






文章7成内容参考:解码注意力Attention机制:从技术解析到PyTorch实战
还有3成内容参考:深度学习基础算法系列(21)-一文搞懂注意力机制(Attention )【原来如此】深度学习中注意力机制(attention)的真实由来_哔哩哔哩_bilibili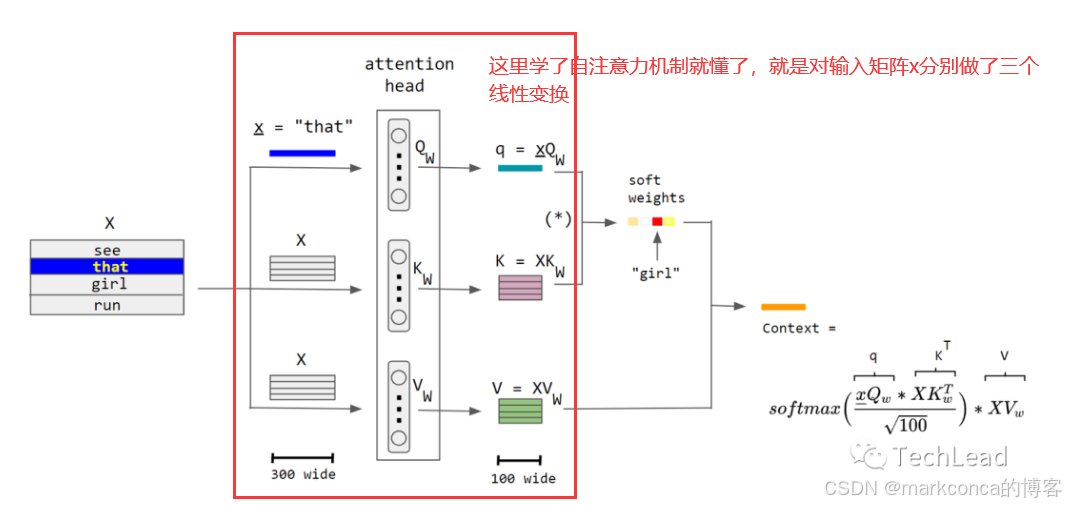
一、引言
定义
注意力机制是指人类的神经系统在面对复杂的感知信息时,通过选择性的关注和集中注意力来处理特定的刺激。注意力机制可以帮助我们过滤掉不相关或无用的信息,并专注于重要的刺激、任务或目标。这种机制可以通过自主调控或受到外界环境的影响而发生变化。例如,注意力可以集中于一个特定的刺激或任务,也可以在多个刺激之间进行转移和分配。注意力机制在认知过程中起着重要的作用,影响感知、思维、决策和行为等方面的表现。
基于注意力机制的深度学习,核心在于让机器学会去感知数据中的重要和不重要的部分。
or说人在处理信息的时候,会将注意力放在需要关注的信息上,对于其他无关的外部信息进行过滤,这种处理方式被称为注意力机制。
比如在做人脸识别时,需要让机器存在一个注意力侧重,重点关注图片中人脸的面部特征,包括耳朵,眼睛,鼻子,嘴巴,而不用太关注背景的一些信息;同理,在做机器翻译等任务时,要让机器注意到每个词向量之间的相关性,有侧重地进行翻译,模拟人类理解的过程。
两种类型
非自主提示和自主提示
针对于注意力机制的引起方式,可以分为两类,一种是非自主提示,另一种是自主提示。
1️⃣非自主提示指的是由于物体本身的特征十分突出引起的注意力倾向。
2️⃣自主提示指的是经过先验知识的介入下,对具有先验权重的物体引起的注意力倾向。
简单可理解为非自主提示源自于物体本身,而自主提示源自于一种主观倾向。举例说明如下

当第一眼看到上图时,便会首先将注意力集中到兔子身上。这是因为,整张图中兔子的特征十分的突出,让人一眼就关注到兔子身上。这种引起注意力的方式便是非自主提示。在看到兔子之后,便想兔子在干嘛,从而就会关注兔子的行为。此时兔子在吃草,这时便把注意力集中在兔子周边的草上。这种引起注意力机制的方式便是自主提示,其中"兔子在干嘛"则是主观意识。
另一种等价说法

