







题目:
输入一个复杂链表(每个节点中有节点值,以及两个指针,一个指向下一个节点,另一个特殊指针指向任意一个节点),返回结果为复制后复杂链表的head。(注意,输出结果中请不要返回参数中的节点引用,否则判题程序会直接返回空)
struct RandomListNode {
int label;
struct RandomListNode *next, *random;
RandomListNode(int x) :
label(x), next(NULL), random(NULL) {
}
};
解题思路
大部分人首先想到的可能是先复制复杂指针的label和next,然后再查找random并更新。查找random又分为两种,一种是每次都从头查找,时间复杂度为O(n^2);另一种是空间换时间,复制label和next的同时建立一个hash表来存放新旧复杂指针的对应关系,所以后续只需一步就能找到random,算法时间复杂度为O(n)。
我们这里将复杂链表的复制过程分解为三个步骤。在写代码的时候我们每一步定义一个函数,这样每个函数完成一个功能,整个过程的逻辑也就非常清晰明了了。
我们这里采用三步:
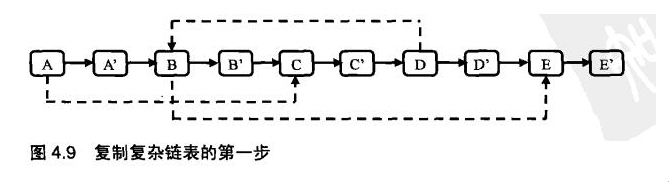
第一步:复制复杂指针的label和next。但是这次我们把复制的结点跟在元结点后面,而不是直接创建新的链表;
第二步:设置复制出来的结点的random。因为新旧结点是前后对应关系,所以也是一步就能找到random;
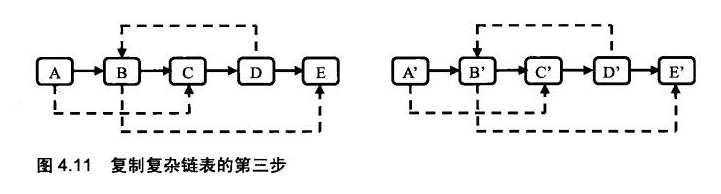
第三步:拆分链表。奇数是原链表,偶数是复制的链表。
有图思路更清晰:

C++实现
class Solution {
public:
//第一步,复制复杂指针的label和next
void CloneNodes(RandomListNode* pHead){
RandomListNode* pNode = pHead;
while(pNode != NULL){
RandomListNode* pCloned = new RandomListNode(0);
pCloned->label = pNode->label;
pCloned->next = pNode->next;
pCloned->random = NULL;
pNode->next = pCloned;
pNode = pCloned->next;
}
}
//第二步,处理复杂指针的random
void ConnectSiblingNodes(RandomListNode* pHead){
RandomListNode* pNode = pHead;
while(pNode != NULL){
RandomListNode* pCloned = pNode->next;
if(pNode->random != NULL){
pCloned->random = pNode->random->next;
}
pNode = pCloned->next;
}
}
//第三步,拆分复杂指针
RandomListNode* ReconnectNodes(RandomListNode* pHead){
RandomListNode* pNode = pHead;
RandomListNode* pClonedHead = NULL;
RandomListNode* pClonedNode = NULL;
if(pNode != NULL){
pClonedHead = pClonedNode = pNode->next;
pNode->next = pClonedNode->next;
pNode = pNode->next;
}
while(pNode != NULL){
pClonedNode->next = pNode->next;
pClonedNode = pClonedNode->next;
pNode->next = pClonedNode->next;
pNode = pNode->next;
}
return pClonedHead;
}
RandomListNode* Clone(RandomListNode* pHead)
{
CloneNodes(pHead);
ConnectSiblingNodes(pHead);
return ReconnectNodes(pHead);
}
};
测试用例
- 功能测试(节点中的random指向节点自身;两个节点的m_pSibiling形成环状结构;链表中只有一个节点)
- 特殊输入测试(指向链表头节点的指针为nullptr指针)















 398
398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









