







 本文介绍知识蒸馏技术,一种将大型模型的知识转移至小型模型的方法,旨在保持精度的同时减少计算资源消耗。通过调整温度参数,从teacher模型中获取soft target,用于指导student模型的训练。
本文介绍知识蒸馏技术,一种将大型模型的知识转移至小型模型的方法,旨在保持精度的同时减少计算资源消耗。通过调整温度参数,从teacher模型中获取soft target,用于指导student模型的训练。
论文:Distilling the Knowledge in a Neural Network
目前的深度学习仍然处于“数据驱动”的阶段,通常在模型训练的时候,仍然需要从巨大且冗余的数据中提取特征结构,且需要巨大的资源消耗,但是不考虑实时性要求;最后训练得到的模型大而笨重,但是模型预测精度较高。但是在实际应用中,有计算资源和延迟的限制,例如手机设备和芯片系统等等,那么要如何使得模型减重且精度不损失呢?
对于应用到芯片系统里的模型,我目前只接触了卷积网络的稀疏和量化。本篇我们仅仅介绍知识蒸馏,知识蒸馏是一种模型压缩的方式。对于训练好的大而笨重的模型,我们使用另一种训练方式,“蒸馏”,将从大而笨重中需要的知识转换到一个小但是更合适部署的模型。
名词解释
-
teacher:大而笨重的模型
-
student:小而紧凑的模型
-
transfer set:用于小模型训练的数据,也是获得teacher模型soft target输出的输入数据集
-
hard target: 样本原始标签
-
soft target:teacher模型输出的预测结果
-
temperature: softmax函数中的超参数
-
knowledge:可以理解为从输入向量到输出向量学习到的映射
符号定义
-
z z z: logit,模型去除输出层的输出
-
p p p: probability,每个类的概率
基本思想
知识蒸馏的目的是将一个高精度且笨重的teacher转换为一个更加紧凑的student。具体思路是:提高teacher模型softmax层的temperature参数获得一个合适的soft target集合,然后对要训练的student模型,使用同样的temperature参数值匹配teacher模型的soft target集合,作为student模型总目标函数的一部分,以诱导student模型的训练,实现知识的迁移。
蒸馏
一般来说,神经网络都是通过一个“softmax”输出层来计算每个类的概率。softmax函数为:
q
i
=
e
x
p
(
z
i
/
T
)
∑
j
e
x
p
(
z
j
/
T
)
q_{i} = \frac{exp\left(z_{i} / T \right)}{\sum_{j}exp\left(z_{j} / T \right)}
qi=∑jexp(zj/T)exp(zi/T)
参数T为temperature,一般情况下,T值设置为1。当把T值设置为一个更大的数,将会得到一个更加‘soft’的概率分布。下面给出一个例子有助于理解何为“softer”。
| 类别一 | 类别二 | 类别三 | 类别四 | 类别5 | |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | hard target |
| 2 | 0.1 | 0.5 | 0.001 | 0.001 | logits |
| 0.608 | 0.09 | 0.136 | 0.08 | 0.082 | soft target(T=1) |
| 0.266 | 0.182 | 0.197 | 0.178 | 0.178 | soft target(T=5) |
| 0.231 | 0.191 | 0.199 | 0.189 | 0.189 | soft target(T=10) |
soft target的作用
soft target相对于hard target,携带更多更多有用的信息。对分类来说,物体的标定都是离散的,一个物体只有一个特定的类别,但是大多数情况下,很多类别之间有很大的相似性,(譬如动物与动物之间相似性,植物与植物之间的相似性),但是这些相似性不能被离散的标定表示出来。如上表所示,one-hot编码的hard target信息熵低,只在类别一处取值为1;soft target信息熵高,每一类别都有相应的概率,这个概率值能够能够更好地展示出不同类别之间的相似性,可看做对原始的标定空间进行了“数据扩增”。在论文中,给出了在soft target的帮助下,仅仅使用3%的数据去拟合85M参数量级的语音识别模型,并且能够避免未使用soft target时,3%的数据量训练模型时候的过拟合问题。具体数据参照下图所示。

目标函数
目标函数为两个目标函数的加权平均,一是与soft target的交叉熵,二是与hard target的价差上,具体介绍如下:
-
第一个目标函数是与soft target的交叉熵,要求student模型与teacher模型softmax层计算时使用相同的temperature
-
第二个目标函数是与hard target的交叉熵,student模型的softmax层计算,temperature取值为1
一般来说,给第二个目标函数赋值一个更低的权重将会得到更好的结果。
训练
上述我们已经描述了知识蒸馏的基本原理,那么,对于要如何实际应用知识蒸馏这一理念,要如何训练网络呢?