历史背景

-
2014年:序列到序列(Seq2Seq)模型的出现为自然语言处理(NLP)和机器翻译带来了巨大的突破。(在2014年,Google mind团队发表《Recurrent Models of Visual Attention》一文,文中首次在RNN模型上使用了attention机制来进行图像分类)

-
 2015年:Bahdanau等人首次引入了注意力机制,用于改进基于Seq2Seq的机器翻译。
2015年:Bahdanau等人首次引入了注意力机制,用于改进基于Seq2Seq的机器翻译。 -
2017年:Vaswani等人提出了Transformer模型,这是第一个完全依赖于注意力机制来传递信息的模型,显示出了显著的性能提升。(2017年Ashish Vaswani的《Attention is all you need》中Transformer结构的提出,注意力机制在NLP,CV相关问题的网络设计上被广泛应用)
-
2018-2021年:注意力机制开始广泛应用于不同的领域,包括计算机视觉、语音识别和生成模型,如GPT和BERT等。
-
2021年以后:研究者们开始探究如何改进注意力机制,以便于更大、更复杂的应用场景,如多模态学习和自监督学习。
重要性
-
性能提升:注意力机制一经引入即显著提升了各种任务的性能,包括但不限于文本翻译、图像识别和强化学习。
-
计算效率:通过精心设计的权重分配,注意力机制有助于减少不必要的计算,从而提高模型的计算效率。
-
可解释性:虽然深度学习模型常被批评为“黑盒”,但注意力机制提供了一种直观的方式来解释模型的决策过程。
-
模型简化:在多数情况下,引入注意力机制可以简化模型结构,如去除或减少递归网络的需要。
-
领域广泛性:从自然语言处理到计算机视觉,再到医学图像分析,注意力机制的应用几乎无处不在。
-
模型泛化:注意力机制通过更智能地挑选关联性强的特征,提高了模型在未见过数据上的泛化能力。
-
未来潜力:考虑到当前研究的活跃程度和多样性,注意力机制有望推动更多前沿科技的发展,如自动驾驶、自然语言界面等。
最主要是以下两个方面的原因:
(1)计算能力的限制:目前计算能力依然是限制神经网络发展的瓶颈,当要记住很多“信息“,模型就要变得更复杂,通过引入注意力,可以聚焦重要的部分,减少处理的信息量,从而减小需要的计算资源。
(2)优化算法的限制:虽然CNN、RNN及其各种变体模型,可以有效缓解模型复杂度和表达能力之间的矛盾,但是,如LSTM只能在一定程度上缓解RNN中的长距离依赖问题,且信息“记忆”能力并不高。
二、注意力机制

注意力机制是一种模拟人类视觉和听觉注意力分配的方法,在处理大量输入数据时,它允许模型关注于最关键的部分。这一概念最早是为了解决自然语言处理中的序列到序列模型的一些局限性而被提出的,但现在已经广泛应用于各种机器学习任务。
基础概念
定义
在数学上,注意力函数可以被定义为一个映射,该映射接受一个查询(Query)和一组键值对(Key-Value pairs),然后输出一个聚合后的信息,通常称为注意力输出(也叫注意力分数)。
注意力(Q, K, V) = 聚合(权重 * V)
其中,权重通常是通过查询(Q)和键(K)的相似度计算得到的:
权重 = softmax(Q * K^T / sqrt(d_k))d_k 表示查询向量(Q)或键向量(K)的特征维度(即列)(不是时间维度,即行)。(这个或字是因为这两个维度大小是一致的,因为为了保证矩阵乘法可以进行)
ps:对于一维张量(向量),通常我们只讨论其长度,而不区分时间维度或特征维度
缩放因子(scaling factor)sqrt(d_k) 是用来缩放注意力权重分布的一个系数(据说是为了稳定梯度)
组件
-
Query(查询): 代表需要获取信息的请求。(即我们的输入信息,就是我自己本身)
-
Key(键): 与Query相关性的衡量标准。(KV成组出现,一般是源语言or源文本,就是我们关注的对象)
-
Value(值): 包含需要被提取信息的实际数据。
-
权重(Attention Weights): 通过Query和Key的相似度计算得来,决定了从各个Value中提取多少信息。
如何理解KQV:以阅读理解为例,Q就是问题,K和V就是原始文本
再简单点说:A关注B,A就是Q,B就是KV对
也许你会想问那K和V的区别是啥?这里我比较喜欢GPT的回答

