







在即将下班的时刻,看到腾讯旗下的混元文生图大模型全面升级并全面开源的消息,忍不住搭环境下模型,实测一手。本以为很容易,但没想到困难重重,bug频现。
GitHub 项目地址:https://github.com/Tencent/HunyuanDiT
Hugging Face 模型地址:https://huggingface.co/Tencent-Hunyuan/HunyuanDiT
混元文生图大模型采用了与 Sora 一致的 DiT 架构,即全新的 Hunyuan-DiT 架构,不仅可以支持文生图,也可以作为视频等多模态视觉生成的基础。支持中英文双语输入及理解,参数量 15 亿。为业内首个中文原生的 DiT 架构文生图开源模型。
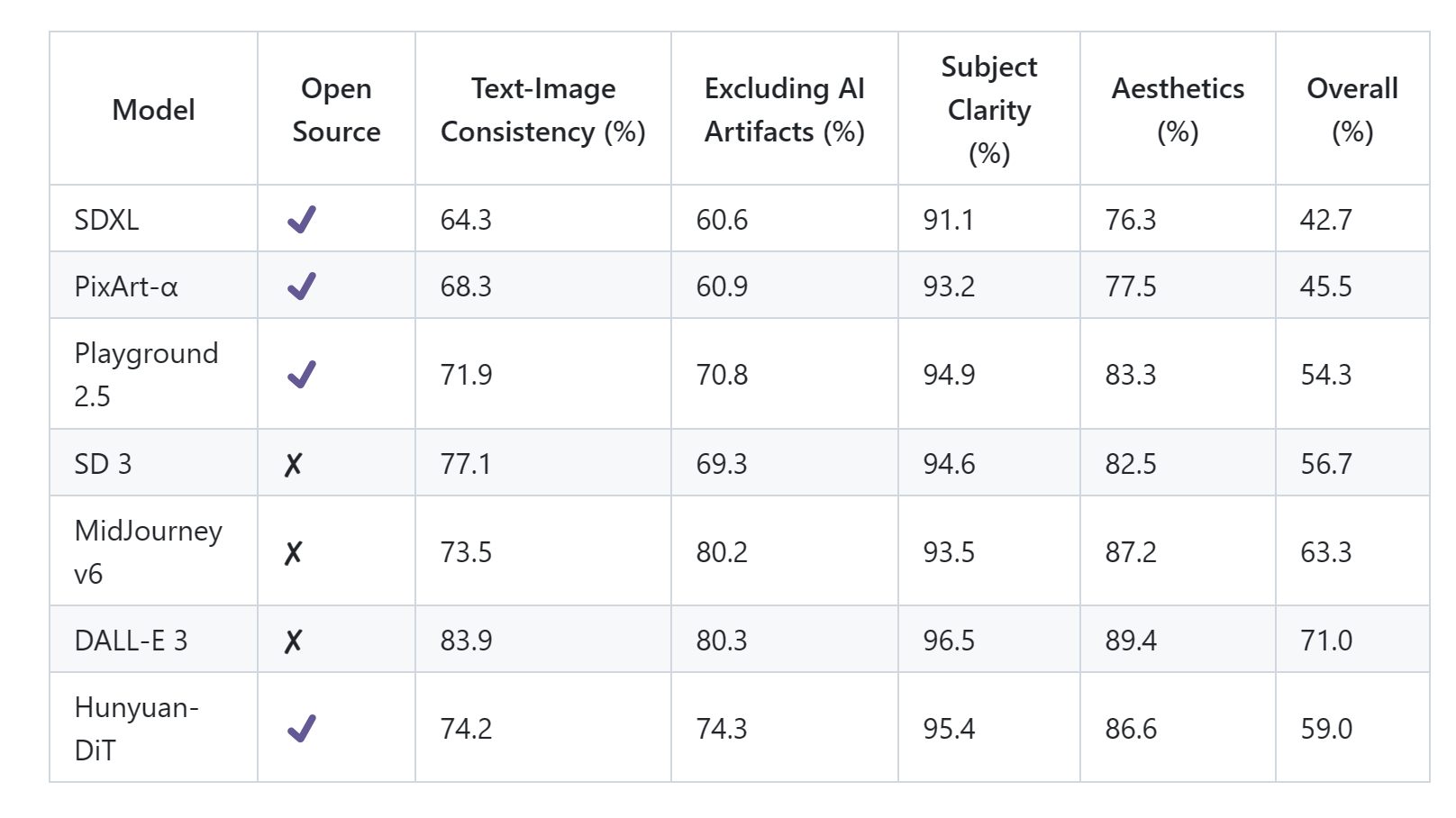
从下表中可以看出,混元文生图模型是目前最好的开源文生图模型。
模型架构
过去,视觉生成扩散模型主要基于 U-Net 架构,但随着参数量增加,基于 Transformer 架构的扩散模型展现了更好的扩展性,有助于进一步提升模型生成质量及效率。Sora 很好地说明了这一点。
腾讯混元文生图大模型采用了全新的 DiT 架构(DiT 即 Diffusion With Transformer),是一种基于 Transformer 架构的扩散模型。在 DiT 架构之上,混元模型支持了中英双语文本提示生成图像,并在算法层面优化模型的长文本理解能力,能够支持最多 256 字符的内容输入。
