









scrapy爬虫初学者学习过程-----精通Python爬虫框架scrapy
视频资源链接:https://www.bilibili.com/video/BV1P4411f7rP?p=78
参考书:精通Python爬虫框架scrapy
作者:Irain
QQ联系方式:2573396010
微信:18802080892
安装和文档
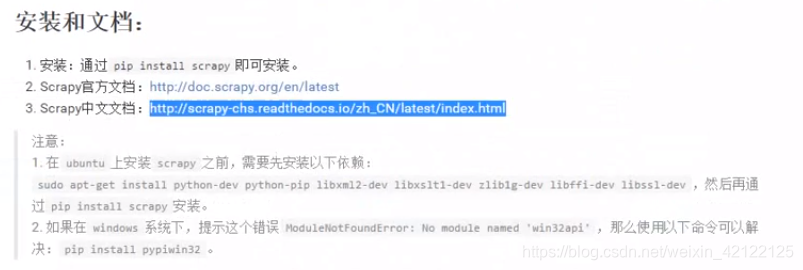
在DOC命令使用命令行爬取百度网页:
scrapy shell https://www.baidu.com # scrapy shell + 目标网站

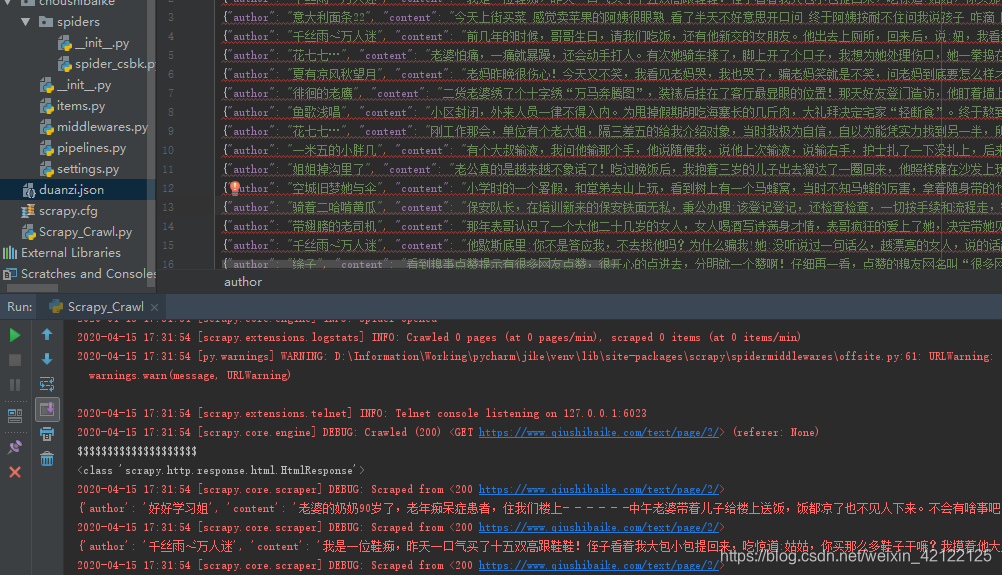
爬取百度网页成功、状态码:200

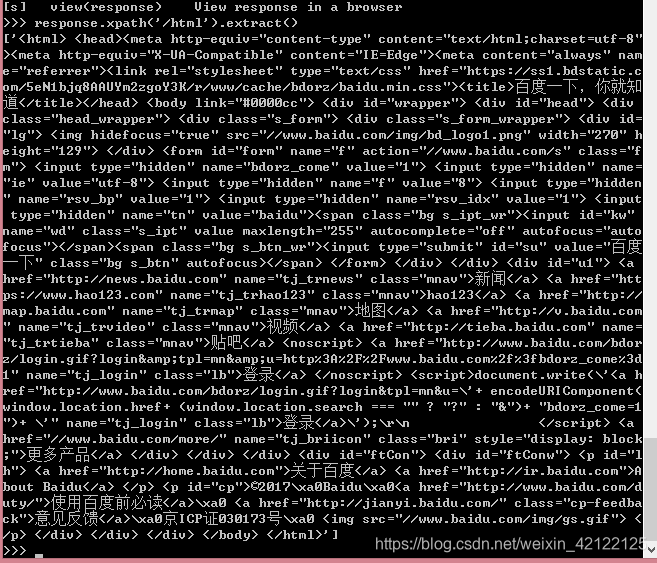
使用xpath语言从HTML文本抽取目标内容
response.xpath('/html').extract() # 服务器反馈给客户端浏览器的内容HTML文本,存入response中。