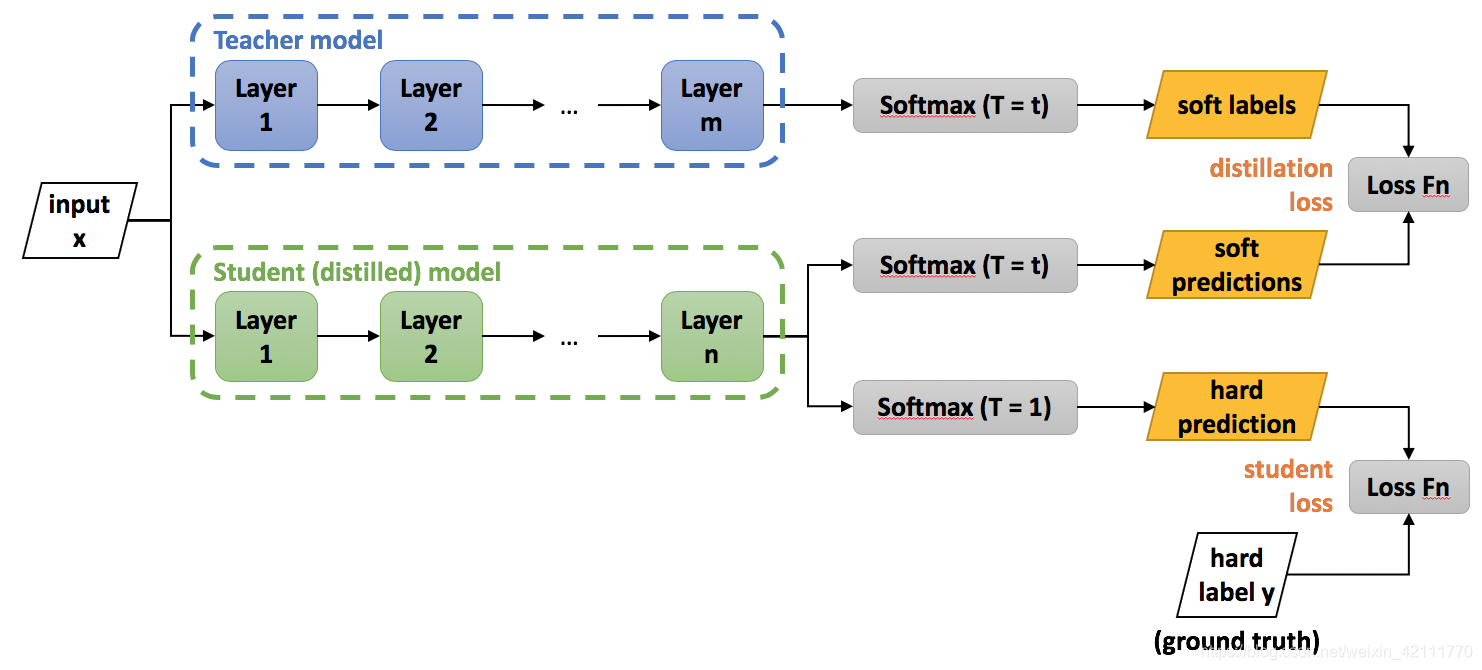
-
获得已经训练好的teacher模型
-
选择transfer set数据集,将teacher模型的logits输出除以temperature参数之后做softmax计算,得到soft target值
-
student模型的训练:输入经过student模型得到输出logits输出,而后分成两步计算:一是除以与teacher模型相同的temperature参数之后做softmax计算,此输出与soft target比较;二是做softmax计算,得出预测值,此预测值与hard target进行比较。两部分损失函数相加,得到总的损失函数,计算损失函数,梯度下降,更新参数。
ftmax计算,得出预测值,此预测值与hard target进行比较。两部分损失函数相加,得到总的损失函数,计算损失函数,梯度下降,更新参数。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