K和V的关系是,它们通常来自序列中的同一元素,但在不同的向量空间中。在自注意力计算中,首先将查询Q与所有键K进行点积(或使用其他相似度度量方法),得到一个分数矩阵,这个分数矩阵表示了序列中每个元素对当前查询的相关性。然后,这些分数通过softmax函数进行归一化,确保每一行的和为1,形成一个概率分布。最后,这个概率分布用来对值V进行加权求和,得到最终的输出。

数学意义
-
点积 ( QK^T ):这一步测量了查询和键之间的相似性。点积越大,意味着查询和相应的键更相似。
-
缩放因子 ( \sqrt{d_k} ):缩放因子用于调整点积的大小,使得模型更稳定(防止梯度过大或过小)。
-
Softmax 函数:Softmax 用于将点积缩放的结果转化为概率分布,从而确定每个值在最终输出中的权重。
好了接下来解释一下注意力机制的细节

上面这张图的很好的讲解:【原来如此】深度学习中注意力机制(attention)的真实由来_哔哩哔哩_bilibili
我总结以下几个重点!!!:
1)

T代表时间维度(序列长度),D代表特征维度
2)为了保证矩阵可以相乘,必须满足


对于二维张量(矩阵),通常会有明确的行和列,这时候可以区分:
- 时间维度:通常指的是矩阵的行数,如果每一行代表一个时间点的数据。
- 特征维度:通常指的是矩阵的列数,如果每一列代表一个特征的值。
3)Q*K是在算相关性的问题(还没涉及到值呢)(借助向量内积,90度以内夹角越小内积越大)
考试抄作业


4)Softmax可以把两个负相关的向量的内积值变成一个很小很小的正数(概率),并把原来的正数也变成0,1之间的概率值

5)

现在可以接受为啥必须要用Softmax把权重变成正的:因为V的值是个任意值,可正可负。如果没有Softmax,权重(K*Q)就有可能有负的,负负得正啊,那样结果就不是我们想要的了。这才是必须用Softmax的精髓所在
这也说明了最终的注意力计算结果是可正可负的(因为权重必须是正的,v可正可负,最终一乘结果就是可正可负)
看到了另一个很好的解释:
查询、键和值
根据自主提示和非自主提示来设计注意力机制。
1️⃣首先考虑简单情况,即只考虑非自主提示的话,只需要对所有物体的特征信息(非自主提示)进行简单的全连接层,甚至是无参数的平均汇聚层或者最大汇聚层,就可以提取出需要感兴趣的物体。
下图是平均汇聚方法的示例图,最后结果是所有物体向量的平均加权和。

2️⃣如果考虑自主提示的话,我们就需要设计一种通过查询(Query),键(Key)和值(Value)来实现注意力机制的方法。其中Query指的是自主提示,即主观意识的特征向量,Key指的是非自主提示,即物体的突出特征信息向量,Value则是代表物体本身的特征向量。
注意力机制是通过Query与Key的注意力汇聚(指的是对Query和Key的相关性进行建模,实现池化筛选或者分配权重),实现对Value的注意力权重分配,生成最终的输出结果。如下图所示:

划重点:
1.注意力可以分为两种方式分别是自主提示和非自主提示。其中非自主提示是键,自主提示是查询,物体原始向量是值。键和值是一一对应的!!!(务必理解!!!)
2.注意力机制的评分函数可以对查询和键进行关系建模,获取查询和键的相似度匹配。其方法分为两种:加性注意力和点积注意力。常用的是点积注意力。
注意力机制的分类
-
点积(Dot-Product)注意力
-
缩放点积(Scaled Dot-Product)注意力
-
多头注意力(Multi-Head Attention):自注意力的升级版
-

