






思路一:中心扩展法:就是把给定的字符串的每一个字母当做中心,向两边扩展,这样来找最长的子回文串。算法复杂度为O(N^2)。但是要考虑两种情况:1、像aba,这样长度为奇数。2、像abba,这样长度为偶数。
思路二:DP 思路:P[i][j]是记录i到j子串是不是回文串。P(i,j)={true,if the substring Si…Sj is a palindrome;false,if the substring Si…Sj is not a palindrome}。那么可以得到:
P(i,j)=(P(i+1,j−1) && Si==Sj)
思路三:Manacher’s Algorithm俗称马拉车算法,复杂度可以达到O(n)
1.求字符串中最长的回文子字符串。
回文串就是正读反读都一样的字符串,比如 “bob”, “level”, “noon” 等等,那么如何在一个字符串中找出最长回文子串呢,可以以每一个字符为中心,向两边寻找回文子串,在遍历完整个数组后,就可以找到最长的回文子串。但是这个方法的时间复杂度为O(n*n),并不是很高效,下面我们来看时间复杂度为O(n)的马拉车算法。
由于回文串的长度可奇可偶,比如"bob"是奇数形式的回文,"noon"就是偶数形式的回文,马拉车算法的第一步是预处理,做法是在每一个字符的左右都加上一个特殊字符,比如加上’#’,那么
bob --> #b#o#b#
noon --> #n#o#o#n#
这样做的好处是不论原字符串是奇数还是偶数个,处理之后得到的字符串的个数都是奇数个,这样就不用分情况讨论了,而可以一起搞定。接下来我们还需要和处理后的字符串t等长的数组p,其中p[i]表示以t[i]字符为中心的回文子串的半径,若p[i] = 1,则该回文子串就是t[i]本身,那么我们来看一个简单的例子:# 1 # 2 # 2 # 1 # 2 # 2 #
1 2 1 2 5 2 1 6 1 2 3 2 1
为啥我们关心回文子串的半径呢?看上面那个例子,以中间的 ‘1’ 为中心的回文子串 “#2#2#1#2#2#” 的半径是6,而为添加井号的回文子串为 “22122”,长度是5,为半径减1。这是个普遍的规律么?我们再看看之前的那个 “#b#o#b#”,我们很容易看出来以中间的 ‘o’ 为中心的回文串的半径是4,而 “bob"的长度是3,符合规律。再来看偶数个的情况"noon”,添加井号后的回文串为 “#n#o#o#n#”,以最中间的 ‘#’ 为中心的回文串的半径是5,而 “noon” 的长度是4,完美符合规律。所以我们只要找到了最大的半径,就知道最长的回文子串的字符个数了。只知道长度无法确定子串,我们还需要知道子串的起始位置。
我们还是先来看中间的 ‘1’ 在字符串 “#1#2#2#1#2#2#” 中的位置是7,而半径是6,貌似7-6=1,刚好就是回文子串 “22122” 在原串 “122122” 中的起始位置1。那么我们再来验证下 “bob”,“o” 在 “#b#o#b#” 中的位置是3,但是半径是4,这一减成负的了,肯定不对。所以我们应该至少把中心位置向后移动一位,才能为0啊,那么我们就需要在前面增加一个字符,这个字符不能是井号,也不能是s中可能出现的字符,所以我们暂且就用美元号吧,毕竟是博主最爱的东西嘛。这样都不相同的话就不会改变p值了,那么末尾要不要对应的也添加呢,其实不用的,不用加的原因是字符串的结尾标识为’\0’,等于默认加过了。那此时 “o” 在 “KaTeX parse error: Expected 'EOF', got '#' at position 1: #̲b#o#b#" 中的位置是4,…#1#2#2#1#2#2#” 中的位置是8,而半径是6,这一减就是2了,而我们需要的1,所以我们要除以2。之前的 “bob” 因为相减已经是0了,除以2还是0,没有问题。再来验证一下 “noon”,中间的 ‘#’ 在字符串 “$#n#o#o#n#” 中的位置是5,半径也是5,相减并除以2还是0,完美。可以任意试试其他的例子,都是符合这个规律的,最长子串的长度是半径减1,起始位置是中间位置减去半径再除以2。
那么下面我们就来看如何求p数组,需要新增两个辅助变量mx和id,其中id为能延伸到最右端的位置的那个回文子串的中心点位置,mx是回文串能延伸到的最右端的位置,这个算法的最核心的一行如下:
p[i] = mx > i ? min(p[2 * id - i], mx - i) : 1;
可以这么说,这行要是理解了,那么马拉车算法基本上就没啥问题了,那么这一行代码拆开来看就是
如果 mx > i, 则 p[i] = min( p[2 * id - i] , mx - i )