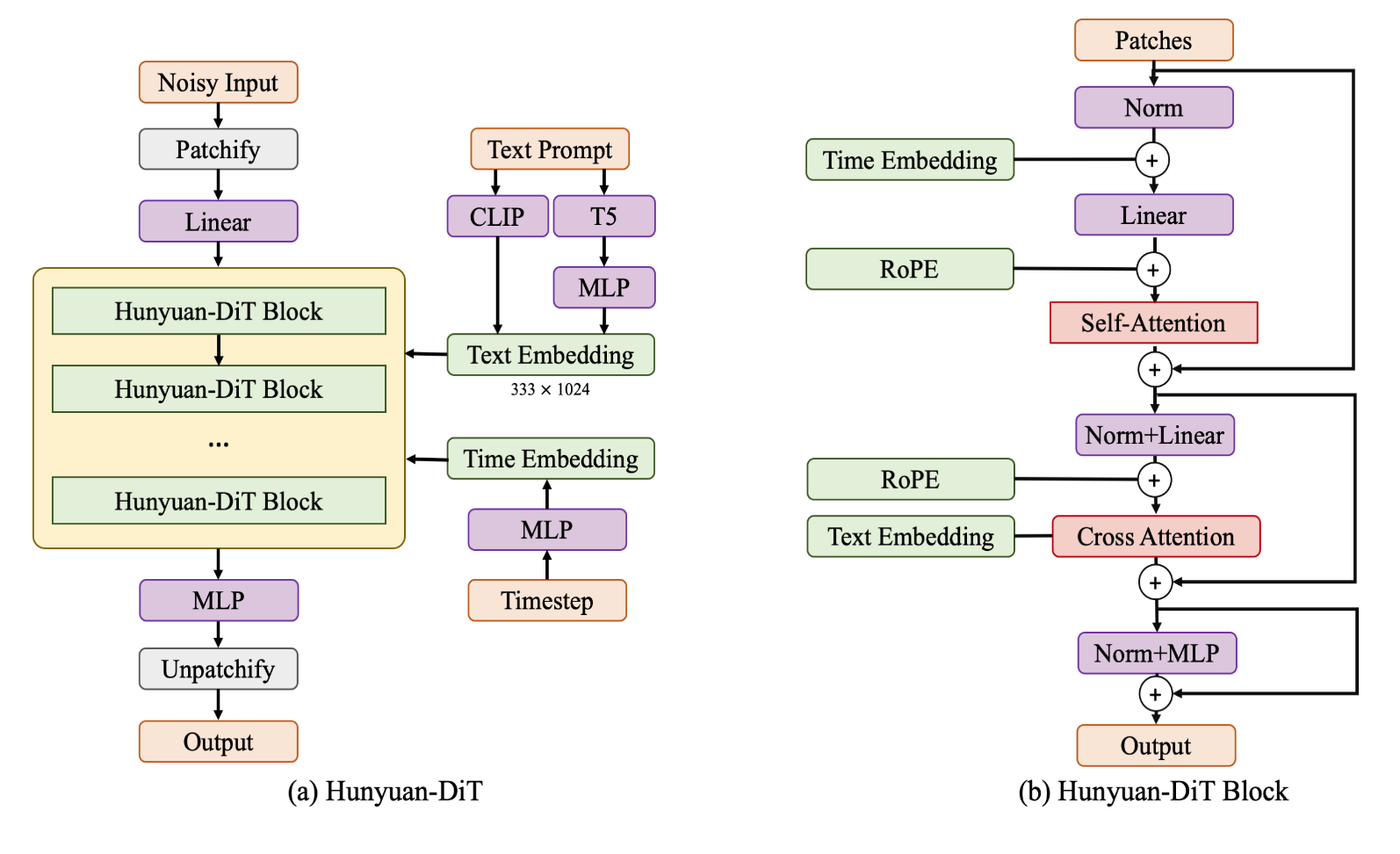
Hunyuan-DiT 的模型结构如下图所示,在遵循潜在扩散模型(Latent Diffusion Model)的基础上,使用预训练的变分自编码器(VAE)将图像压缩成低维的潜在空间,并训练一个扩散模型来学习数据的分布。扩散模型是通过一个转换器(transformer)进行参数化的。为了编码文本提示,我们利用了一个预训练的双语(英语和中文)CLIP模型和多语言T5编码器的组合。
多轮文生图生成
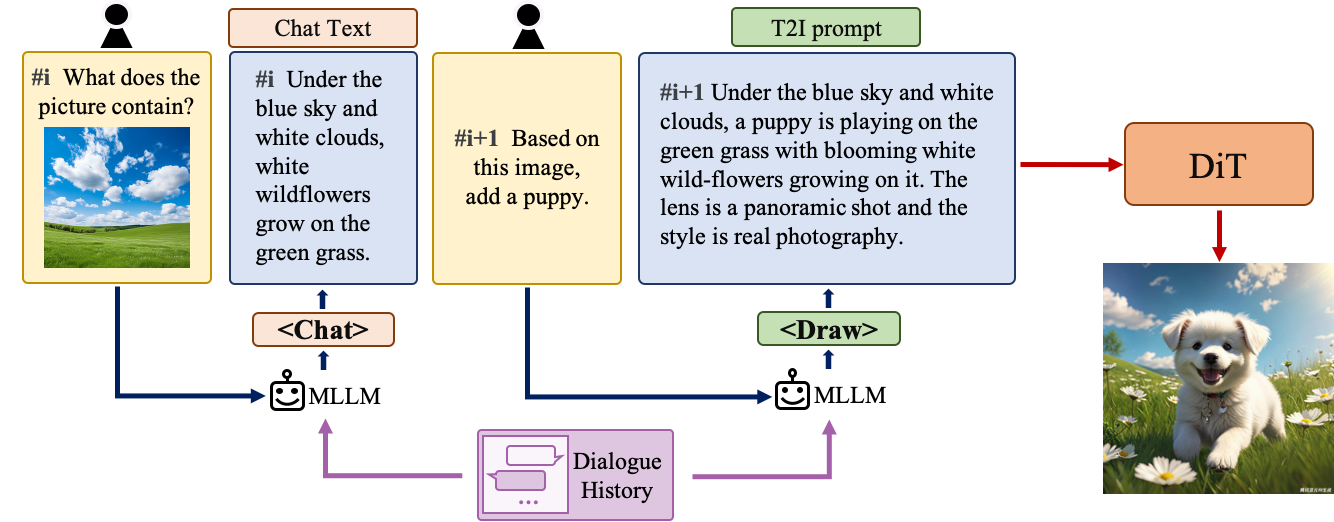
对于文本到图像系统来说,理解自然语言指令并与用户进行多轮交互是非常重要的。这有助于构建一个动态且迭代的创作过程,逐步将用户的想法变为现实。混元团队训练了多语言大型语言模型(MLLM)以理解多轮用户对话,并输出用于图像生成的新文本提示,以赋予Hunyuan-DiT执行多轮对话和图像生成能力。
环境配置
如下是官方给出的conda建立虚拟环境。
git clone https://github.com/tencent/HunyuanDiT
cd HunyuanDiT