-
自注意力(Self-Attention)(只关注输入序列元素之间的关系,即将输入序列之间转换为KQV)
-
双向注意力(Bi-Directional Attention)
当然还有别的分类方法,个人更喜欢下面的分类方法
从广义来说可分为三类:自注意(内注意)、软注意(全局注意)和硬注意(局部注意)。

Self/Intra Attention(自注意力机制):对每个输入项分配的权重取决于输入项之间的相互作用,即通过输入项内部的"表决"来决定应该关注哪些输入项。和前两种相比,在处理很长的输入时,具有并行计算的优势。
Global/Soft Attention(软注意机制):对每个输入项的分配的权重为0-1之间,也就是某些部分关注的多一点,某些部分关注的少一点,因为对大部分信息都有考虑,但考虑程度不一样,所以相对来说计算量比较大。
Local/Hard Attention(硬注意机制):对每个输入项分配的权重非0即1,和软注意不同,硬注意机制只考虑哪部分需要关注,哪部分不关注,也就是直接舍弃掉一些不相关项。优势在于可以减少一定的时间和计算成本,但有可能丢失掉一些本应该注意的信息。
以上三类又可以细化为很多小类,下面的总结了几种流行的注意力机制以及相应的注意力打分数函数score。

举例说明
假设我们有一个简单的句子:“猫喜欢追逐老鼠”。如果我们要对“喜欢”这个词进行编码,一个简单的方法是只看这个词本身,但这样会忽略它的上下文。“喜欢”的对象是“猫”,而被“喜欢”的是“追逐老鼠”。在这里,“猫”和“追逐老鼠”就是“喜欢”的上下文,而注意力机制能够帮助模型更好地捕获这种上下文关系。
# 使用PyTorch实现简单的点积注意力
import torch
import torch.nn.functional as F
# 初始化Query, Key, Value
Q = torch.tensor([[1.0, 0.8]]) # Query 对应于 "喜欢" 的编码
K = torch.tensor([[0.9, 0.1], [0.8, 0.2], [0.7, 0.9]]) # Key 对应于 "猫", "追逐", "老鼠" 的编码
V = torch.tensor([[1.0, 0.1], [0.9, 0.2], [0.8, 0.3]]) # Value 也对应于 "猫", "追逐", "老鼠" 的编码
# 计算注意力权重
d_k = K.size(1) # size(1)是特征维度,本例 = 2
scores = torch.matmul(Q, K.transpose(0, 1)) / (d_k ** 0.5)
weights = F.softmax(scores, dim=-1)
# 计算注意力输出
output = torch.matmul(weights, V)
print("注意力权重:", weights)
print("注意力输出:", output)
输出:
注意力权重: tensor([[0.4761, 0.2678, 0.2561]])
注意力输出: tensor([[0.9529, 0.1797]])
这里,“喜欢”通过注意力权重与“猫”和“追逐老鼠”进行了信息的融合,并得到了一个新的编码,从而更准确地捕获了其在句子中的语义信息。
通过这个例子,我们可以看到注意力机制是如何运作的,以及它在理解序列数据,特别是文本数据中的重要性。
再举个例子
假设我们有三个单词:'apple'、'orange'、'fruit',用三维向量 ( Q, K_1, K_2 ) 表示。
import math
