







什么是线程池?
线程池就是存放线程的池子,而池子里的线程可以复用,对线程进行统一调度管理,避免过多线程导致影响到整体的性能。
线程池的优点?
- 降低资源消耗:线程池中的线程可以重复使用,不需要频繁的创建和销毁线程,从而降低了资源消耗。
- 提高响应速:线程池中的线程可以复用,当任务来了之后,可以直接执行任务,提高响应速度 。
- 线程可管理:线程池对线程进行了统一管理,可以有效的避免无限制创建线程耗尽系统资源。
线程池的核心参数:
- 核心线程数(corePoolSize):线程池没有执行过任务的时候,核心线程数为 0,有任务进入线程池后,直接创建 corePoolSize 个线程,核心线程会一直保留,直到线程池销毁。
- 最大线程数(maxPoolSize):当核心线程数已满,且阻塞队列也已经满了,判断核心线程数是否小于最大线程数,如果小于就继续创建线程,否则执行拒绝策略,当最大线程空闲之间达到空闲线程保留时间就会被销毁。
- 空闲线程保留时间(keepAliveTime):只有在最大线程数大于核心线程数的时候才会生效,用来判断最大线程的空闲时间,如果超过这个时间还没有任务执行,最大线程就会被销毁。
- 时间单位(TimeUnit):空闲线程保留时间的单位。
- 工作队列(workQueue):当核心线程数已经满了,此时再有任务进来就放进工作队列中。
- 拒绝策略(handler):当最大线程也满了的时候,如果还有任务进入线程池,此时就执行拒绝策略。
上述的 6 个参数我们需要重点关注核心线程数、最大线程数、工作队列、拒绝策略这几个参数,核心线程数、最大线程数设置不合理,不仅会影响效率,也可能会导致资源耗尽,工作队列如果设置过大,可能会导致系统 OOM,handler 设置不当,可能会得不到你想要的异常信息。
拒绝策略(handler)有几种?
JDK 为我们默认了四种拒绝策略,如下:
- AbortPolicy:默认的拒绝策略,丢弃任务并抛出 RejectedExecutionException 异常。
- CallerRunsPolicy:由任务调用线程来处理当前任务。
- DiscardPolicy:丢弃任务,不抛出任何异常,可以扩展这种拒绝策略实现自定义的拒绝策略。
- DiscardOldestPolicy:丢弃队列中最早的未处理任务,然后将当前任务入队或者处当前任务(入队还是直接处理要看线程池的状态)。
四种拒绝策略的源码如下,拒绝策略的源码非常简单,就不一一分析了。
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
public static class DiscardPolicy implements RejectedExecutionHandler {
public DiscardPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public DiscardOldestPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
线程池的工作顺序:
核心线程数-> 工作队列 -> 最大线程数-> 拒绝策略
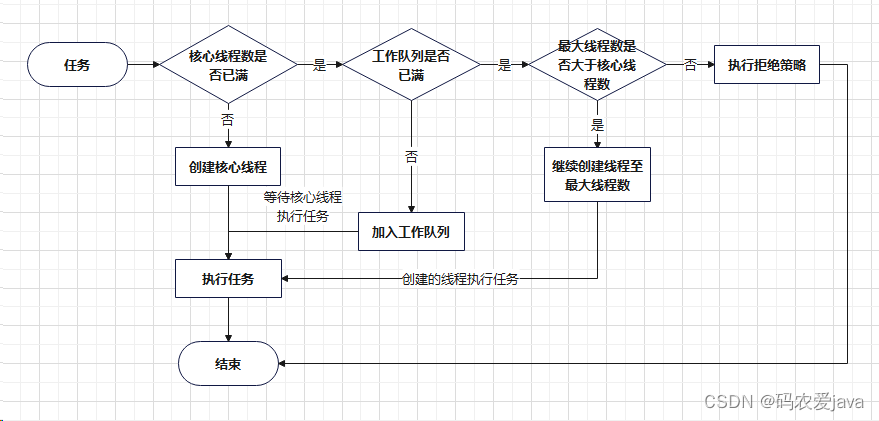
上述流程图可以帮助更好的去理解线程池的工作流程,线程池的工作流程还是比较简单的,这里就不对流程图进行一一解析了。
Executors 四种线程池比较
Executors 类提供了4种创建线程池的方法,这些方法最终都是通过配置不同的参数,来达到不同的线程池效果。
newFixedThreadPool
定长线程池,最大线程数和核心线程数一样,可以控制最大并发数量,来不及执行的任务将会进入队列进行等待。
newFixedThreadPool 线程池源码如下:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
源码可以看出线程池的核心线程数、最大线程数是同一个值,都是 nThreads,因此空闲线程保留时间参数就没有价值了,所以空闲线程保留时间为 0,需要注意的是队列使用 LinkedBlockingQueue 无界队列的方式,当线程数达到 nThreads 后,新任务将会放到队列中,因为队列是无界队列,有任务可以一直往队列中放,当任务足够多的时候,会造成系统 OOM。
newSingleThreadExecutor
单线程线程池,线程池中只有一个线程,可以理解为定长线程池的极端版本,来不及执行的任务同样会进入队列。
newSingleThreadExecutor 源码如下:
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
通过源码我们看到核心线程数和最大线程数都是 1,同样空闲线程保留时间参数就没有价值了,所以空闲线程保留时间也为 0,队列同样用的是 LinkedBlockingQueue 无界队列,线程来不及执行的任务将会放到队列中,因为队列是无界队列,有任务可以一直往队列中放,当任务足够多的时候,也同样会造成系统 OOM。
newCachedThreadPool
缓存线程池,一个可以缓存线程的线程池,这里的缓存的意思并不是把核心线程或者最大线程进行缓存,而是当当线程数大于需要处理的任务数的时候,则会把空闲时间大于 60 秒的线程销毁,而当任务数大于线程数的时候,就创建线程处理任务,队列使用 SynchronousQueue无缓存的方式。
newCachedThreadPool 源码分析:
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
根据源码我们知道缓存线程池的核心线程为 0,最大线程为 Integer.MAX_VALUE,线程空闲时间是 60 秒,队列使用 SynchronousQueue,因此当有任务进来没有空闲线程的时候,就会一直创建线程处理任务,这样可能会导致 cpu 耗尽或者 OOM 发生。
newScheduledThreadPool
