时候,就需要把overlay_mp3中的mp3_mem等段定义全部放到非overlay区域中去。
音频数据流
数据流简介
数据流 是一串连续不断的数据的集合,就象水管里的水流,在水管的一端一点一点地供水,而在水管的另一端看到的是一股连续不断的水流。

示例:
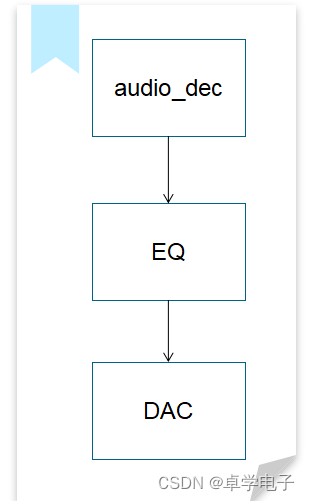
// 数据流节点初始化
audio_decoder_open(&audio_dec.decoder); // 打开解码任务
audio_eq_open(&eq); // 打开eq
audio_dac_new_channel(&dac_hdl, &default_dac); // 打开DAC
// 创建数据流
stream = audio_stream_open(&audio_dec.decoder, stream_resume_cb);
// 数据流串联
struct audio_stream_entry *entries[4];
entries[0] = &audio_dec.decoder.entry;
entries[1] = &eq.entry;
entries[2] = &default_dac.entry;
audio_stream_add_list(stream, entries, 3);
音频数据流分流处理
分流 是在原数据流的基础上拷贝一份数据,从这份数据开始重新创建一条新的数据流。
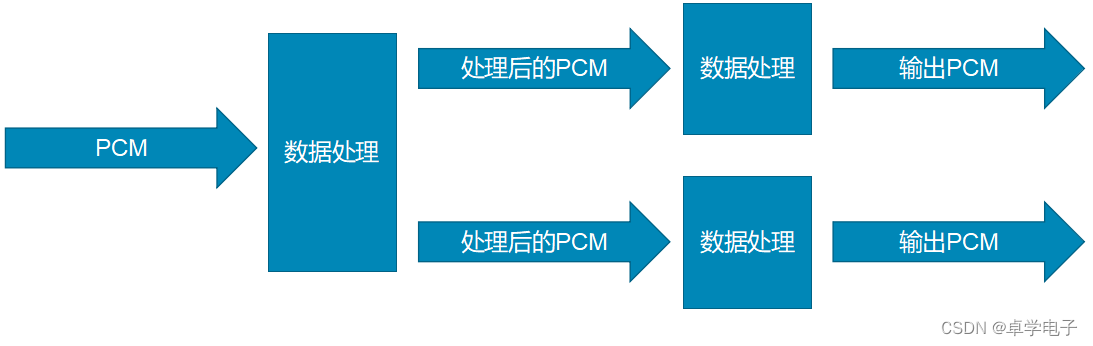
示例:
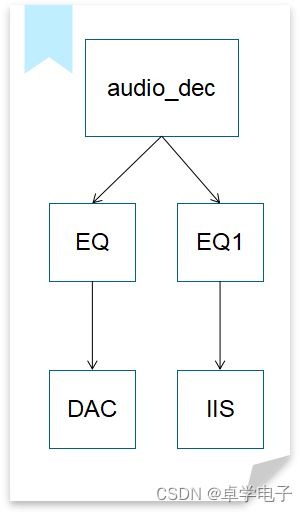
// 数据流节点初始化
audio_decoder_open(&audio_dec.decoder); // 打开解码任务
audio_eq_open(&eq); // 打开eq
audio_eq_open(&eq1); // 打开eq1
audio_dac_new_channel(&dac_hdl, &default_dac); // 打开DAC
audio_iis_open(&iis); // 打开IIS
// 创建数据流
stream = audio_stream_open(&audio_dec.decoder, stream_resume_cb);
// 添加解码
audio_stream_add_first(stream, &audio_dec.decoder.entry);
// 添加解码第一路输出流
audio_stream_add_entry(&audio_dec.decoder.entry, &eq.entry);
audio_stream_add_entry(&eq.entry, &default_dac.entry);
// 添加解码第一路输出流
audio_stream_add_entry(&audio_dec.decoder.entry, &eq1.entry);
audio_stream_add_entry(&eq1.entry, &iis.entry);
音频数据流群组处理
群组 是把多个数据流关联上,当激活尾部的数据流时,能依次激活群组里面的其他数据流。
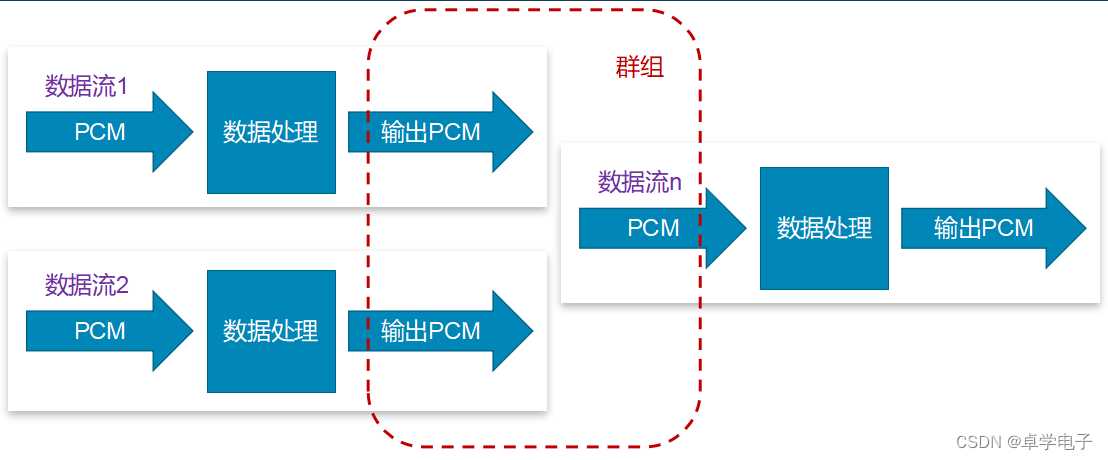
示例:
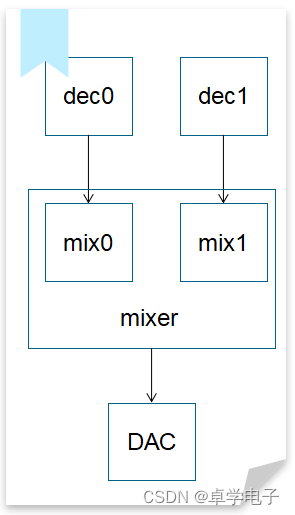
// 创建数据流
stream0 = audio_stream_open(&dec0.decoder, stream0_resume_cb);
stream1 = audio_stream_open(&dec1.decoder, stream1_resume_cb);