百度网页HTML整个文本
第一次发布:2020年4月14日
一、创建项目和爬虫

1.创建项目

2.在项目创建爬虫

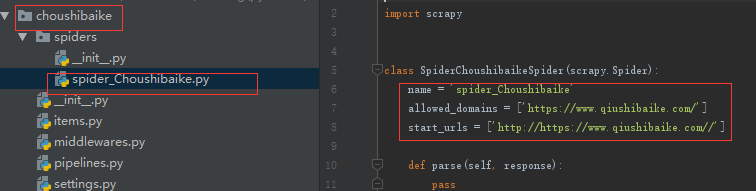
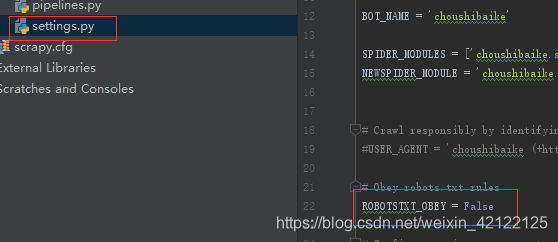
二、新项目的setting设置:
1.ROBOTSTXT_OBEY
ROBOTSTXT_OBEY = False # TRUE 改为 False 是否访问完整的根目录文件。如果访问中该文件不存在,则服务器返回为空
2.在请求头添加User-Agent
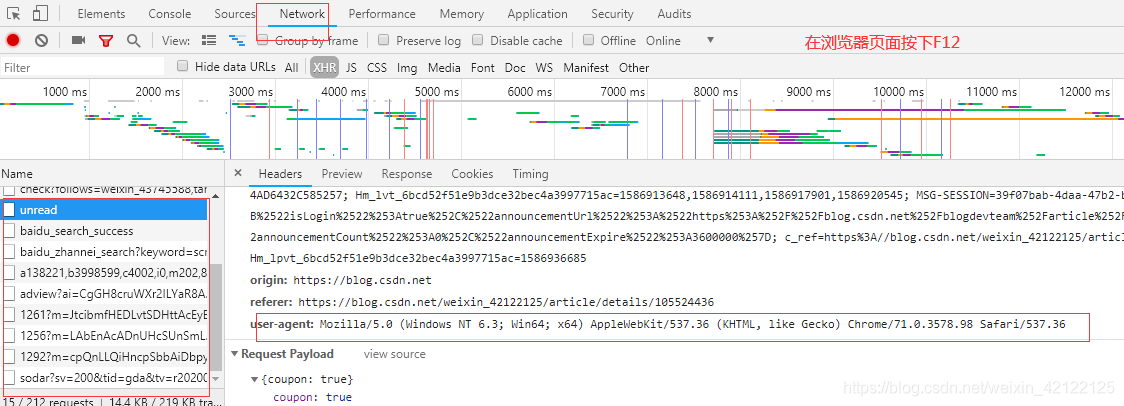

三、执行爬虫
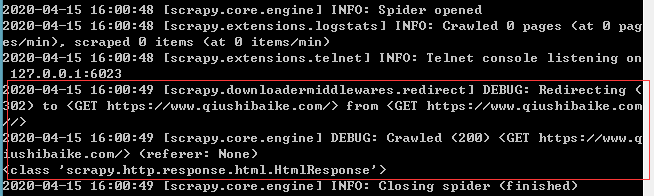
1.在DOC窗口执行爬虫
scrapy crawl spider_Choushibaike # 在爬虫项目的目录下运行该命令