创建一个支持定时、周期任务的线程池,我们直接来看源码。
//Executors 类 newScheduledThreadPool
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
//ScheduledThreadPoolExecutor 类
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
根据源码我们知道,newScheduledThreadPool 线程池的核心线程数为 corePoolSize,最大线程数为 Integer.MAX_VALUE,线程空闲等待时间为 0,也就是当线程大于核心线程数时候,线程执行完任务立即销毁,队列使用DelayedWorkQueue延迟队列,可以设置延时时间,当任务达到延时时间,才从队列出队被线程池执行,同样因为最大线程数为 Integer.MAX_VALUE,当任务足够多的时候,会创建大量线程,造成系统 OOM。
自定义线程池
鉴于 Executors 提供四种线程池各方面存在的一些问题,实际项目开发中,我们一般使用 ThreadPoolExecutor 结合业务需求和服务器性能,合理的选择 corePoolSize、maximumPoolSize、keepAliveTime、workQueue、handler 来自定义创建线程池。
自定义线程池我们最需要关注的两点就是核心线程数和队列大小,核心线程数选择不合理,可能会导致 cpu 空闲和系统 OOM 的情况,同时队列数不宜过大,否则也会导致 OOM 的情况发生。
自定义线程案例:
@Configuration
public class ReportThreadPoolConfig {
@Value("${report.pool.corePoolSiZe}")
private Integer corePoolSiZe;
@Value("${report.pool.maxPoolSize}")
private Integer maxPoolSize;
@Value("${report.pool.queueCapacity}")
private Integer queueCapacity;
@Value("${report.pool.keepAliveSeconds}")
private Integer keepAliveSeconds;
@Bean(name = "reportExecutor")
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(corePoolSiZe);
executor.setMaxPoolSize(maxPoolSize);
executor.setQueueCapacity(queueCapacity);
executor.setKeepAliveSeconds(keepAliveSeconds);
executor.setThreadNamePrefix("report-query-");
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.initialize();
return executor;
}
}
//自定义线程池使用
@Resource
private ThreadPoolTaskExecutor reportExecutor;
public void executeTask() {
reportExecutor.execute(() -> {
System.out.println("线程池执行任务");
});
}
从代码可以看出实现自定义线程池还是非常简单的,只需要创建一个 ThreadPoolTaskExecutor 对象,并合理设置 6 个核心参数即可完成自定义线程池的创建。
线程池的线程数如何设置?
一般根据线程执行任务类型来合理设置核心线程数,任务分为CPU密集型和IO密集型,根据不同的任务类型,线程池设置参数的思想不同。
- CPU 密集型:这种任务比较消耗 CPU 资源,可以将线程数设置为 CPU 核心数+1,多出的一个线程是为了防止线程偶发的缺页中断,或者其他原因导致任务暂停而引起的 CPU 空闲。
- IO 密集型:IO 密集型任务运行起来系统大部分时间来处理 IO 交互,线程在处理 IO 交互的时候不会占用 CPU,这时可以将 CPU 交出给其他线程使用,因此在进行 IO 密集型任务的应用中,可以多配置一些线程,一般可以配置为 2N(N 为 CPU 核心数)。
以上是根据对任务的类型去根据经验设置线程池的线程数,那对于一个具体的场景,我们又该如何去合理设置线程池的线程数量呢?
1、比如我有台机器每秒产生50个任务,每个任务执行1秒,CPU 是 2 核,你该如何设置线程池的线程数量?
2、又比如任务是混合型(既包含IO密集型,又包含CPU密集型),我们又改如何合理的设置线程池的线程数?
3、还有对于当个任务它通用即比较消耗 CPU 又比较消耗 IO,我们又改如何合理的设置线程池的线程数?
针对复杂场景的任务,仅凭经验去设置线程池的核心线程数,显然不能很好的利用机器性能去处理任务。
线程池最佳线程数量:
除了根据经验得出线程数量之外,其实还有标准化计算公式,如下:
最佳线程数目 = ((线程等待时间 + 线程 CPU 时间)/ 线程 CPU 时间 )* CPU 数目
举例:
比如平均每个线程 CPU 运行时间为 0.5 s,而线程等待时间(非CPU运行时间,比如IO)为1.5s,CPU 核心数为 8,那么根据上面这个公式估算得到:(( 0.5 + 1.5 )/ 0.5)* 8 = 32,即最佳线程数量为 32 个。
上面的公式可以进一步转化为:
最佳线程数目 = (线程等待时间与线程 CPU 时间之比 + 1 )* CPU数目
如有错误的地方欢迎指出纠正。














 236
236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









