







目录
1 概述
假设有因变量Y,一组自变量X,那么要分析X与Y的相关关系,如何用一组自变量X去解释因变量Y,就可以用到回归分析。
1.1 使用目的
找出那些变量X与Y真的相关,哪些无关。去除不相关的X后,对X进行正负关系的判断,赋予X不同的权重(系数)。
1.2 类型
| 类型 | 模型 | Y | 举例 |
| 线性回归 | 最小二乘法 | 连续值变量 | GDP、产量 |
| 逻辑回归 | 逻辑回归 | 0-1变量 | 是否生病 |
| 定序回归 | 泊松回归 | 计数变量 | 每分钟的车流量 |
| 生存回归 | cox等比例分享回归 | 生存变量 | 寿命 |
、回归模型的类型
| 数据 | 类型 |
| 横截面数据 | 某一时间点收集到的不同对象的数据 |
| 时间序列数据 | 同一对象在不同时间点观察到的数据 |
| 面板数据 | 综合横截面与时间序列的数据 |
数据的类型
2 线性回归
2.1 一元线性函数拟合
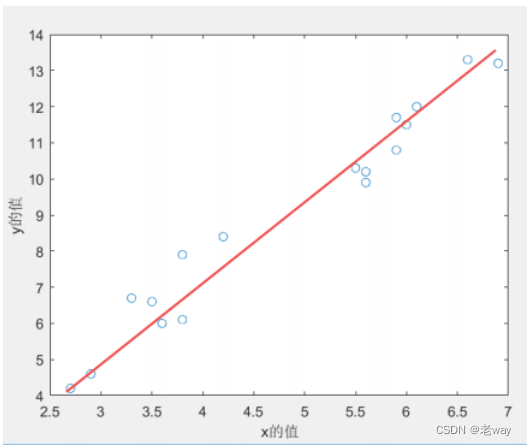
假设自变量X只有一个,那么拟合曲线可以设为,一元线性回归的目的就是求:
k和b取何值时,样本点和曲线的结果最为接近?
我们可以用最小二乘法,设样本点,
,设拟合的曲线为
,
令拟合值 ,那么
令 ,通过求导的方式找到k和b,使得残差平方和 L 最小。
2.2 一元线性回归模型
假设x是自变量,y是因变量,且满足如下线性关系:
其中为线性回归系数,
为无法观测的满足一定条件的扰动项。
令预测值
其中
我们称 为残差
注意:线性假定并不要求初始模型都呈上述的严格线性关系,自变量与因变量可通过变量替换而转化成线性模型。
2.3 解释回归系数
假设x为某产品品质评分(1-10之间),y为该产品的销量,我们对x和y使用一元线性回归模型,如果得到,如何解释我们估计出来的回归系数?
- 3.4:在评分为0时,该产品的平均销量为3.4
- 2.3:评分每增加一个单位,该产品的平均销量增加2.3
如果现在有两个自变量,表示品质评分,
表示该产品的价格,那么我们可建立多元线性回归模型:
,如果估计出来的回归等式为:
- 5.3:在评分为0且价格为0时,该产品的平均销量为5.3个(没现实意义)
- 0.19:在保持其他变量不变的情况下,评分每增加一个单位,该产品的平均销量增加0.19
- 1.74:在保持其他变量不变的情况下,价格每增加一个单位,该产品的平均销量减少1.74
可以看到,引入了新的自变量价格后,对回归系数的影响非常大! ! ! 原因:遗漏变量导致的内生性
2.4 内生性的探究
假设我们的模型为:
为无法观测的且满足一定条件的扰动项,如果满足误差项u和所有的自变量x均不相关,则称该回归模型具有外生性,如果相关,则存在内生性,内生性会导致回归系数估计的不准确,不满足无偏和一致性。
无内生性 (no endogeneity) 要求所有解释变量均与扰动项不相关。这个假定通常太强,因为实际情况下解释变量一般很复杂 (比如,因为左脚先踏入办公室导致被裁员)
是否可能弱化此条件?答案是肯定的,如果你的解释变量可以区分为核心解释变量与控制变量两类。
- 核心解释变量: 我们最感兴趣的变量,因此我们特别希望得到对其系数的一致估计 (当样本容量无限增大时,收敛于待估计参数的真值)
- 控制变量: 我们可能对于这些变量本身并无太大兴趣;而之所以把它们也放入回归方程,主要是为了“控制住”那些对被解释变量有影响的遗漏因素。
在实际应用中,我们只要保证核心解释变量与不相关即可。
3 数据处理
3.1 虚拟变量