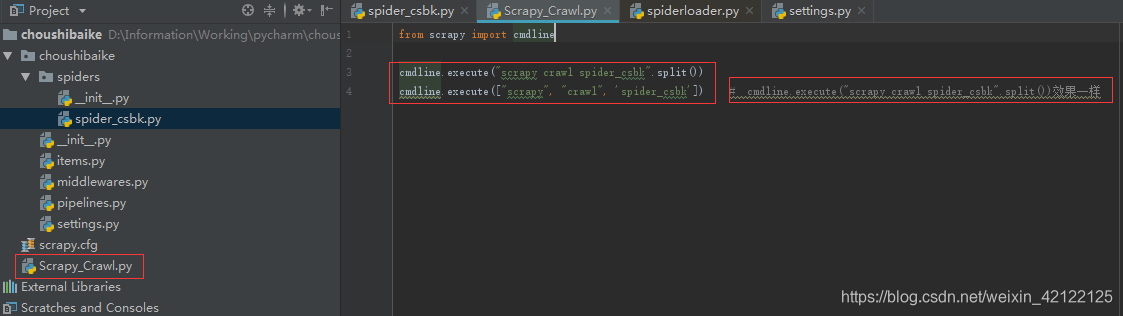
2.项目里执行爬虫
每次在DOC窗口下执行命令,会多做些不可必要的操作。在项目里建立一个py文件,减少不必要的时间和操作。
from scrapy import cmdline
cmdline.execute("scrapy crawl spider_csbk".split())
cmdline.execute(["scrapy", "crawl", 'spider_csbk']) # cmdline.execute("scrapy crawl spider_csbk".split())效果一样
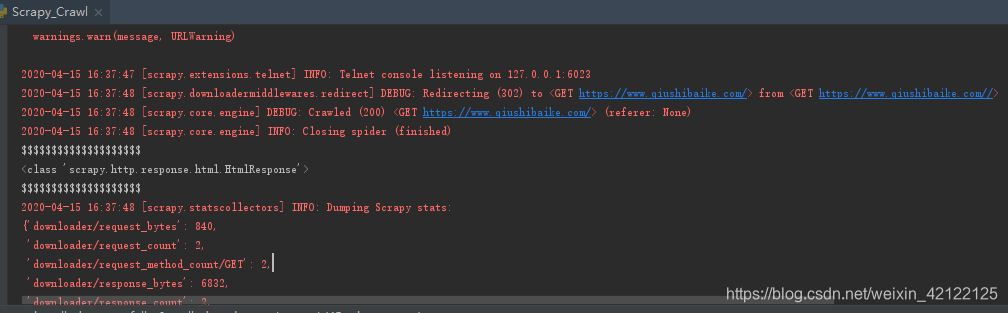
执行情况
四、使用管道pipeline.py
参考链接:https://yq.aliyun.com/articles/693333
pipeline.py文件中,pipeline类不需要继承特定的基类,只需要实现特定的方法如:
open_spider:爬虫运行前执行的操作
process_item:爬虫获取到的每项item数据的处理方法
close_spider:爬虫运行结束时执行的操作
from_crawler:pipeline类方法,是创建item pipeline的回调方法,通常该方法用于读取setting中的配置参数。
其中process_item实现process_item(Item, Spider)固定方法,并return Item给后面的Pipeline处理或导出数据,但在处理中如果遇到错误,会抛弃该数据并停止传递。
1.启动管道前,需要配置。

