







前言
在做数字人项目的过程中,需要对语音提取特征,比如DINet和ER-NeRF项目,都需要使用DeepSpeech进行语音特征提取。然而,DINet和ER-NeRF模型中使用的deepspeech模型都是基于英文音频数据集训练得到的。而我们用自己的视频进行训练时,音频是中文,使用中文的deepspeech模型是必要的。
deepspeech
DeepSpeech是一个开源的语音转文本引擎,基于百度的Deep Speech研究论文,使用机器学习技术训练的模型。DeepSpeech的模型框架使用的是谷歌的TensorFlow。
很坑的一点是,deepspeech在0.9.0版本的时候才开始提供普通话的预训练模型。我使用的是0.9.3版本。在此版本中,百度提供了英文和普通话的预训练模型,还有对应的.pbmm和.tflite模型。

.pbmm模型是DeepSpeech发布的一种模型格式,它主要是为了缓解.pb模型在运行推理时额外的加载时间和内存消耗。
.pbmm是DeepSpeech模型文件的一种格式。这个格式是TensorFlow的模型文件格式,用于存储训练好的深度学习模型。(来自于文心一言)
使用.pbmm模型可以快速进行语音转文本,但是我们在数字人项目中,需要提取语音特征,需要加载deepspeech模型,显然则需要.pb模型。
.pb模型转换
DeepSpeech模型中则提供了export成.pb和.tflite模型的代码。下载DeepSpeech官方提供的预训练checkpoints文件,使用命令行进行转换即可。
python DeepSpeech.py --noshow_progressbar \
--checkpoint_dir ../deepspeech_models/deepspeech-0.9.3-checkpoint/ \
