







前言
本文记录了使用本地部署的Qwen模型,调用外部API实现模型的功能增强,非常的易用,大家用于开发自己的应用,只需要作简单的修改就可以进行使用了。
本文的代码来源视频教程:
Qwen大模型变强了,通过API调用外部工具给Qwen模型有效赋能,ReAct实践,API工具调用_哔哩哔哩_bilibili
(手动敲出来的,呜呜~)
代码实现过程
启动模型
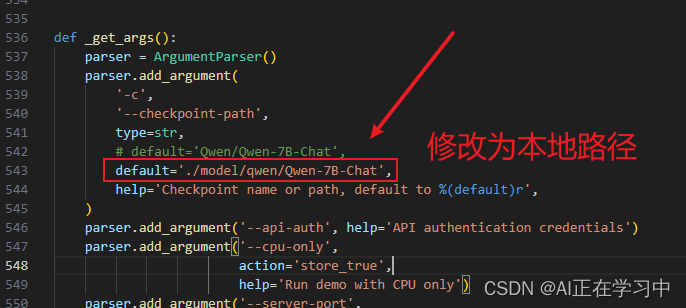
先启动Qwen模型的Openai-api访问的服务:
修改模型路径为本地:
启动api服务

ps:可以看到我先切换到千问的虚拟环境中,且在模型的路径下执行。
主要笔记代码
调用本地部署的模型
# 调用本地部署的Qwen模型
import openai
openai.api_base = 'http://127.0.0.1:8000/v1'
openai.api_key = 'none'尝试进行通用的对话:
messages = [{'role': 'user', 'content': '你好,请你详细介绍一下你自己。'}]
response = openai.ChatCompletion.create(
model='Qwen',
messages=messages,)
response.choices[0].message['content']'你好!我叫通义千问,是由阿里云自主研发的预训练语言模型。我的目的是通过理解和生成自然语言来帮助人类完成各种任务,如回答问题、提供建议、生成代码、聊天等。\n\n我是基于Transformer架构设计的,拥有大量的文本数据作为训练资源,经过多轮迭代和优化,我已经具备了强大的语言处理能力。我可以理解复杂的语句结构和上下文关系,并能够根据输入的问题或指令生成相应的回复。\n\n在使用过程中,你可以通过简单的文本交互与我进行沟通,我会尽力提供准确、有用的回答。如果你有任何问题或者需要帮助,请随时告诉我,我会尽力为你提供支持。'
可以看到模型能够正确的通过Openai_api进行访问,如果不能访问,按照提示进行相关库的安装即可:
例如我这里缺少这个库:

再次用到之前的例子
先模拟数据库和查询方法
# 用JSON格式模拟数据库j
class CourseDatabase:
def __init__(self):
self.database = {
"大模型技术实战":{
"课时": 200,
"每周更新次数": 3,
"每次更新小时": 2
},
"机器学习实战":{
"课时": 230,
"每周更新次数": 2,
"每次更新小时": 1.5
},
"深度学习实战":{
"课时": 150,
"每周更新次数": 1,
"每次更新小时": 3
},
"AI数据分析":{
"课时": 10,
"每周更新次数": 1,
"每次更新小时": 1
},
}
def course_query(self, course_name):
return self.database.get(course_name, "目前没有该课程信息")模拟数据库操作
# 用JSON格式模拟数据库j
class CourseOperations:
def __init__(self):
self.db = CourseDatabase()
def add_hours_to_course(self, course_name, additional_hours):
if course_name in self.db.database:
self.db.database[course_name]['课时'] += additional_hours
return f"课程 {course_name}的课时已增加{additional_hours}小时。"
else:
return "课程不存在,无法添加课时"添加工具库:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2625
2625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