stream_n = audio_stream_open(&mixer.decoder, stream_n_resume_cb);
// 数据流0
audio_stream_add_first(stream0, &dec0.decoder.entry);
audio_stream_add_entry(&dec0.decoder.entry, &mix0.entry);
// 数据流1
audio_stream_add_first(stream1, &dec1.decoder.entry);
audio_stream_add_entry(&dec1.decoder.entry, &mix1.entry);
// 数据流n
audio_stream_add_first(stream_n, &mixer.entry);
audio_stream_add_entry(&mixer.entry, &default_dac.entry);
// 关联数据流,把数据流n作为群组的尾部数据流
audio_stream_group_add_entry(&test_group, &mix0.entry);
audio_stream_group_add_entry(&test_group, &mix1.entry);
mixer.entry.group = &test_group;
注意事项
1.自定义数据流节点 - 输入输出buf相同
输入输出buf相同是指数据流节点直接更改 in->data 里面的内容,不使用额外的buf来作为输出,例如数字音量处理。
// 数据处理
static int demo_data_handler(struct audio_stream_entry *entry,
struct audio_data_frame *in,
struct audio_data_frame *out)
{
struct demo_hdl *demo = container_of(entry, struct demo_hdl, entry);
// 设置输出信息,这里输出和输入相同
out->data = in->data;
out->data_len = in->data_len;
if (in->data_len - in->offset > 0) {// 数据处理
demo_deal(demo, in->data + in->offset / 2, in->data_len - in->offset);
}
return in->data_len;
}
2.自定义数据流节点 - 输入输出buf不同
输入输出buf不同是指数据流节点处理后,用额外的buf来保存输出数据,例如变采样处理。
static int demo_data_handler(struct audio_stream_entry *entry,
struct audio_data_frame *in,
struct audio_data_frame *out)
{
struct demo_hdl *demo = container_of(entry, struct demo_hdl, entry);
out->sample_rate = demo->out_sr;// 设置输出信息
if (demo->remain_len) {// 输出剩余数据
out->data_len = demo->remain_len;
out->data = demo->remain_buf;
return 0;
}
int len = demo_deal(demo, in->data, in->data_len);// 数据处理
