






JAVA集合详解
之前没有具体的去了解集合(Collection、Map)。但是发现在代码优化时,有好多使用错误的问题,使用不恰当的集合样例。所以就想整理一下。
此文档参考了Java集合类使用场景梳理、史上最全的Java集合类解析
集合(两大分支)整体架构图
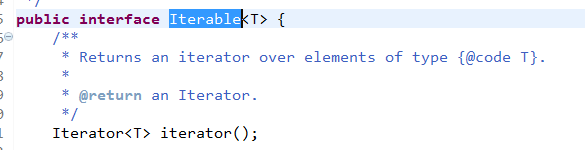
Iterable (Collection继承Iterable)
- Iterator:迭代器,它是Java集合的顶层接口(不包含Map系列接口)
- List还额外的提供了一个ListIterator对象,接口提供了一个listIterator()方法,该接口继承Iterable接口
- Iterator和Iterable区别
- Iterator是Iterable接口中的一个抽象方法 图解
- 所有实现Collection的接口子类都有可以进行迭代处理
Collection [Collection继承Iterator迭代器]
- List (有序,可重复的集合)
- ArrayList (底层结构是数组、查询快、增删慢,线程不安全、元素可为空。效率高)
- 长度达到饱和后,以50%的速度增长
- LinkedList (底层结构是链表、查询慢、增删快,线程不安全元素可为空。效率高)
- Vector(底层结构是数组、查询快、增删慢,线程安全。效率低。是已经被淘汰的集合)
- 长度达到饱和后,以100%的速度增长
- Stack (是Vector的一个子类。被淘汰的集合,可以不考虑,知道有这么一个集合就OK)
- ArrayList (底层结构是数组、查询快、增删慢,线程不安全、元素可为空。效率高)
- List (有序,可重复的集合)
ArrayList和LinkedList都是线程不安全的,所以效率比较高。如果想将一个线程
不安全的集合整合为线程安全。不推荐直接用线程安全集合,而是用Concurrent包下的类。
例如:
List<String> list = Collections.synchronizedList(new ArrayList<String>());
ArrayList和LinkedList 为什么一个查询快,一个查询慢。一个增删慢,一个增删快
数组就像身上编了号站成一排的人,要找第10个人很容易,根据人身上的编号很快就能找到。但插入、删除慢,要望某个位置插入或删除一个人时,后面的人身上的编号都要变。当然,加入或删除的人始终末尾的也快。
链表就像手牵着手站成一圈的人,要找第10个人不容易,必须从第一个人一个个数过去。但插入、删除快。插入时只要解开两个人的手,并重新牵上新加进来的人的手就可以。删除一样的道理。
-
Set
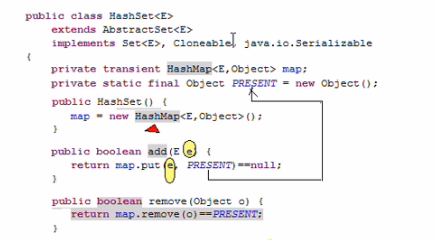
HashSet (线程不安全,不可重复的集合、无序、集合元素可为空)
- hashSet底层是一个Node对象数组,数组索引就是hash(value),数组值就是HashSet.add()的值
- 每一个存储到 哈希 表中的对象,都得提供 hashCode() 和 equals() 方法的实现,用来判断是否是同一个对象对于 HashSet 集合,我们要保证如果两个对象通过 equals() 方法返回 true,这两个对象的 hashCode 值也应该相同
- 当向HashSet集合中存入一个元素时,HashSet会先调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据hashCode值决定该对象在HashSet中的存储位置
- 如果 hashCode 值不同,直接把该元素存储到 hashCode() 指定的位置
- 如果 hashCode 值相同,那么会继续判断该元素和集合对象的 equals() 作比较
- hashCode 相同,equals 为 true,则视为同一个对象,不保存在 hashSet()中
- hashCode 相同,equals 为 false,则存储在之前对象同槽位的链表上,这非常麻烦,我们应该避免这种情况,即保证:如果两个对象通过 equals() 方法返回 true,这两个对象的 hashCode 值也应该相同
LinkedHashSet (线程不安全,不可重复的集合、有序、集合元素可为空)
- LinkedHashSetTest是HashSet的子类
- 因为底层采用 链表 和 哈希表的算法。链表保证元素的添加顺序,哈希表保证元素的唯一性
- LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet的性能,但在迭代访问Set里的全部元素时(遍历)将有很好的性能(链表很适合)
- 如果使用 TreeSet() 无参数的构造器创建一个 TreeSet 对象, 则要求放入其中的元素的类必须实现 Comparable 接口所以, 在其中不能放入 null 元素进行遍历)
EnumSet (线程不安全,不可重复的集合、有序)
- EnumSet是一个专门为枚举类设计的集合类,EnumSet中所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显式、或隐式地指定。EnumSet的集合元素也是有序的,它们以枚举值在Enum类内的定义顺序来决定集合元素的顺序
- TreeSet(线程不安全,不可重复的集合、有序,集合元素不可为空、底层采用红黑树算法,擅长区域查找)
- TreeSet在进行add操作时,必须放入同样类的对象
- 自动排序:创建自定义对象时。 必须实现Comparable接口,并且需要覆盖compareTo(Object obj) 方法来自定义比较规则。此时treeSet不能放入null的集合元素
- 如果 this > obj,返回正数 1
- 如果 this < obj,返回负数 -1
- 如果 this = obj,返回 0 ,则认为这两个对象相等
- 定制排序:创建 TreeSet 对象时, 传入 Comparator 接口的实现类. 要求: Comparator 接口的 compare 方法的返回值和 两个元素的 equals() 方法具有一致的返
treeSet有两种排序方式:自然排序、定制排序