--export_dir ../deepspeech_models/deepspeech-0.9.3-checkpoint-pb/ \
--export_batch_size -1 --n_steps -1
将英文的预训练模型转换成.pb模型,很顺利。但是当转换中文预训练模型时,则会报错。
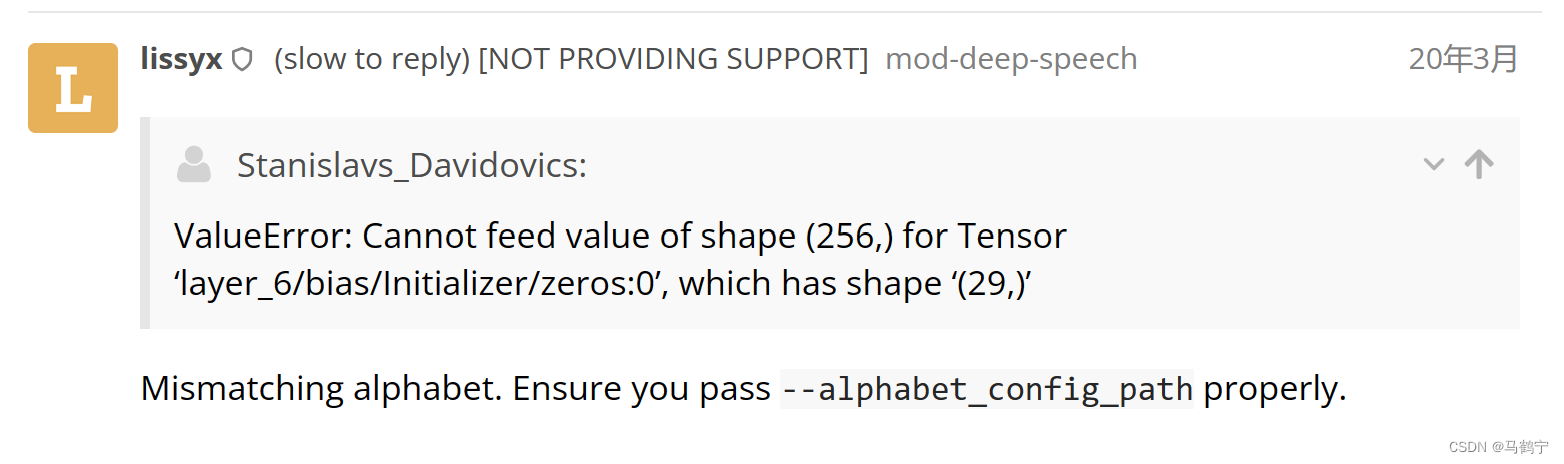
ValueError: Cannot feed value of shape (256,) for Tensor 'layer_6/bias/Initializer/zeros:0', which has shape '(29,)'
在issue里和discourse.mozilla中查找到的回答是Incorrect alphabet.,官方给出的alphabet.txt文件是英文的,26个字母加一个字符’和两个空格,shape是29。根据这个思路,制作中文的alphabet.txt即可。
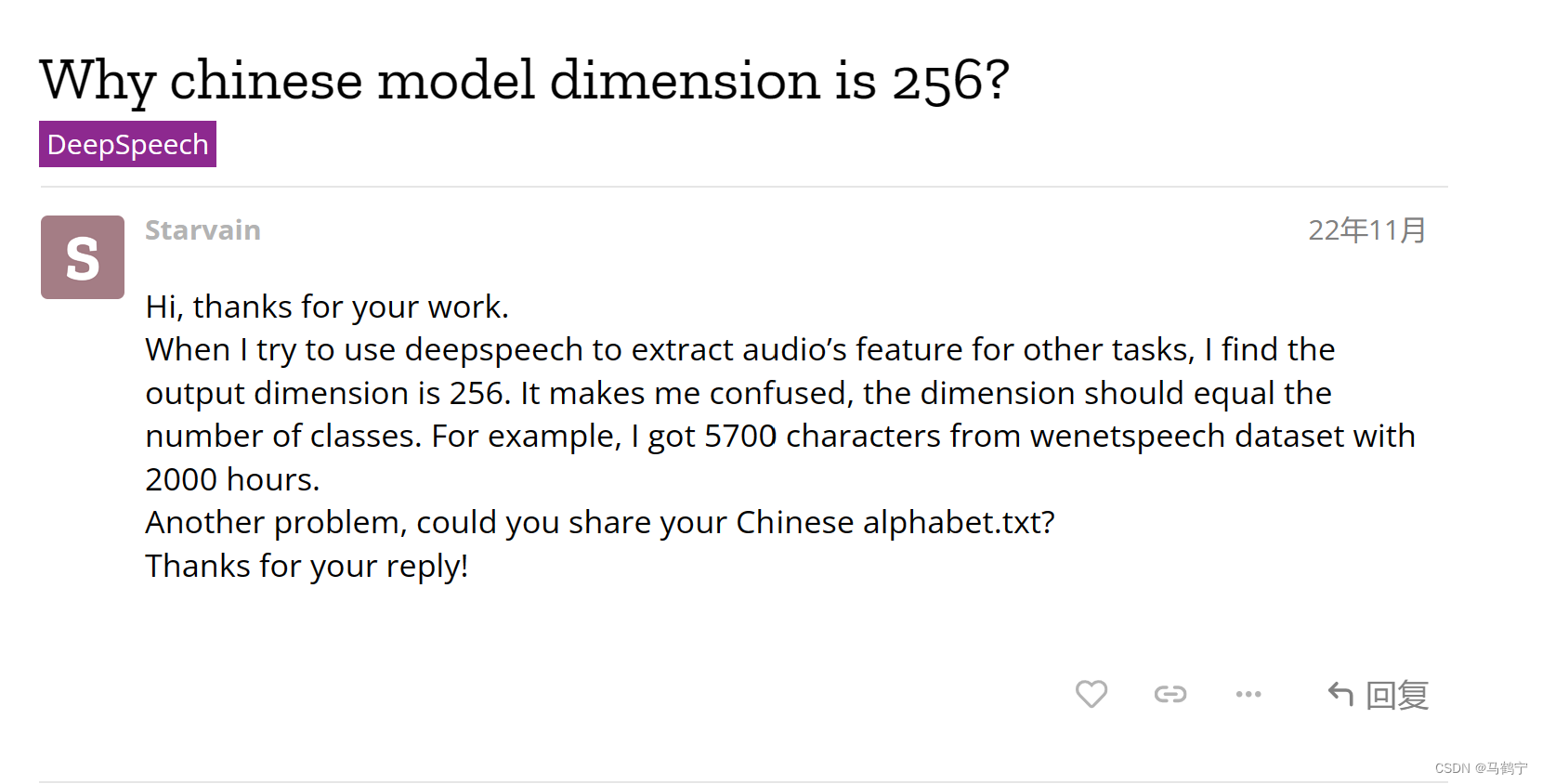
实际上,随便一个比较小的普通话语音数据集,按照官方给出的制作alphabet.txt方法,字符都得达到上千个。但是预训练模型模型的维度是256,256和上千个字符的alphabet的shape还是不一样,还是会报上述错误。那么为什么中文模型的维度是256呢?这个问题一直在网上找不到答案。
解决方案
在deepspeech官方文档训练你自己的模型中,有如下一段话。
DeepSpeech includes a UTF-8 operating mode which can be useful to model languages with very large alphabets, such as Chinese Mandarin.