# 1. Prepare conda environment
conda env create -f environment.yml
# 2. Activate the environment
conda activate HunyuanDiT
# 3. Install pip dependencies
python -m pip install -r requirements.txt
# 4. (Optional) Install flash attention v2 for acceleration (requires CUDA 11.6 or above)
python -m pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.1.2.post3
原先使用stable diffusion项目时,就已经配置好相关的虚拟环境,我大致查看了一下,包含混元所需的依赖包,所以就略过环境配置的步骤。
下一步,从hugging face中下载预训练模型。
python -m pip install “huggingface_hub[cli]” 如无huggingface-cli需先安装依赖
mkdir ckpts
huggingface-cli download Tencent-Hunyuan/HunyuanDiT --local-dir ./ckpts
但是会出现下述问题:

解决方案:
# 1. 使用清华源安装依赖
pip install -U huggingface_hub hf_transfer -i https://pypi.tuna.tsinghua.edu.cn/simple
# 2. 设置镜像站,开启hf_transfer加速下载
export HF_ENDPOINT=https://hf-mirror.com
export HF_HUB_ENABLE_HF_TRANSFER=1
# 3. 下载模型
huggingface-cli download --resume-download Tencent-Hunyuan/HunyuanDiT --local-dir ./ckpts
网络流畅时,下载速度很快,但是有时候会卡住。也可以通过modelscope社区进行下载预训练模型。
modelScope混元模型下载地址:https://modelscope.cn/models/modelscope/HunyuanDiT/summary
命令行运行
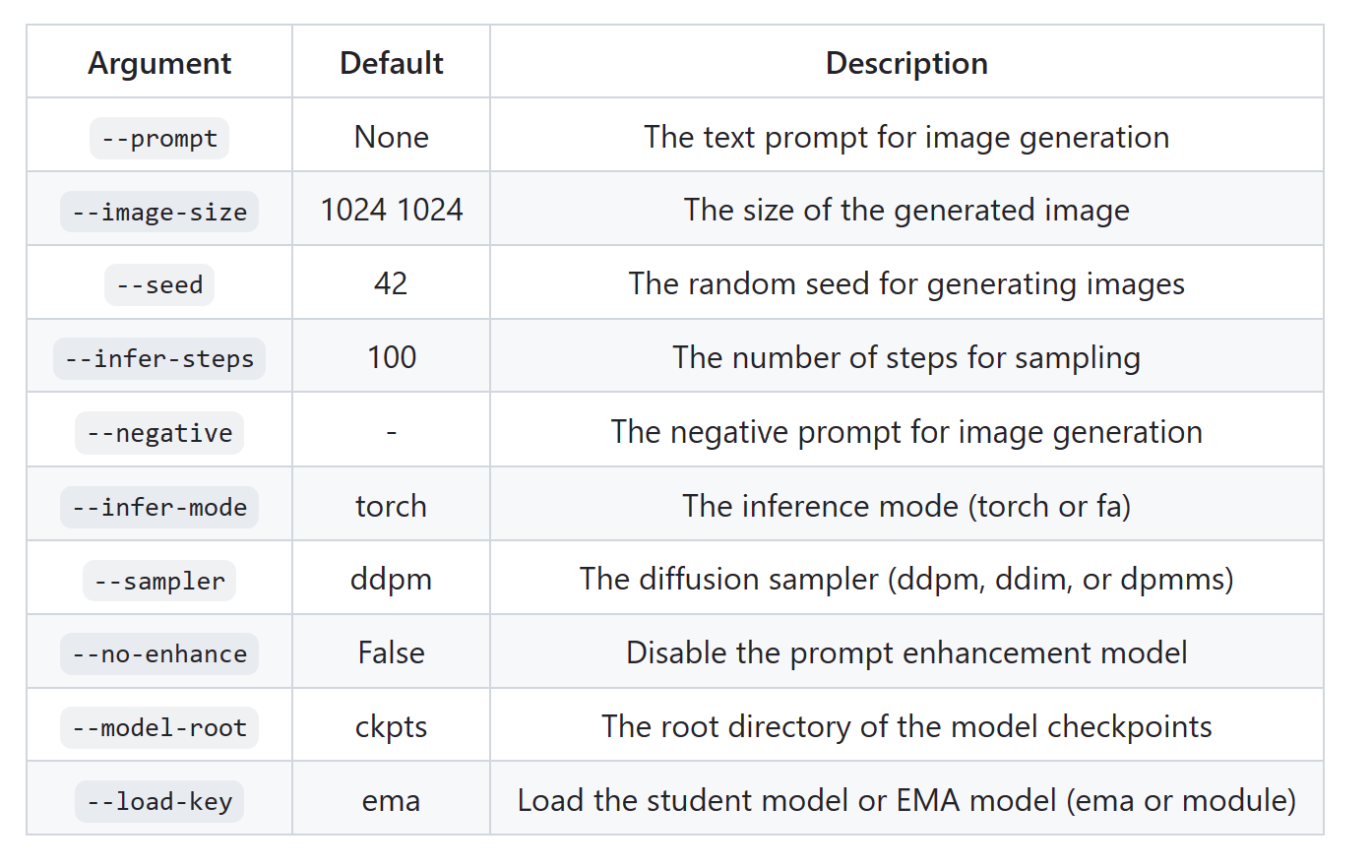
sample_t2i.py为运行主函数,参数如下所示:
bug