对定类的变量,我们通常要转化为定量的形式才能进行回归分析。处理方式有哑变量、独热编码。
例如职业因素,假设分为学生、农民、工人、公务员、其他共5个分类,其中以“其他职业”作为参照,此时需要设定4哑变量X1-X4,如下所示:
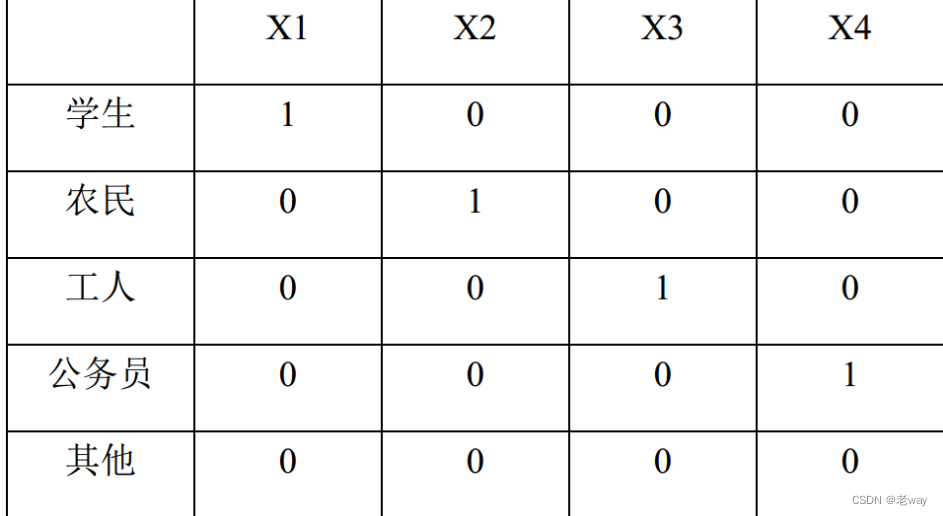
对于有n个分类的自变量,需要产生n-1个哑变量,当所有n-1个哑变量取值都为0的时候,这就是该变量的第n类属性,即我们将这类属性作为参照,避免多重共线性的影响。
4. 实战例题
现有某电商平台846条关于婴幼儿奶粉的销售信息,每条信息由11个指标组成。其中,评价量可以从一个侧面反映顾客对产品的关注度。请对所给数据进行以下方面的分析,要求最终的分析将不仅仅有益于商家,更有益于宝妈们为宝贝选择适合自己的奶粉。
- 以评价量为因变量,分析其它变量和评价量之间的关系
- 以评价量为因变量,研究影响评价量的重要因素。
| 商品名称 | 商品毛重.kg. | 奶源产地 | 国产或进口 | 适用年龄.岁. | 包装单位 | 配方 | 分类 | 段位 | 团购价.元. | 评价量 |
| 美素 | 1.11 | 荷兰 | 进口 | 1-3岁 | 桶装 | 常规配方奶粉 | 牛奶粉 | 3段 | 9.9 | 683009 |
| 美素 | 1.35 | 荷兰 | 进口 | 1-3岁 | 盒装 | 常规配方奶粉 | 牛奶粉 | 3段 | 9.9 | 683009 |
| 惠氏 | 1.13 | 爱尔兰 | 进口 | 1-3岁 | 桶装 | 常规配方奶粉 | 牛奶粉 | 3段 | 30 | 605775 |
| 美素 | 1.12 | 荷兰 | 进口 | 0.5-1岁 | 桶装 | 常规配方奶粉 | 牛奶粉 | 2段 | 28 | 605775 |
| 诺优能 | 0.88 | 荷兰 | 进口 | 3-6岁 | 桶装 | 常规配方奶粉 | 牛奶粉 | 4段 | 25.8 | 605775 |
| 惠氏 | 1.16 | 澳洲/新西兰 | 国产 | 1-3岁 | 桶装 | 常规配方奶粉 | 牛奶粉 | 3段 | 19.9 | 605775 |
| 美赞臣 | 1.03 | 荷兰 | 进口 | 1-3岁 | 桶装 | 常规配方奶粉 | 牛奶粉 | 3段 | 15 | 605775 |
| 雅培 | 1.11 | 中国大陆 | 国产 | 1-3岁 | 桶装 | 常规配方奶粉 | 牛奶粉 | 3段 | 36 | 401183 |
| 惠氏 | 1.13 | 爱尔兰 | 进口 | 0.5-1岁 | 桶装 | 常规配方奶粉 | 牛奶粉 | 1段 | 36 | 401183 |
| 惠氏 | 1.41 | 澳洲/新西兰 | 国产 | 1-3岁 | 盒装 | 常规配方奶粉 | 牛奶粉 | 3段 | 40 | 378557 |
| 雅培 | 1.38 | 中国大陆 | 国产 | 1-3岁 | 盒装 | 常规配方奶粉 | 牛奶粉 | 3段 | 43 | 348286 |
| 诺优能 | 0.98 | 荷兰 | 进口 | 0-0.5岁 | 桶装 | 常规配方奶粉 | 牛奶粉 | 1段 | 43 | 348286 |
| 惠氏 | 3.73 | 澳洲/新西兰 | 国产 | 1-3岁 | 盒装 | 常规配方奶粉 | 牛奶粉 | 3段 | 43.5 | 340457 |
....
4.1 描述性统计
| 变量名 | 样本量 | 最大值 | 最小值 | 平均值 | 标准差 | 中位数 | 方差 | 峰度 | 偏度 | 变异系数(CV) |