import torch
# Query, Key 初始化
Q = torch.tensor([2.0, 3.0, 1.0])
K1 = torch.tensor([1.0, 2.0, 1.0]) # 'apple'
K2 = torch.tensor([1.0, 1.0, 2.0]) # 'orange'
# 点积计算
dot_product1 = torch.dot(Q, K1)
dot_product2 = torch.dot(Q, K2)
# 缩放因子
d_k = Q.size(0) # 一维张量,size(0)就行,Q和K大小一致,写哪个都行,本例=3
scale_factor = math.sqrt(d_k)
# 缩放点积
scaled_dot_product1 = dot_product1 / scale_factor
scaled_dot_product2 = dot_product2 / scale_factor
# Softmax 计算
weights = torch.nn.functional.softmax(torch.tensor([scaled_dot_product1, scaled_dot_product2]), dim=0)
print("权重:", weights)
输出:
权重: tensor([0.6225, 0.3775])
在这个例子中,权重显示“fruit”与“apple”(0.6225)相比“orange”(0.3775)更相似。这种计算方式为我们提供了一种量化“相似度”的手段,进一步用于信息聚合。
通过深入理解注意力机制的数学模型,我们可以更准确地把握其如何提取和聚合信息,以及它在各种机器学习任务中的应用价值。这也为后续的研究和优化提供了坚实的基础。
三、注意力值的计算过程
为了便于大家更好的理解,这里张张以软性注意力机制为例,详细介绍它的计算过程。
软性注意力机制的思想用数学语言来表达:X=[x1,x2,…,XN]表示N个输入信息,为了节省计算资源,神经网络不需要处理这N个输入信息,而只需要从X中选择一些与任务相关的信息进行计算。
也可以对应于下面的场景:把输入信息向量X看做是一个信息存储器,现在给定一个查询向量q,用来查找并选择X中的某些信息,软性注意力机制,从所有的信息中按q与X相关度来抽取信息。
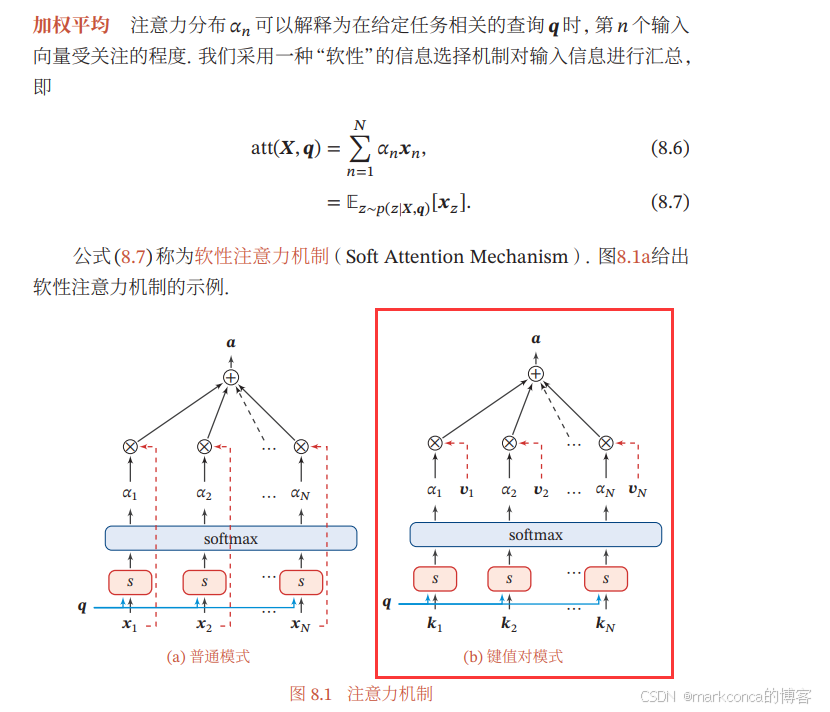
注意力值的计算分为以下两步:计算注意力分布、计算加权平均。
(1)计算注意力分布
定义一个注意力变量z来表示被选择信息的索引位置,即z=i来表示选择了第i个输入信息,然后计算在给定了q和X的情况下,选择第i个输入信息的概率αi,计算公式如下:

其中,α构成的概率向量就称为注意力分布。s(xi,q)是注意力打分函数,有以下几种形式:

其中W、U和v是可学习的网络参数,d是输入信息的维度。
(2)计算加权平均
注意力分布表示在给定查询q时,输入信息向量X中第i个信息与查询q的相关程度。采用软性注意力机制给出查询所得的结果,就是用加权平均的方式对输入信息进行汇总,得到Attention值:

下图是计算Attention值的过程:

更一般的,可以用键值对(key-value pair)来表示输入信息,那么就可以将注意力机制看做是一种软寻址操作(这也是我们最常用的操作):计算Query与存储器内元素的地址Key的相似度,再通过Query与Key的相似性计算每个Value值的权重,然后对Value值进行加权求,加权求和得到最终的Value值,也就是Attention值。
公式表示如下:

四、注意力机制的对比小举例
为了更直观地说明注意力机制的作用,这里以Seq-to-Seq模型为例,对比未加入注意力机制的模型和加入了注意力机制后的模型。
(1)未使用注意力机制的模型
《Learning phrase representations using RNN encoder-decoder for statistical machine translation》这篇论文提出了一种RNN Encoder-Decoder的结构,如下图。

预测第t个单词的概率公式如下:

可以看到,在生成目标句子的每一个单词时,使用的语义表示向量c都是同一个,也就说生成每一个单词时,并没有产生 这样与每个输出的单词相对应的多个不同的语义表示。那么在预测某个词yt时,任何输入单词对于它的重要性都是一样的,也就是注意力分散了。
(2)加入注意力机制的模型
《Neural Machine Translation by Jointly Learning to Align and Translate 》在上面论文的基础上,提出了一种新的神经网络翻译模型结构,也就是在RNN Encoder-Decoder框架中加入了注意力机制,如下图:

预测第i个单词的概率公式如下:

增加了注意力机制的网络结构中,注意力模块负责自动学习注意力权重αij,它可以自动捕获hi(编码器隐藏状态,我们称之为候选状态)和sj(解码器隐藏状态,我们称之为查询状态)之间的相关性。然后,这些注意力权重用于构建内容向量C,该向量作为输入传递给解码器。在每个解码位置j,内容向量cj是编码器所有隐藏状态及其相应注意权的加权和。
总的来说,两种框架相比,加入注意力机制的框架的核心在于固定不变的语义向量表示c被替换成了根据当前生成的单词而不断变化的语义表示ci。通过这样的方式,可以使模型快速聚焦于重要的部分。
五、注意力网络在NLP中的应用(拓展)

注意力机制在自然语言处理(NLP)中有着广泛的应用,包括机器翻译、文本摘要、命名实体识别(NER)等。本节将深入探讨几种常见应用,并提供相应的代码示例。
机器翻译
机器翻译是最早采用注意力机制的NLP任务之一。传统的Seq2Seq模型在处理长句子时存在信息损失的问题,注意力机制通过动态权重分配来解决这一问题。
代码示例
import torch
import torch.nn as nn
class AttentionSeq2Seq(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(AttentionSeq2Seq, self).__init__()
self.encoder = nn.LSTM(input_dim, hidden_dim)
self.decoder = nn.LSTM(hidden_dim, hidden_dim)
self.attention = nn.Linear(hidden_dim * 2, 1)
self.output_layer = nn.Linear(hidden_dim, output_dim)
def forward(self, src, tgt):
# Encoder
encoder_output, (hidden, cell) = self.encoder(src)
# Decoder with Attention
output = []
for i in range(tgt.size(0)):
# 计算注意力权重
attention_weights = torch.tanh(self.attention(torch.cat((hidden, encoder_output), dim=2)))
attention_weights = torch.softmax(attention_weights, dim=1)
# 注意力加权和
weighted = torch.sum(encoder_output * attention_weights, dim=1)
# Decoder
out, (hidden, cell) = self.decoder(weighted.unsqueeze(0), (hidden, cell))
out = self.output_layer(out)
output.append(out)
return torch.stack(output)
文本摘要
文本摘要任务中,注意力机制能够帮助模型挑选出文章中的关键句子或者词,生成一个内容丰富、结构紧凑的摘要。
代码示例
class TextSummarization(nn.Module):
def __init__(self, vocab_size, embed_size, hidden_size):
super(TextSummarization, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.encoder = nn.LSTM(embed_size, hidden_size)
self.decoder = nn.LSTM(hidden_size, hidden_size)
self.attention = nn.Linear(hidden_size * 2, 1)
self.output = nn.Linear(hidden_size, vocab_size)
def forward(self, src, tgt):
embedded = self.embedding(src)
encoder_output, (hidden, cell) = self.encoder(embedded)
output = []
for i in range(tgt.size(0)):
attention_weights = torch.tanh(self.attention(torch.cat((hidden, encoder_output), dim=2)))
attention_weights = torch.softmax(attention_weights, dim=1)
weighted = torch.sum(encoder_output * attention_weights, dim=1)
out, (hidden, cell) = self.decoder(weighted.unsqueeze(0), (hidden, cell))
out = self.output(out)
output.append(out)
return torch.stack(output)
命名实体识别(NER)
在命名实体识别任务中,注意力机制可以用于捕捉文本中不同实体之间的依赖关系。
代码示例
class NERModel(nn.Module):
def __init__(self, vocab_size, embed_size, hidden_size, output_size):
super(NERModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size, hidden_size, bidirectional=True)
self.attention = nn.Linear(hidden_size * 2, 1)
self.fc = nn.Linear(hidden_size * 2, output_size)
def forward(self, x):
embedded = self.embedding(x)
rnn_output, _ = self.rnn(embedded)
attention_weights = torch.tanh(self.attention(rnn_output))
attention_weights = torch.softmax(attention_weights, dim=1)
weighted = torch.sum(rnn_output * attention_weights, dim=1)
output = self.fc(weighted)
return output
这些只是注意力网络在NLP中应用的冰山一角,但它们清晰地展示了注意力机制如何增强模型的性能和准确性。随着研究的不断深入,我们有理由相信注意力机制将在未来的NLP应用中发挥更加重要的作用。
六、注意力网络在计算机视觉中的应用(拓展)