out->data_len = demo->remain_len;// 更改信息
out->data = demo->remain_buf;
return len;
}
3.添加数据流节点1
以数组方式添加节点,调用audio_stream_add_list()函数添加。该方式可以快速把多个节点链接在一起,方便更改顺序等。
// 数组方式添加节点
struct audio_stream_entry *entries[8] = {NULL};
u8 entry_cnt = 0;
entries[entry_cnt++] = &dec->decoder.entry;
entries[entry_cnt++] = &dec->eq_drc->entry;
entries[entry_cnt++] = &default_dac->entry;
audio_stream_add_list(dec->stream, entries, entry_cnt);
4.添加数据流节点2
以单个方式依次添加节点,调用audio_stream_add_entry()函数添加。该方式的第一个节点需要用audio_stream_add_first()函数。
// 单个方式依次添加节点
audio_stream_add_first(dec->stream, &dec->decoder.entry);
audio_stream_add_entry(&dec->decoder.entry,
&dec->eq_drc->entry);
audio_stream_add_entry(&dec->eq_drc->entry,
&default_dac->entry);
5.添加数据流节点3
在原数据流中添加节点。调用audio_stream_add_head()/audio_stream_add_tail()函数添加。该方式用于在已经创建好的数据流链表中加入节点,所有方式的添加都是在数据流使用之前处理。
// 在原数据流中添加节点
audio_stream_add_head(dec->stream, &dec->eq_drc1->entry);
audio_stream_add_tail(dec->stream, &dec->dac->entry);
6.参数处理
数据流节点处理函数中,*in参数带有一些音频信息,如:采样率、声道等。当前数据流节点对于信息敏感的,需要处理该参数。例如eq处理。
static int eq_data_handler(struct audio_stream_entry *entry,
struct audio_data_frame *in,
struct audio_data_frame *out)
{
struct eq_hdl *eq = container_of(entry, struct eq_hdl, entry);
if (eq->sr != in->sample_rate) {//参数判断
eq->sr = in->sample_rate;
audio_eq_set_samplerate(eq, eq->sr);
}
int len = eq_deal(eq, in->data, in->data_len);// 数据处理
out->data_len = eq->remain_len;// 更改信息
out->data = eq->remain_buf;
return len;
}
7.本次没输出完,下次继续输出
数据流节点处理本次没有输出完成的情况下,下次数据流过来应该先输出上一次的剩余数据,全部输出完后才继续处理。
// data_handler函数里的处理