否则,p[i] = 1
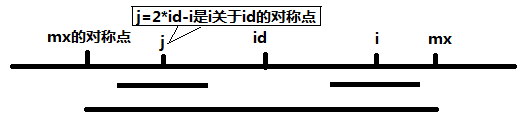
当 mx - i > P[j] 的时候,以S[j]为中心的回文子串包含在以S[id]为中心的回文子串中,由于 i 和 j 对称,以S[i]为中心的回文子串必然包含在以S[id]为中心的回文子串中,所以必有 P[i] = P[j],见下图。
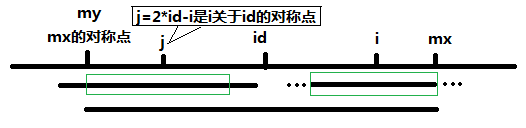
当 P[j] >= mx - i 的时候,以S[j]为中心的回文子串不一定完全包含于以S[id]为中心的回文子串中,但是基于对称性可知,下图中两个绿框所包围的部分是相同的,也就是说以S[i]为中心的回文子串,其向右至少会扩张到mx的位置,也就是说 P[i] = mx - i。至于mx之后的部分是否对称,就只能老老实实去匹配了。
对于 mx <= i 的情况,无法对 P[i]做更多的假设,只能P[i] = 1,然后再去匹配了。
三)如何求数组P [ ]
从左往右计算数组P[ ], Mi为之前取得最大回文串的中心位置,而R是最大回文串能到达的最右端的值。
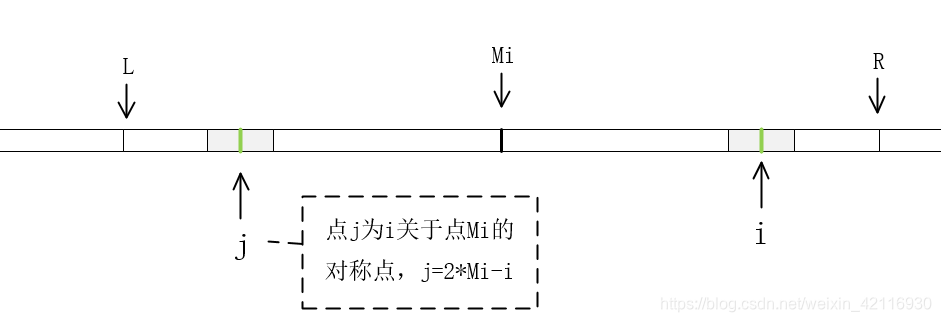
1)当 i <=R时,如何计算 P[ i ]的值了?毫无疑问的是数组P中点 i 之前点对应的值都已经计算出来了。利用回文串的特性,我们找到点 i 关于 Mi 的对称点 j ,其值为 j= 2*Mi-i 。因,点 j 、i 在以Mi 为中心的最大回文串的范围内([L ,R]),
a)那么如果P[j] <R-i (同样是L和j 之间的距离),说明,以点 j 为中心的回文串没有超出范围[L ,R],由回文串的特性可知,从左右两端向Mi遍历,两端对应的字符都是相等的。所以P[ j ]=P[ i ](这里得先从点j转到点i 的情况),如下图:
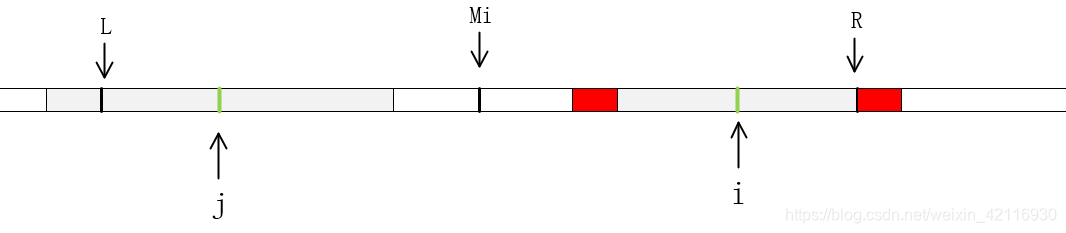
b)如果P[ j ]>=R-i (即 j 为中心的回文串的最左端超过 L),如下图所示。即,以点 j为中心的最大回文串的范围已经超出了范围[L ,R] ,这种情况,等式P[ j ]=P[ i ]还成立吗?显然不总是成立的!因,以点 j 为中心的回文串的最左端超过L,那么在[ L, j ]之间的字符肯定能在( j, Mi ]找到相等的,由回文串的特性可知,P[ i ] 至少等于R- i,至于是否大于R-i(图中红色的部分),我们还要从R+1开始一一的匹配,直达失配为止,从而更新R和对应的Mi以及P[ i ]。
2)当 i > R时,如下图。这种情况,没法利用到回文串的特性,只能老老实实的一步步去匹配。

C++实现代码:
#include <vector>
#include <iostream>
#include <string>
using namespace std;
string Manacher(string s) {
// Insert '#'
string t = "$#";
for (int i = 0; i < s.size(); ++i) {
t += s[i];
t += "#";
}
// Process t
vector<int> p(t.size(), 0);
int mx = 0, id = 0, resLen = 0, resCenter = 0;
for (int i = 1; i < t.size(); ++i) {
p[i] = mx > i ? min(p[2 * id - i], mx - i) : 1;
while (t[i + p[i]] == t[i - p[i]]) ++p[i];
if (mx < i + p[i]) {
mx = i + p[i];
id = i;
}
if (resLen < p[i]) {
resLen = p[i];
resCenter = i;
}
}
return s.substr((resCenter - resLen) / 2, resLen - 1);
}
int main() {
string s1 = "12212";
cout << Manacher(s1) << endl;
string s2 = "122122";
cout << Manacher(s2) << endl;
string s = "waabwswfd";
cout << Manacher(s) << endl;
}














 3811
3811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