首先说一下自然排序,自然排序需要调用集合元素的compareTo(Object obj)方法来比较元素的大小关系。自然排序时,treeSet添加元素不能为空
/**
* TreeSet存储的自定义对象,在自然排序是必须实现Comparable接口,
*且必须重写compareTo方法,其中compareTo方法返回的值,参考上边的解释。
*
*/
@Data
public class SetDto implements Comparable {
private int id;
private String name;
@Override
public int compareTo(Object o) {
return -1;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
SetDto setDto = (SetDto) o;
return id == setDto.id &&
Objects.equals(name, setDto.name);
}
}
/**
* 实现方法,如果是自动排序方式,在创建TreeSet时,需要构建无参的对象
*
*/
public static void main(String[] args) {
SetDto setDto = new SetDto();
setDto.setId(1);
setDto.setName("222");
SetDto setDto1 = new SetDto();
setDto1.setId(2);
setDto1.setName("111");
//自然排序创建无参的TreeSet时,sortSet.add添加元素时,不能为空
Set<SetDto> sortSet = new TreeSet<>();
sortSet.add(setDto);
sortSet.add(setDto1);
System.out.println(StringUtils.collectionToCommaDelimitedString(sortSet));
}
TreeSet定制排序时,需要实现Comparator接口,且必须重写compare方法,在防范重自定义排序规则。
实现方式有两种,首先第一种是在对象元素类中实现Comparator方式
public class TreeSetTest {
public static void main(String[] args) {
Person p1 = new Person(1);
Person p2 = new Person(2);
Person p3 = new Person(3);
//此方式的TreeSet不能添加为null的集合元素
Set<Person> set = new TreeSet<>(new Person());
set.add(p1);
set.add(p2);
set.add(p3);
System.out.println(set); //结果为[1, 2, 3]
}
}
class Person implements Comparator<Person>{
public int age;
public Person(){}
public Person(int age){
this.age = age;
}
@Override
/***
* 根据年龄大小进行排序
*/
public int compare(Person o1, Person o2) {
// TODO Auto-generated method stub
if(o1.age > o2.age){
return 1;
}else if(o1.age < o2.age){
return -1;
}else{
return 0;
}
}
@Override
public String toString() {
// TODO Auto-generated method stub
return ""+this.age;
}
}
第二种方式是在创建TreeSet时,传入一个有参的Comparator接口。
class M
{
int age;
public M(int age)
{
this.age = age;
}
public String toString()
{
return "M[age:" + age + "]";
}
}
public class TreeSetTest4
{
public static void main(String[] args)
{
TreeSet ts = new TreeSet(new Comparator()
{
//根据M对象的age属性来决定大小
public int compare(Object o1, Object o2)
{
M m1 = (M)o1;
M m2 = (M)o2;
return m1.age > m2.age ? -1
: m1.age < m2.age ? 1 : 0;
}
});
//此时,ts.add可以添加为空的结合元素。
ts.add(new M(5));
ts.add(new M(-3));
ts.add(new M(9));
System.out.println(ts);
}
}
-
- Queue (有序,元素不可为空)
- Queue用于模拟”队列”这种数据结构(先进先出 FIFO)。队列的头部保存着队列中存放时间最长的元素,队列的尾部保存着队列中存放时间最短的元素。新元素插入(offer)到队列的尾部。
- 访问元素(poll)操作会返回队列头部的元素,队列不允许随机访问队列中的元素。结合生活中常见的排队就会很好理解这个概念
- PriorityQueue
- PriorityQueue并不是一个比较标准的队列实现,PriorityQueue保存队列元素的顺序并不是按照加入队列的顺序,而是按照队列元素的大小进行重新排序,这点从它的类名也可以看出来。
- PriorityQueue也有两种排序方式,和TreeSet类似。一个自然排序,一个定制排序。
- Deque
- Deque接口代表一个“双端队列”,双端队列可以同时从两端来添加、删除元素,因此Deque的实现类既可以当成队列使用、也可以当成栈使用
- ArrayDeque
