







请注意,本文编写于 1195 天前,最后修改于 708 天前,其中某些信息可能已经过时。
前言
之前学校开的选修课《数据挖掘》,布置的两道算法题,时间有限完成其中一道:用Apriori算法求特定支持度的频繁项集。
算法本身不难,java萌新我却花费了一天的时间,特此记录。
算法描述
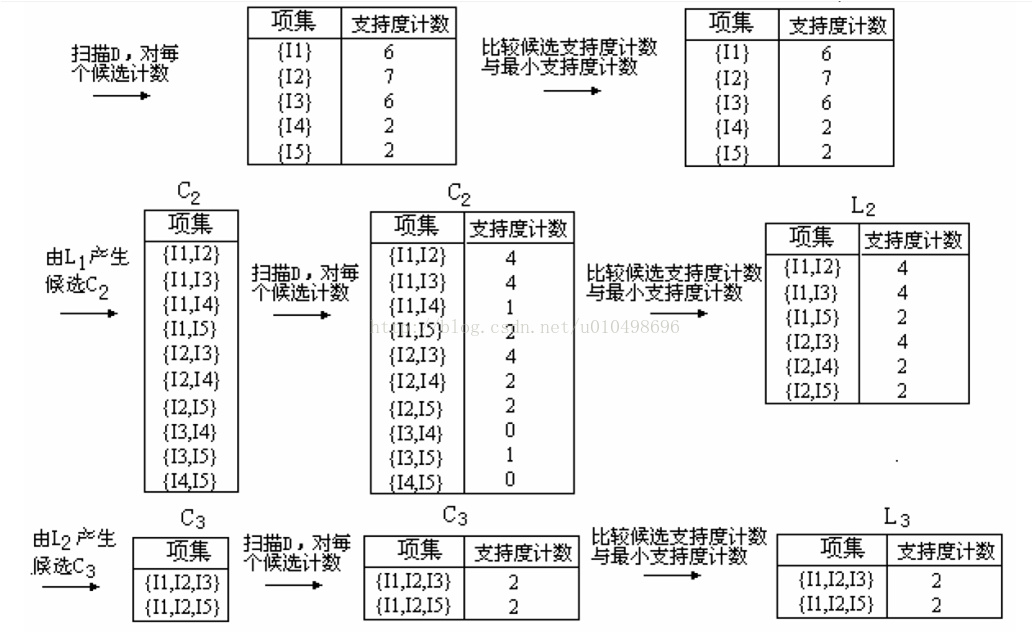
我们目的是求出项数为K的频繁项集即L(K)。
Apriori算法的核心步骤是:L(K-1)通过自连接求出项数为K的候选项集合C(K)
通过对C(K)进行一系列处理(剪枝 + 支持度判断) 得到L(K)集合
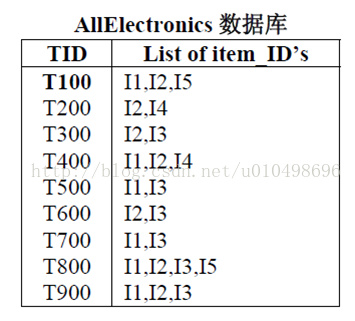
在说明下面更多内容之前,先对一部分概念进行说明:事务:如第一张图中,每一行就是一个事务,如 T100 I1,I2,I5。其中T100是事务编号,这个随便命名,只要保证唯一即可。后面的I1 I2 I5是该事务中的项
数据集:如图一,整个表就是数据集,就是所有的事务的集合。即D = {T100,T200…}
项集:包含若干个项(如I1 、I2这样的项)的集合。可以看出项集和事务似乎有点项。但是项集更随意一点,任意几个项都能组成一个项集。但是事务是人为规定好的。
可信度:项集在数据集中出现的重复次数。项集不一定需要在事务中连续出现。如{I1,I2,I5}项集在数据集中出现的次数为2次,分别是第一个和倒数第二个事务。
接下来,详细分析算法中的两个步骤:
1. 自连接:
怎么个连接法呢?以图二中的L2频繁集的集合为例:项集支持度{I1,I2}4
{I1,I3}4
{I1,I5}2
{I2,I3}4
{I2,I4}2
{I2,I5}2
判断两个项集是否可以自连接要看两个项集的K-1项是否完全相同。如果满足条件,连接后的项集 = 第一个项集 + 第二个项集的最后一个元素。
比如{I1 I2}与{I1 I3}满足自连接条件,连接后的项集为{I1 I2 I3}。
2. 剪枝:
剪枝是这个算法的核心,如果不进行这个步骤的话,也能得出正确结果,但是时间就会大大增加了。
剪枝的核心是若某个集合存在一个非空子集不是频繁项集,则该集合不是频繁项集。
我们通过自连接组成新的K项的候选项集后,需要通过剪枝判断是否满足条件。
即找出该候选项集的含有(K-1)项的子集,并分别判断每个子集是否存在于K-1项频繁项集里。只要有一个不存在,那么该K项候选项集也不可能是频繁项集。
这里我们只需要找含有K-1项的子集,而不用找所有的子集,因为这个算法是从下不断递归上来的,含有更少项的子集肯定是在频繁子集里的。
问题关键是怎么寻找某个K项集的K-1项子集呢?
很简单,依次把K项集中的每个元素去掉一个就可以了。
完成了这两步骤,就完成了这个算法了核心步骤。
3. 对精简后候选集统计每一个项集的支持度
4. 根据最小支持度将候选项集转换为K项频繁项集合
可以看出,如果不剪枝的话,第三步的工作量是非常大的。剪枝过后,候选集的体积大大减小了。
但是获取含有一项的频繁项集因为没有候选项集,就需要特殊处理。
这个很简单,就是统计数据集中的每一项的支持度,并和最小支持度进行比较,得到含有一项的频繁项集。
代码分析import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.*;
/**
* @author hw
* 算法名称:数据挖掘:Apriori算法求特性支持度下的所有的频繁集
* 算法原理:
*
* 0. 获取C1的时候,因为没有L(0)频繁集,所以单独
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1164
1164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