if (demo->remain_len) { // 输出剩余数据
struct audio_data_frame frame;
memcpy(&frame, in, sizeof(frame));// 复制原输出信息
// 更改信息
frame.sample_rate = demo->out_sr;
frame.data_len = demo->remain_len;
frame.data = demo->remain_buf;
audio_stream_run(entry, &frame);// 数据流输出
if (demo->remain_len) {// 还没输出完,退出
return 0;
}
}
// 数据处理
int len = demo_deal(demo, in->data, in->data_len);
8.激活机制
数据流节点处理处理数据时,如果本次不能处理完全部的 in->data_len数据,那么上层应用应该挂起该数据流。当该节点可以再次处理时激活数据流。如果是后级数据流无法输出,则由后级无法输出的数据流节点激活。
static int demo_data_handler(struct audio_stream_entry *entry,
struct audio_data_frame *in,
struct audio_data_frame *out)
{
struct demo_hdl *demo = container_of(entry, struct demo_hdl, entry);
run_len = in->data_len > 512 ? 512 : in->data_len;
demo->need_resume = (run_len == in->data_len) ? 0 : 1;
demo_deal(demo, in->data, run_len);// 处理数据
out->data_len = run_len;
out->data = demo->buf;
return len;
}
// 当可以再次处理的时候再激活
if (demo->need_resume) {
audio_stream_resume(&demo->entry);
}
音效处理
声音的特性
音调 是指声音的高低,就是我们平时所说的高音,低音。音调由物体振动的频率决定的,频率越高,声音的音调就越高,反正,音调则低。

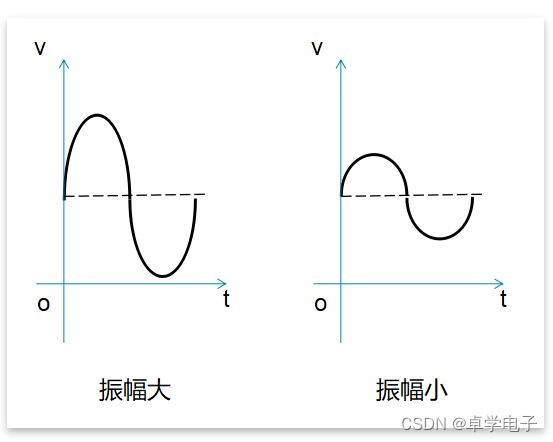
响度 是指声音的强弱,也就是我们日常生活中常说的声音的大小。声音的响度是由物体振动时的振幅决定的。
音色 是指声音的特色、品质,由声音波形的谐波频谱和包络决定。主要与发声体的材料、结构有关。同样是演奏《梁祝》,我们却能听出二胡演奏和钢琴演奏的不同,因为二者的结构不同,发出声音的音色不同。
音效处理简介
音效处理就是把一段音频进行二次编辑,达到改变音乐风格等目的。
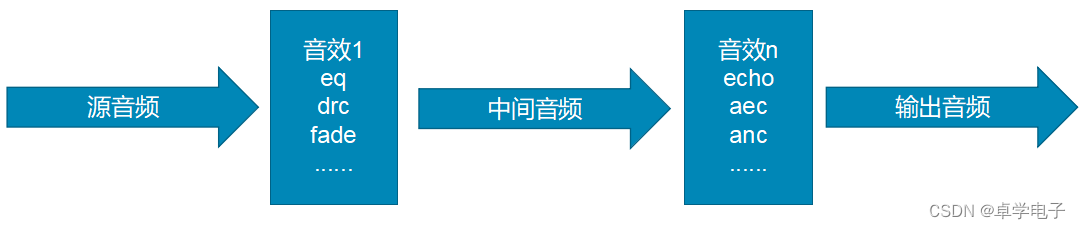
更改音调、响度
1.简单的更改声音的音调就可以达到声音变化的效果。比如,把一段48Khz的音频改用8Khz来播放,就可以达到类似树懒(疯狂动物城,闪电)说话的效果。
2.更改声音的响度是改变了声音的大小。一般我们会针对不同的频率来调节响度,比如,把低频的响度增加,就可以达到重低音的效果。
高级处理
一般采用叠加的方式来处理音频。
叠加相对独立的音频,比如KTV里面的麦克风和音乐背景声的叠加。
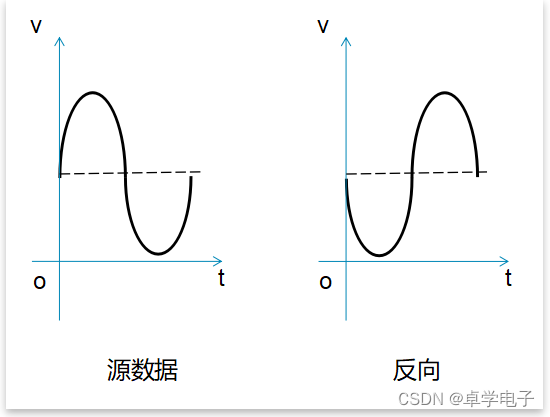
叠加反向音频,这种情况下音频会被消除,比如接打电话时的降噪功能。
反复叠加某一段音频,这种就是混响(回声)的工作机制。