在Decoder.rst中有如下一段话。
画红线的地方解释了那么为什么中文模型的维度是256。在训练和export成.pb模型时,不需要alphabet文件,仅仅需要 –bytes_output_mode即可。
# 中文模型export成.pb模型的命令行
python DeepSpeech.py --noshow_progressbar \
--checkpoint_dir ../deepspeech_models/deepspeech-0.9.3-checkpoint-zh-CN \
--export_dir ../deepspeech_models/deepspeech-0.9.3-checkpoint-zh-CN \
--export_batch_size -1 --n_steps -1 --bytes_output_mode
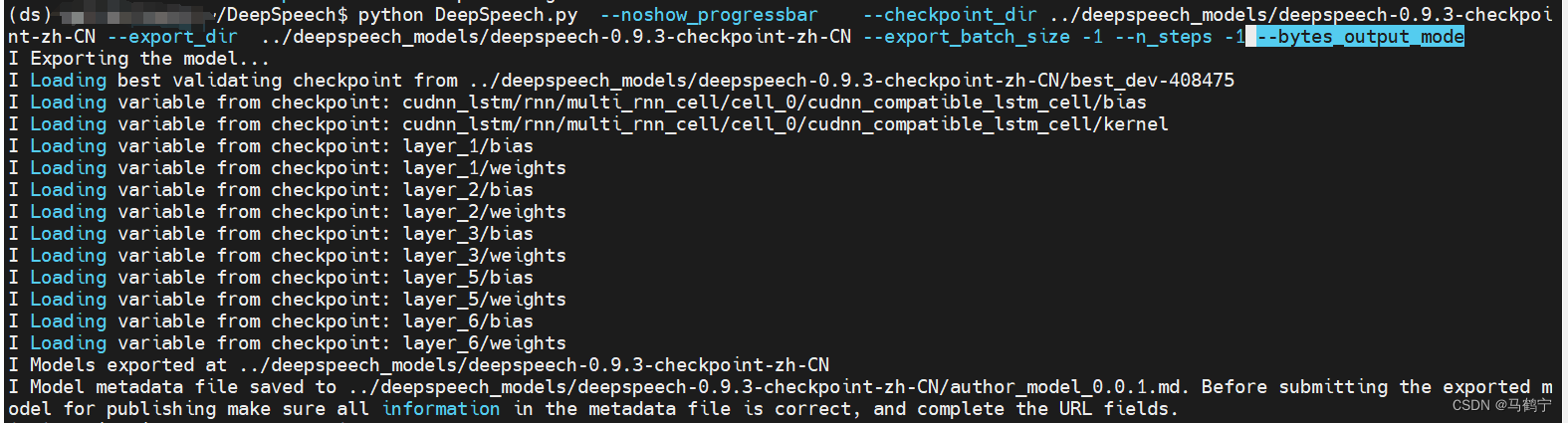
至此,将中文预训练模型转换成.pb模型的工作,完成。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