问题:直接运行python sample_t2i.py --prompt "渔舟唱晚"出现bug,ImportError: cannot import name ‘LlavaLlamaForCausalLM’ from ‘llava.model’ (/*/HunyuanDiT/dialoggen/llava/model/init.py)
环境: python:3.10 ;torch: 2.0.1+cu118
解决方案:
查到的方案是flash-attn和pytorch的版本不对应,按照命令 pip install flash-attn --no-build-isolation --no-cache-dir --use-pep517 安装flash-attn,出现下图所示错误:

可通过flash-atten release版本路径查找flash-atten与pytorch对应版本的安装包。与上图红框给出的URL链接一致。
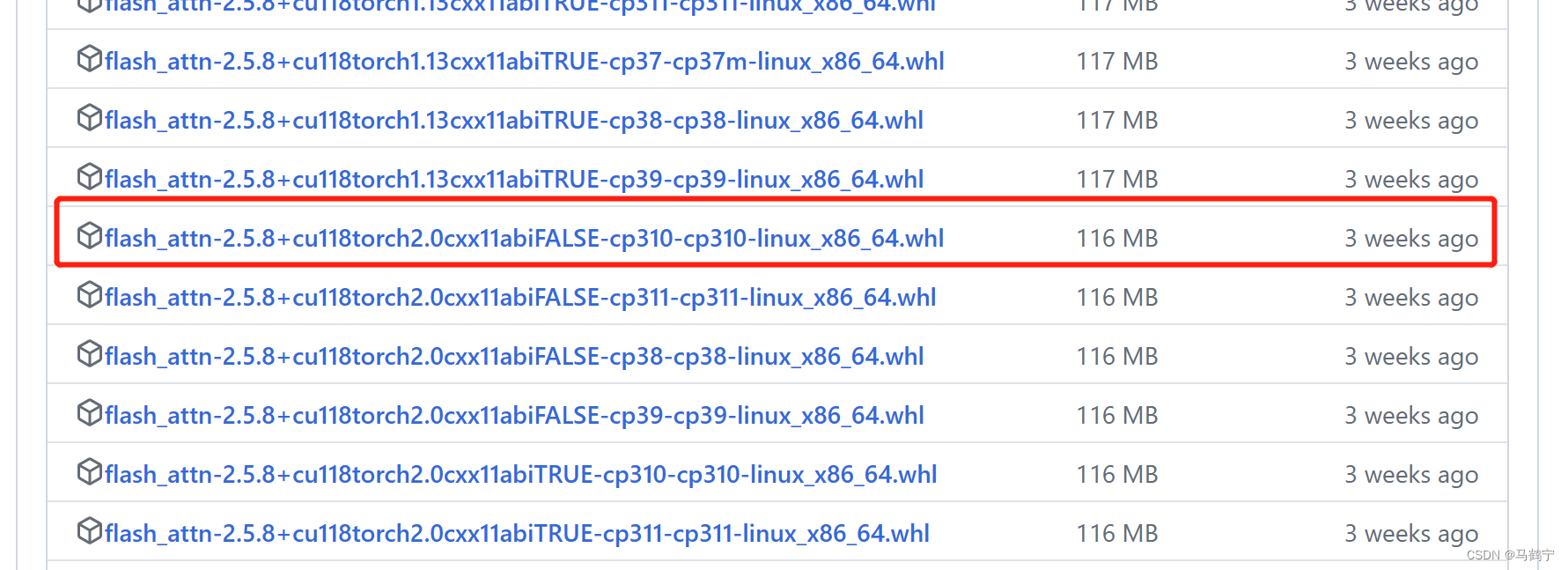
# 下载包文件
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.5.8/flash_attn-2.5.8+cu118torch2.0cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