|---|---|---|---|---|---|---|---|---|---|---|
| 商品毛重.kg. | 846 | 8.64 | 0.12 | 1.051 | 0.761 | 1 | 0.58 | 37.175 | 5.389 | 0.725 |
| 评价量 | 846 | 683009 | 1 | 15.258 | 72.533 | 330.5 | 530.147 | 46.249 | 6.506 | 4.612 |
| 团购价.元. | 846 | 2598 | 9.9 | 366.894 | 377.091 | 254 | 142.925 | 8.666 | 2.732 | 1.028 |
总体描述性结果
4.2 虚拟变量处理
注意 回归分析中的变量不用进行归一化预处理,否则量纲变化后很难描述性解释
4.3 进行回归分析
分析步骤
- 通过分析F值,分析其是否可以显著地拒绝总体回归系数为0的原假设(P<0.05),若呈显著性,表明之间存在着线性关系,至于线性关系的强弱,需要进一步进行分析。
- 通过R²值分析模型拟合情况,同时对VIF值进行分析,若模型呈现共线性(VIF大于10或者5,严格为10),建议使用岭回归或者逐步回归。
- 分析X的显著性;如果呈现出显著性(P<0.05),则用于探究X对Y的影响关系。
- 结合回归系数B值,对比分析X对Y的影响程度。
- 确定得到模型公式(Tips:使用线性回归前可以通过统计类的方法例如正态性检验等方式对数据进行验证清洗,也可以采用数据处理中异常值处理等方法对数据进行清洗。)
计算结果
| 线性回归分析结果 n=846 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 非标准化系数 | 标准化系数 | t | P | VIF | R² | 调整R² | F | ||
| B | 标准误 | Beta | |||||||
| 常数 | 64931.43 | 9380.609 | - | 6.922 | 0.000*** | - | 0.092 | 0.07 | F=4.163 P=0.000*** |
| C_适用年龄.岁._2 | 10785.507 | 25495.145 | 0.064 | 0.423 | 0.672 | 20.572 | |||
| C_适用年龄.岁._4 | -15756.819 | 21467.539 | -0.086 | -0.734 | 0.463 | 12.56 | |||
| C_适用年龄.岁._5 | 35562.425 | 71144.92 | 0.024 | 0.5 | 0.617 | 2.044 | |||
| B_国产或进口_2 | -11543.078 | 6514.133 | -0.075 | -1.772 | 0.077* | 1.637 | |||
| C_适用年龄.岁._3 | 49588.857 | 50931.163 | 0.191 | 0.974 | 0.331 | 35.024 | |||
| E_段位_4 | 11254.553 | 21573.506 | 0.061 | 0.522 | 0.602 | 12.34 | |||
| D_配方_2 | -14179.145 | 11492.528 | -0.021 | -1.234 | 0.218 | - | |||
| 商品毛重.kg. | 173.353 | 3265.721 | 0.002 | 0.053 | 0.958 | 1.057 | |||