2.管道py文件框架
import json
class ChoushibaikePipeline(object):
def __init__(self):
self.fp = open("duanzi.json","w",encoding='utf-8') # 管道类初始化,以w打开文件
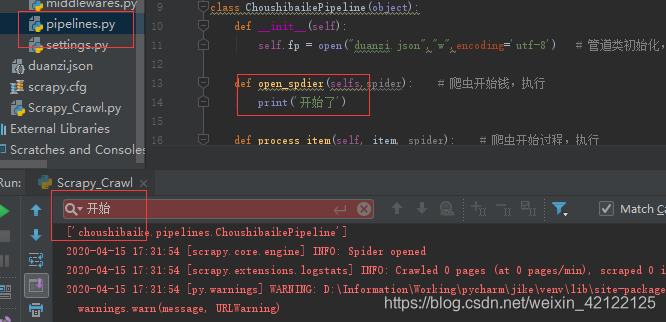
def open_spdier(selfs,spider): # 爬虫开始钱,执行
print('开始了')
def process_item(self, item, spider): # 爬虫开始过程,执行
item_json = json.dumps(item,ensure_ascii=False) # ensure_ascii=False:以中文字符保存
self.fp.write(item_json + '\n')
return item
def close_spider(self,spider): # 爬虫结束后,执行
self.fp.close()
print("over")

3.结果展示
4.问题
4.1open_spider()没有执行(命名写错了)
五、专业Item.py传参
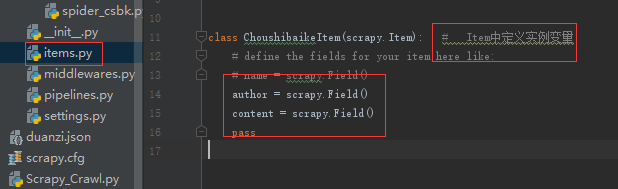
5.1Item中定义实例变量(author、content)
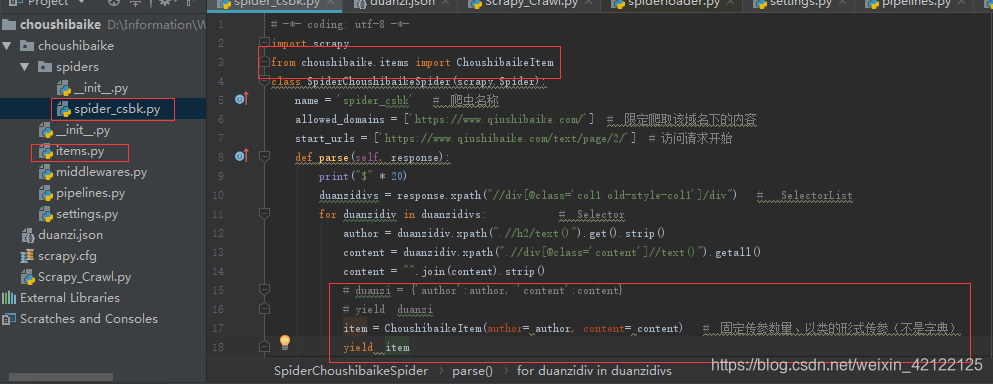
5.2在spider_csbk.py文件修改传参
5.3传参item类转化为字典

5.4item类传参的展示结果
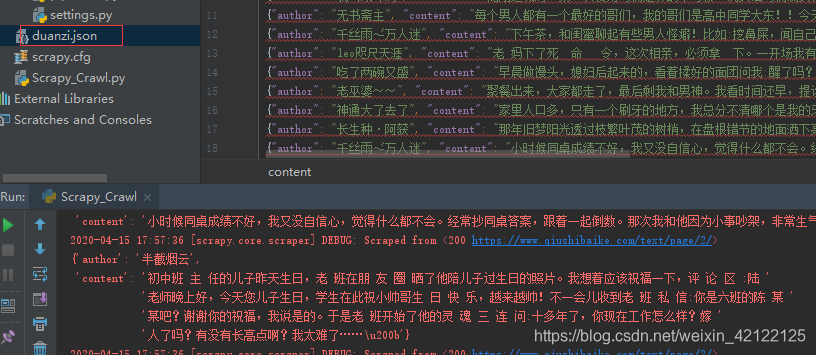
第二次发布:2020年4月15日















 213
213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