# pip直接安装离线安装包
pip install flash_attn-2.5.8+cu118torch2.0cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
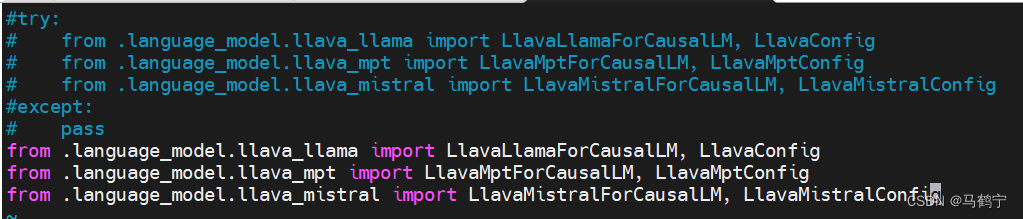
但是还是会出现同样的错误,于是我将dialoggen/llava/model/init.py中的try-except去掉,问题解决了。
问题:OSError: We couldn’t connect to ‘https://huggingface.co’ to load this file, couldn’t find it in the cached files and it looks like openai/clip-vit-large-patch14-336 is not the path to a directory containing a file named preprocessor_config.json.
Checkout your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode
解决方案
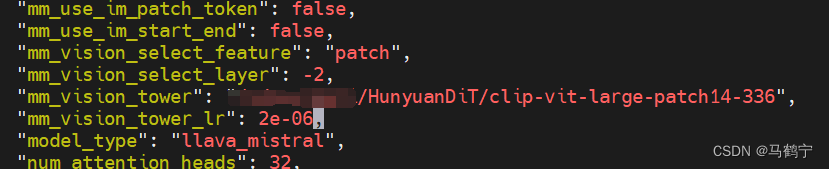