- 是一个基于数组的双端队列,和ArrayList类似,它们的底层都采用一个动态的、可重分配的Object[]数组来存储集合元素,当集合元素超出该数组的容量时,系统会在底层重新分配一个Object[]数组来存储集合元素
LinkedList
- linkedList是Deque的一个成员类也是List的成员类。他有Deque和List都有的特性。
Queue代表队列,Deque代表了双端队列(既可以作为队列使用、也可以作为栈使用)
PriorityQueue集合使用
import java.util.*;
public class PriorityQueueTest
{
public static void main(String[] args)
{
PriorityQueue pq = new PriorityQueue();
//下面代码依次向pq中加入四个元素
pq.offer(6);
pq.offer(-3);
pq.offer(9);
pq.offer(0);
//输出pq队列,并不是按元素的加入顺序排列,
//而是按元素的大小顺序排列,输出[-3, 0, 9, 6]
System.out.println(pq);
//访问队列第一个元素,其实就是队列中最小的元素:-3
System.out.println(pq.poll());
}
}
Deque使用规则
import java.util.*;
public class ArrayDequeTest
{
public static void main(String[] args)
{
ArrayDeque stack = new ArrayDeque();
//依次将三个元素push入"栈"
stack.push("疯狂Java讲义");
stack.push("轻量级Java EE企业应用实战");
stack.push("疯狂Android讲义");
//输出:[疯狂Java讲义, 轻量级Java EE企业应用实战 , 疯狂Android讲义]
System.out.println(stack);
//访问第一个元素,但并不将其pop出"栈",输出:疯狂Android讲义
System.out.println(stack.peek());
//依然输出:[疯狂Java讲义, 轻量级Java EE企业应用实战 , 疯狂Android讲义]
System.out.println(stack);
//pop出第一个元素,输出:疯狂Android讲义
System.out.println(stack.pop());
//输出:[疯狂Java讲义, 轻量级Java EE企业应用实战]
System.out.println(stack);
}
}- Map (Key不允许重复,Value可以重复)
- Map中的Key不许重复,即同一个Map对象的任何两个key通过equals方法进行比较,关于Map,从源码角度理解,java先实现Map,然后通过包装了一个所有value为null的map就实现了Set集合【因为Set不许重复也是通过equals来比较的】
- Map的这些实现类和子接口中key集的存储形式和Set集合完全相同(即key不能重复)
- Map的这些实现类和子接口中value集的存储形式和List非常类似(即value可以重复、根据索引来查找)
Map子类
- HashMap(Key不允许重复,Value可以重复、线程不安全)
- 采用Hash算法存储key
- 不保证添加时的先后顺序,
- 判断重复标准是:key1和key2是否equals为true,并且hashCode相等
- 和HashSet类似
- LinkedHashMap (Key不允许重复,Value可以重复、线程不安全)
- 采用链表和Hash算法存储key
- 保证添加时的先后顺序
- 判断重复标准是:key1和key2是否equals为true,并且hashCode相等
- HashTable(Key不允许重复,Value可以重复、线程安全)
- 是HashMap的前身,目前已经作废。以为新能太差。知道有这么一个类就OK啦
- TreeMap(Key不允许重复,Value可以重复、线程不安全)
- 采用红黑树算法来确定元素存储位置
- Map中的key会按照自然顺序或者特定顺序排列
- key不允许重复的标准是compareTo、compare方法返回值是否为0
- 实现方式和TreeSet类似
- WeakHashMap(Key不允许重复,Value可以重复、线程不安全)
- WeakHashMap与HashMap用法基本相似,区别在于,HashMap的key保留了对实际对象的“强引用”。
- HashMap对象不销毁,该HashMap所引用对象就不会被销毁
- WeakHashMap的key保留了对实际对象的“弱引用”
- WeakHashMap对象的key所引用的对象没有被其他强引用变量引用,则这些key所引用的对象就会被垃圾回收,回收后WeakHashMap也会把当前key-value对删除
- IdentityHashMap(Key不允许重复,Value可以重复、线程不安全)
- IdentityHashMap的实现机制与HashMap基本相似,在IdentityHashMap中,当且仅当两个key严格相等(key1 == key2)时,IdentityHashMap才认为两个key相等
- EnumMap(Key不允许重复,Value可以重复、线程不安全)
- EnumMap是一个与枚举类一起使用的Map实现,EnumMap中的所有key都必须是单个枚举类的枚举值。创建EnumMap时必须显式或隐式指定它对应的枚举类。EnumMap根据key的自然顺序
- HashMap(Key不允许重复,Value可以重复、线程不安全)
Map和Set关系
- HashMap和HashSet都采用哈希表算法
- TreeMap和TreeSet都采用 红黑树算法
- LinkedHashMap和LinkedHashSet都采用哈希表算法和红黑树算法
- Set底层实现就是一个key不重复且value为null的Map 源码















 419
419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}