







SVM(一)
简介:
支持向量机(Support Vector Machine,SVM)是一个功能强大且全面的机器学习模型,它能够执行线性或非线性分类、回归,甚至是异常值检测任务。它是机器学习领域最受欢迎的模型之一,SVM特别适用于中小型复杂数据集的分类。
线性SVM分类
SVM的基本思想可以用一些图来说明。左图显示了三种可能的线性分类器的决策边界。其中虚线所代表的模型表现非常糟糕,甚至都无法正确实现分类。其余两个模型在这个训练集上表现堪称完美,但是它们的决策边界与实例过于接近,导致在面对新实例时,表现可能不会太好。相比之下,右图中的实线代表SVM分类器的决策边界,这条线不仅分离了两个类,并且尽可能远离了最近的训练实例。你可以将SVM分类器视为在类之间拟合可能的最宽的街道(平行的虚线所示)。因此这也叫做大间隔分类。

请注意,在“街道以外”的地方增加更多训练实例不会对决策边界产生影响,也就是说它完全由位于街道边缘的实例所决定(或者称之为“支持”)。这些实例被称为支持向量。
软间隔分类
如果我们严格地让所有实例都不在街道上,并且位于正确的一边,这就是硬间隔分类。
硬间隔分类有两个主要问题:
-
它只在数据是线性可分离的时候才有效;
-
它对异常值非常敏感
下图显示了有一个额外异常值的鸢尾花数据:左图的数据根本找不出硬间隔,而右图最终显示的决策边界与我们在上图中所看到的无异常值时的决策边界也大不相同,可能无法很好地泛化。
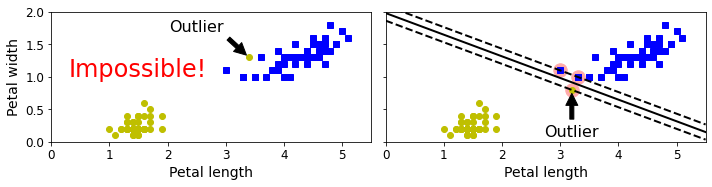
要避免这些问题,最好使用更灵活的模型。目标是尽可能在保持街道宽阔和限制间隔违例(即位于街道之上,甚至在错误的一边的实例)之间找到良好的平衡,这就是软间隔分类。
使用Scitkit-Learn创建SVM模型时,我们可以指定许多超参数。C是这些超参数之一。如果将其设置为较低的值,则最终得到左图的模型。如果设置为较高的值,我们得到右边的模型。间隔冲突很糟糕,通常最好要少一些。但是,在这种情况下,左侧的模型存在很多间隔违例的情况,但泛化效果可能会更好。

如果你的模型过拟合,可以尝试通过降低C来对其进行正则化。
以下Scikit-Learn代码可加载鸢尾花数据集,缩放特征,然后训练线性SVM模型(使用C=1的LinearSVC类和稍后描述的hinge损失函数)来检测维吉尼亚鸢尾花。
import numpy as np
from sklearn import datasets
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
iris = datasets.load_iris()
X = iris["data"][:,(2,3)] # petal length, petal width
y = (iris["target"] == 2).astype(np.float64) # Iris virginica
svm_clf = Pipeline([
("scaler", StandardScaler()),
("linear_svc", LinearSVC(C=1, loss="hinge")),
])
svm_clf.fit(X,y)生成的模型如左图所示。
你可以像往常一样使用模型进行预测:
>>> svm_clf.predict([5.5, 1,7]) array([1.])
与Logistic回归分类器不同,SVM分类器不会输出每个类的概率。
我们可以将SVC类与线性内核一起使用,而不使用LinearSVC类。创建SVC模型时,我们可以编写SVC(kernel = "linear", C = 1)。或者我们可以将SGDClassifier类与SGDClassifier(loss="hinge", alpha=1/(m*C))一起使用。这将使用常规的随机梯度下降来训练线性SVM分类器。它的收敛速度不如LinearSVC类,但是对处理在线分类任务或不适合内存的庞大数据集(核外训练)很有用。
LinearSVC类会对偏置项进行正则化,所以你需要先减去平均值,使训练集居中。如果使用StandardScaler会自动进行这一步。此外,请确保超参数loss设置为"hinge",因为它不是默认值。 最后,为了获得更好的性能,还应该将超参数dual设置为False,除非特征数量比训练实例还多。
非线性SVM分类
虽然在许多情况下,线性SVM分类器是有效的, 并且通常出人意料地好,但是,有很多数据集远不是线性可分离的。处理非线性数据集的方法之一是添加更多特征,比如多项式特征。某些情况下,这可能导致数据集变得线性可分离。参加左图:这是一个简单的数据集,只有一个特征X1,,可以看出数据集线性不可分。但是如果添加第二个特征X2=(X1)²,生成的2D数据集则完全线性可分离。

通过添加特征使数据集线性可分离















 275
275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