openai/clip-vit-large-patch14-336路径封装在库里面,离线环境无法跑推理。所以需要离线下载好clip-vit-large-patch14-336模型,然后将ckpts/dialoggen/config.json中的“mm_vision_tower”路径更改为clip-vit-large-patch14-336所在的位置。
示例
命令:python sample_t2i.py --prompt “渔舟唱晚”
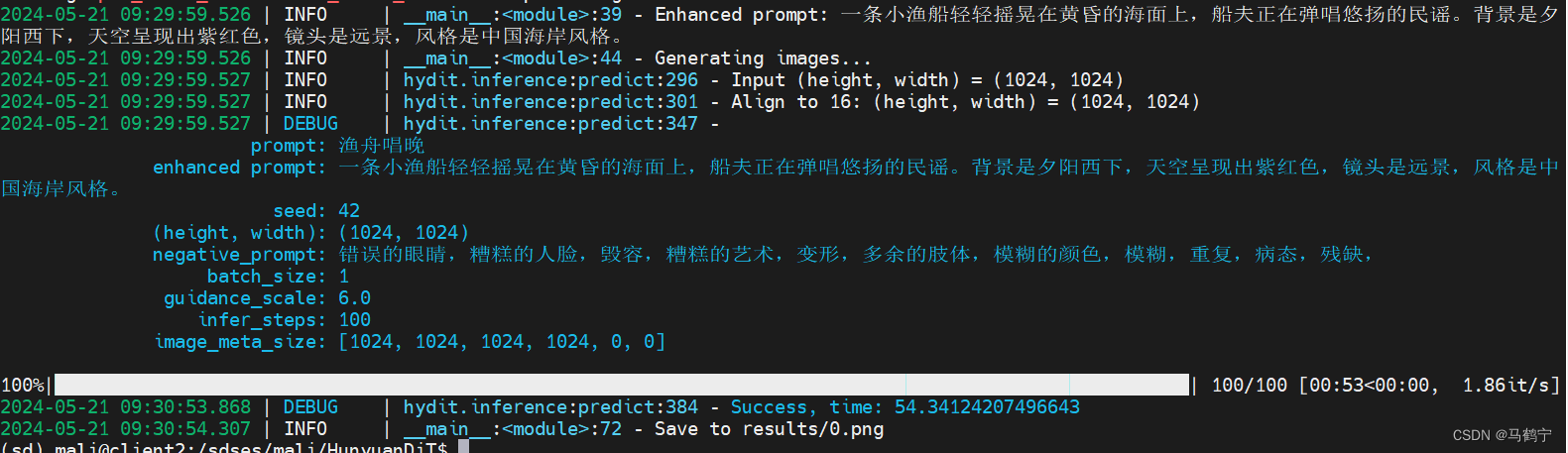
结果:

命令:python sample_t2i.py --prompt “一朵鲜艳的红色玫瑰花,花瓣撒有一些水珠,晶莹剔透,特写镜头,”
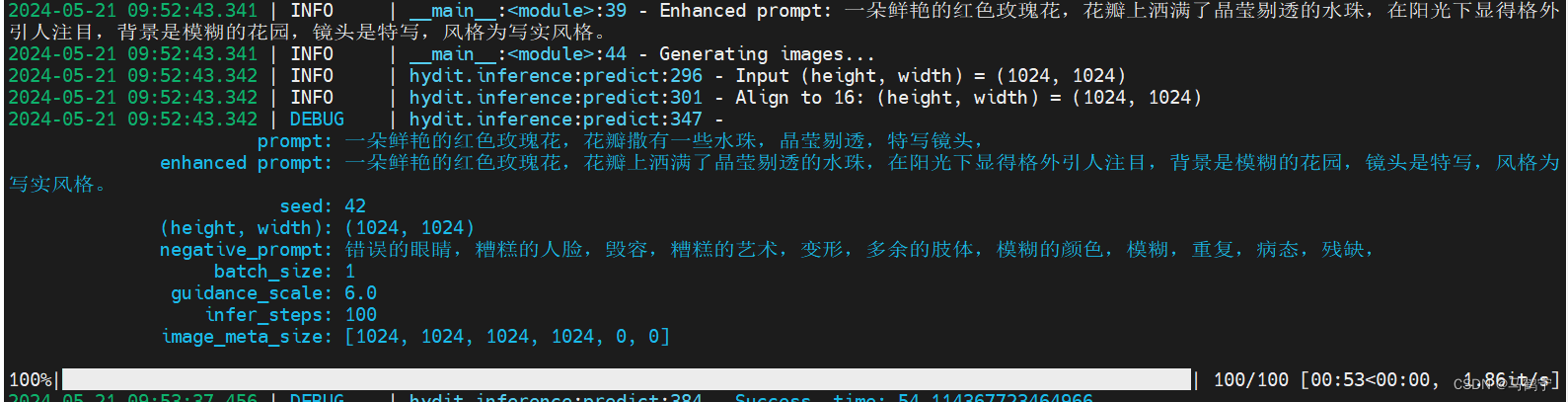
结果:

这朵玫瑰花不错,就是露水有点多。
运行实例时,特意留意了一下内存占用,在diffusion sampler的过程中,内存占用14G,最后两秒会上升到16G。
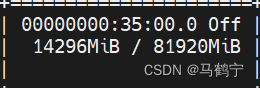
内存占用不高,但是加载模型的过程中特别慢,特别慢,特别慢!!!


















 1455
1455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