补充 - 相位
相位 (phase)是对于一个波,特定的时刻在它循环中的位置:一种它是否在波峰、波谷或它们之间的某点的标度。相位发生在周期性的运动之中。相位最直接的理解是角度。这个角度存在于匀速圆周运动之中。实际应用过程中,可能会用到相位处理来辅助其他音效处理。比如做麦克风降噪的时候,就用到反向相位来消除噪声。
音效示例-EQ\DRC
EQ 均衡器(Equalizer),用来调节音频中各种频率的幅度值。比如通过调节eq来得到重低音、流行音等音效。也用于补偿喇叭、麦克风等物理元器件引起的缺陷
DRC Dynamic Range Control动态范围控制提供压缩和放大能力。一般用于eq之后,防止eq调节幅度太大溢出。
音效示例-高低音
高低音 是EQ/DRC的一种简单应用,仅调节音频的高音和低音两个频点(默认125Hz、12000Hz)。
音效示例-混响、回音
混响 reverberation(残响),当一个声音发出后,当它碰到障碍物后会反射,碰到下一个障碍物会再反射,不停反射直至它的能量消失为止。这个持续在空间中反覆反射动作形成的声音集成,就是残响。
回音 echo算是混响的一种,当回声与原始声音直接的间隔较大时,如 >200ms,我们耳朵能分辨出两个声音的就是 Echo
音效示例-噪声抑制
噪声抑制 noisegate,这里是指混响过程中的麦克风声音门限处理。
音效示例-啸叫抑制
啸叫抑制 howling suppression。声源与扩音设备之间因距离过近等问题导致能量发生自激,产生啸叫。啸叫不仅会影响听觉,也会烧坏音响设备。技术上通过移频器(升高或降低输入音频信号的频率,改变频率的输出信号再次进入系统不会和原始信号频率叠加)、陷波器(通过降低啸叫频率点处增益,破坏啸叫产生的增益条件)等方式抑制啸叫。
音效示例-变声
变声 pitch,通过改变声音的频率等达到变速变调的效果,如女声变男声、怪兽音等。
环绕音 surround,是指通过放置音源于不同的位置,通过解码器解码,把声音按照不同时间在不同的音箱里播放出来。环绕声完美地再现声音的层次感,增加了听者对临场感的体验。这里指利用现代电声技术在不改变左右声道扬声器位置的情况下,对左右声道的各频率成分的音量与相位分别进行调节,形成音响的全方位的空间立体感
等响度 equalloudness。声音实际响度和人耳实际感受的响度并不完全呈线性关系,在小音量的时候,人耳对中高频的听觉会有生理性衰减,音量越小,这种衰减越明显。等响度控制其作用是在低音量时提升高频和低频成分的音量,使得低、中、高部分的响度比例保持和在大音量时的响度比例相同
音效示例-人声消除
人声消除 vocal_remove,是一种可以将立体声歌曲的人声消除的技术。人声的声波波形在歌曲的两个声道是相同或者相似的,因此,我们可以简单采取两个声道相减的办法来消除立体声歌曲中的人声。但是,这样做有时会损失歌曲中的低音。因此,常用的人声消除会对低音进行补偿等。
ENC Environmental Noise Cancellation,环境降噪技术,能有效抑制反向环境噪声。我们主要通过agc 数字放大、aec 回声消除、es 回声压制、ans 降噪模块等技术手段实现降噪功能。
ANC Active Noise Control,主动降噪,是麦克风收集外部的环境噪音,通过机器学习等方式,把环境噪声变换为一个反相的声波加到喇叭端,最终人耳听到的声音是:环境噪音+反相的环境噪音,两种噪音叠加从而实现感官上的噪音降低。















 3805
3805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