注意力机制不仅在NLP中有广泛应用,也在计算机视觉(CV)领域逐渐崭露头角。本节将探讨注意力机制在图像分类、目标检测和图像生成等方面的应用,并通过代码示例展示其实现细节。
图像分类
在图像分类中,注意力机制可以帮助网络更加聚焦于与分类标签密切相关的图像区域。
代码示例
import torch
import torch.nn as nn
class AttentionImageClassification(nn.Module):
def __init__(self, num_classes):
super(AttentionImageClassification, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3)
self.conv2 = nn.Conv2d(32, 64, 3)
self.attention = nn.Linear(64, 1)
self.fc = nn.Linear(64, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
attention_weights = torch.tanh(self.attention(x.view(x.size(0), x.size(1), -1)))
attention_weights = torch.softmax(attention_weights, dim=2)
x = torch.sum(x.view(x.size(0), x.size(1), -1) * attention_weights, dim=2)
x = self.fc(x)
return x
目标检测
在目标检测任务中,注意力机制能够高效地定位和识别图像中的多个对象。
代码示例
class AttentionObjectDetection(nn.Module):
def __init__(self, num_classes):
super(AttentionObjectDetection, self).__init__()
self.conv = nn.Conv2d(3, 64, 3)
self.attention = nn.Linear(64, 1)
self.fc = nn.Linear(64, 4 + num_classes) # 4 for bounding box coordinates
def forward(self, x):
x = self.conv(x)
attention_weights = torch.tanh(self.attention(x.view(x.size(0), x.size(1), -1)))
attention_weights = torch.softmax(attention_weights, dim=2)
x = torch.sum(x.view(x.size(0), x.size(1), -1) * attention_weights, dim=2)
x = self.fc(x)
return x
图像生成
图像生成任务,如GANs,也可以从注意力机制中受益,尤其在生成具有复杂结构和细节的图像时。
代码示例
class AttentionGAN(nn.Module):
def __init__(self, noise_dim, img_channels):
super(AttentionGAN, self).__init__()
self.fc = nn.Linear(noise_dim, 256)
self.deconv1 = nn.ConvTranspose2d(256, 128, 4)
self.attention = nn.Linear(128, 1)
self.deconv2 = nn.ConvTranspose2d(128, img_channels, 4)
def forward(self, z):
x = self.fc(z)
x = self.deconv1(x.view(x.size(0), 256, 1, 1))
attention_weights = torch.tanh(self.attention(x.view(x.size(0), x.size(1), -1)))
attention_weights = torch.softmax(attention_weights, dim=2)
x = torch.sum(x.view(x.size(0), x.size(1), -1) * attention_weights, dim=2)
x = self.deconv2(x.view(x.size(0), 128, 1, 1))
return x
这些应用示例明确地展示了注意力机制在计算机视觉中的潜力和多样性。随着更多的研究和应用,注意力网络有望进一步推动计算机视觉领域的发展。


















 1733
1733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









