









 这篇博客介绍了在多分类任务中常用的评价指标,包括宏平均、微平均和加权平均方法。宏平均对每个类别的指标取平均,平等对待所有类别;微平均则是对所有样本统一计算,更关注总体表现;加权平均根据类别样本数调整权重。选择合适的平均方式取决于是否重视稀有类别。
这篇博客介绍了在多分类任务中常用的评价指标,包括宏平均、微平均和加权平均方法。宏平均对每个类别的指标取平均,平等对待所有类别;微平均则是对所有样本统一计算,更关注总体表现;加权平均根据类别样本数调整权重。选择合适的平均方式取决于是否重视稀有类别。
做CRF的时候会碰到多分类下的评价指标,记录一下
二分类的情况下可以参考二分类评价标准
以一个三分类举例
三分类的混淆矩阵如下
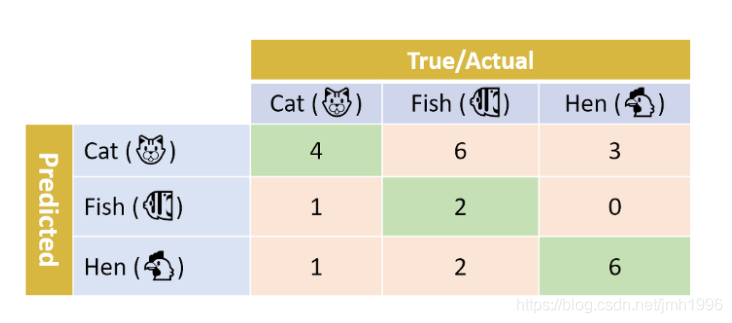
- 对于猫来说
recall(猫) = 4/6 = 0.66
precision(猫) = 4/(4+6+3) = 0.3076 - 对于鱼来说
recall(鱼) = 2/10= 0.2
precision(鱼) = 2/3 = 0.66 - 对于鸡来说
recall(鸡) = 6/9 = 0.66
precision(鸡) = 6/9 = 0.66
Macro-average 宏平均
该方法最简单,直接将不同类别的评估指标(Precision/ Recall/ F1-score)加起来求平均,给所有类别相同的权重。该方法能够平等看待每个类别,但是它的值会受稀有类别影响,会更加关注类别少的样本。
- recall
recal = (recall(猫) +recall(鱼) +recall(鸡) )/3 = (0.66+0.2+0.66)/3 - precision
precision= (precision(猫) +precision(鱼) +precision(鸡) )/3 = (0.3076+0.66+0.66)/3
Micro-average 微平均
该方法把每个类别的TP, FP, FN先相加之后,在根据二分类的公式进行计算。(分子是分子之和 分母是分母之和)
- recall
recall = (4+2+6)/(6+10+9) = 0.48 - precision
precision = (4+2+6)/(4+6+3+3+9) = 0.48
Micro-average下,多分类的accuracy,recall和precision会相同,这不是个例 。
Weighted 加权平均
- 计算比例
猫 = (6)/(6+10+9) = 0.24
鱼 = (10)/(6+10+9)= 0.4
鸡 = (9)/(6+10+9) = 0.36 - recall
0.660.24+0.20.4+0.66*0.36 = 0.476 - precision
0.30760.24+0.660.4+0.66*0.36 = 0.5754
结论
- 如果看重样本数量多的class,推荐微平均
- 如果看重样本数量少的class,推荐宏平均
- 如果微平均 远 低于宏平均,需要注意样本量多的class
- 如果微平均 远 gao 宏平均,需要注意样本量少的class

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









