







前言
千问模型如果不安装flash-attention,推理速度会很慢,这个1.8B模型上看不出来,7B模型就非常明显了。
7B模型光启动起来,就差不多占用15GB的显存了,对于我这个电脑就已经在爆显存的边缘了。
1、简介
为了加速推理,以及降低显存占用,千问官方提供了flash-attention的方式进行加速。flash-attention的加速原理如下,主要是通过降低SRAM和HBM之间的数据交换次数来提高推理速度,有兴趣的可以进一步学习:

2、flash-attention安装
千问提供的方式:

在实际的执行过程中,会出现报错:

以下是正确的安装方法:
先安装packaging和nanja库:
pip install packaging
pip install ninja到对应的网址去下载预编译文件:
Linux环境:
https://github.com/Dao-AlLab/flash-attention/releases
Releases · Dao-AILab/flash-attention (github.com)
windows环境:
Releases · bdashore3/flash-attention · GitHub
一定要选择适合自己cuda、torch已经python版本的包:

切换对应的文件夹,执行:
pip install "flash_attn-2.5.7+cu122torch2.2cxx11abiTRUE-cp311-cp311-linux_x86_64.whl"windows系统,除此之外还要安装C++扩展,使用以下的网址,
Microsoft C++ 生成工具 - Visual Studio
下载编译工具:

再安装rotary库:
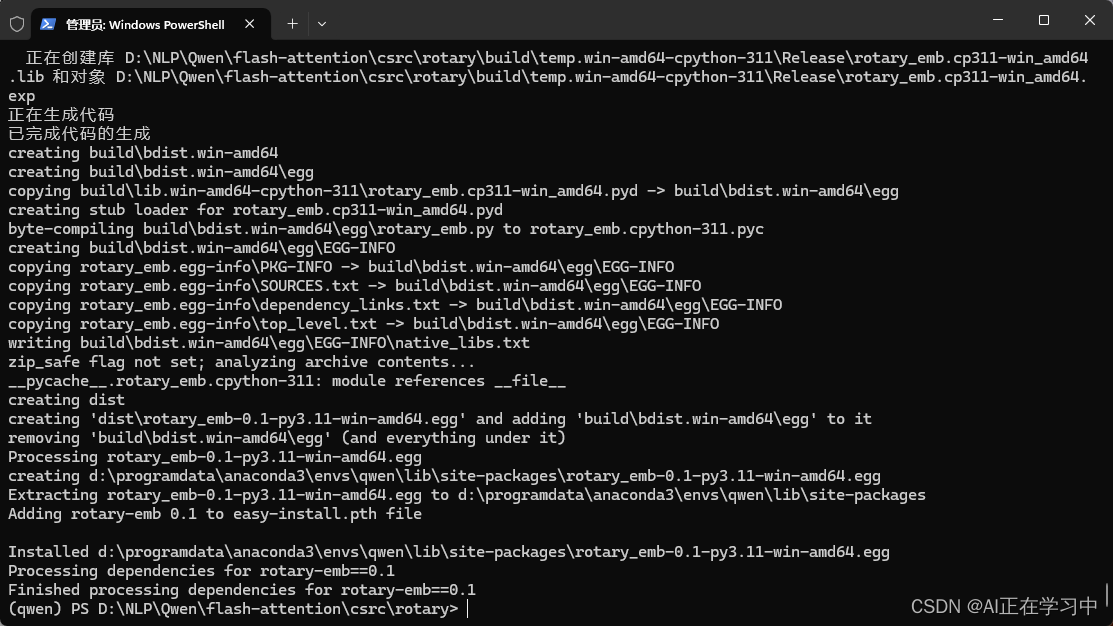
cd到flash-attention\csrc\rotary目录下执行:
# 设置同时运行任务数量为4
set MAX_JOBS=4
# 安装rotary库
python setup.py install
执行完成:
3、测试
安装到这一步,就算安装完成了,现在重新启动模型的脚本。
启动脚本:
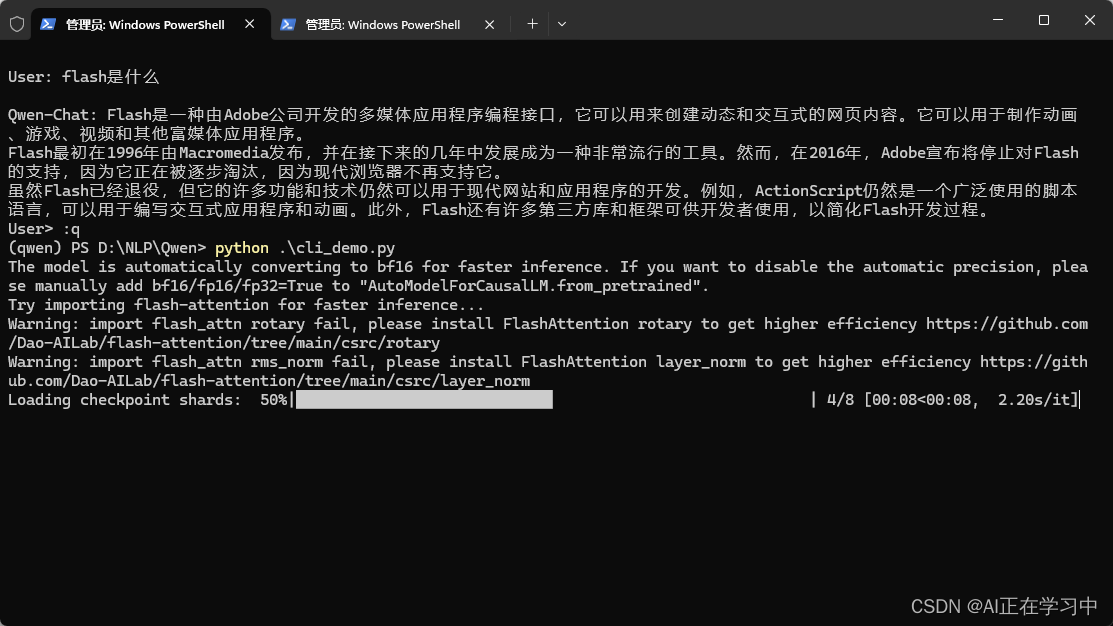
仍然会出现警告信息...(可能是windows系统不兼容的原因,暂时未找到可用办法)
查看GPU的占用率:

显存确实是降低了。证明flash_attention还是有效果的。
进行对话测试:
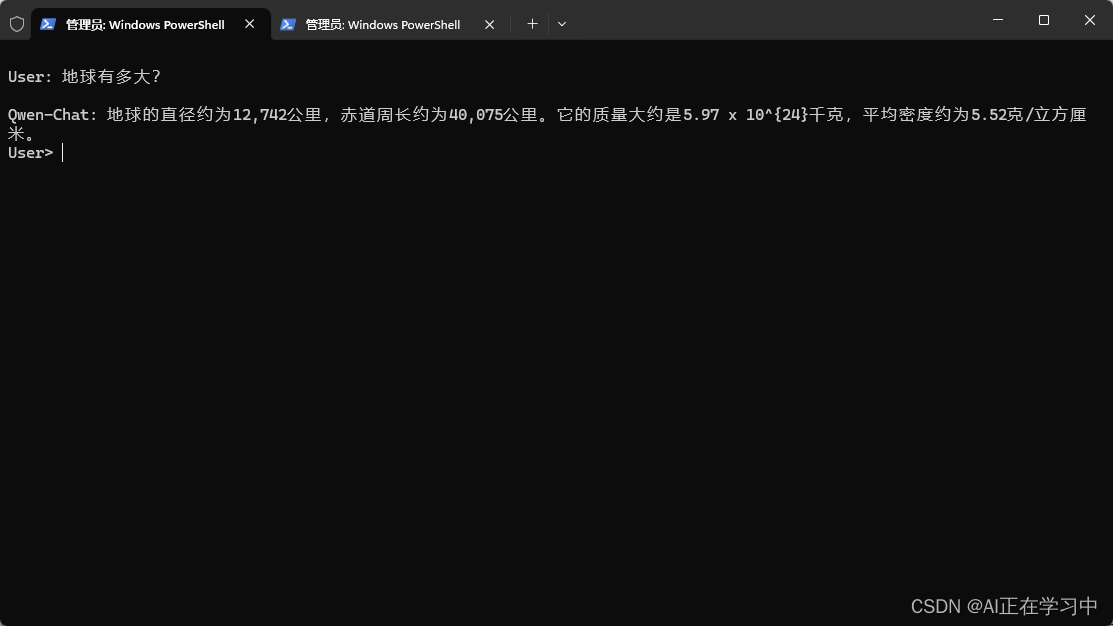
对话变得比之前要快速一些,但也不是特别明显。
查看GPU占用:
启动时:

推理时:

还是有很明显的降低显存和加速的作用的。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