| D_配方_3 | -11334.304 | 8165.029 | -0.026 | -1.388 | 0.165 | - | |||
| G_配方_2 | -14179.145 | 11492.528 | -0.021 | -1.234 | 0.218 | - | |||
| E_段位_3 | -39013.694 | 50884.374 | -0.152 | -0.767 | 0.443 | 35.824 | |||
| E_段位_2 | -13639.307 | 25466.429 | -0.08 | -0.536 | 0.592 | 20.255 | |||
| 团购价.元. | -31.206 | 6.581 | -0.161 | -4.742 | 0.000*** | 1.053 | |||
| F_奶源产地_9 | -50409.504 | 41335.358 | -0.041 | -1.22 | 0.223 | 1.034 | |||
| F_奶源产地_8 | -45303.052 | 13990.161 | -0.129 | -3.238 | 0.001*** | 1.438 | |||
| G_配方_3 | -11334.304 | 8165.029 | -0.026 | -1.388 | 0.165 | - | |||
| F_奶源产地_3 | -22285.129 | 10251.532 | -0.104 | -2.174 | 0.030** | 2.083 | |||
| F_奶源产地_7 | -29544.097 | 50345.559 | -0.02 | -0.587 | 0.557 | 1.024 | |||
| F_奶源产地_6 | -41077.938 | 8676.058 | -0.271 | -4.735 | 0.000*** | 2.972 | |||
| F_奶源产地_4 | -30253.256 | 9745.963 | -0.185 | -3.104 | 0.002*** | 3.229 | |||
| F_奶源产地_2 | 4685.207 | 14519.009 | 0.012 | 0.323 | 0.747 | 1.314 | |||
| F_奶源产地_5 | -13386.455 | 16493.195 | -0.033 | -0.812 | 0.417 | 1.491 | |||
| 因变量:评价量 | |||||||||
| 注:***、**、*分别代表1%、5%、10%的显著性水平 | |||||||||
线性回归模型要求总体回归系数不为0,即变量之间存在回归关系。首先根据F检验结果对模型进行检验。
联合显著性检验:F=4.163,P=0.000,水平上呈现显著性,拒绝回归系数为0的原假设,因此模型基本满足要求。
拟合优度较低怎么办:
(1) 回归分为解释型回归和预测型回归。预测型回归一般才会更看重R2解释型回归更多的关注模型整体显著性以及自变量的统计显著性和经济意义显著性即可。
(2) 可以对模型进行调整,例如对数据取对数或者亚方后再进行回归。
(3) 数据中可能有存在异常值或者数据的分布极度不均匀。
标准回归化系数:
对数据进行标准化,就是将原始数据减去它的均数后,再除以该变量的标准差,计算得到新的变量值,新变量构成的回归方程称为标准化回归方程,回归后相应可得到标准化回归系数。标准化系数的绝对值越大,说明对因变量的影响就越大 (只关注显薯的回归系数)
多重共线性的影响:
方差膨胀因子 VIF的计算方式:
其中 是将第m个变量作为因变量,对剩下k-1个自变量回归得到的拟合度。
越大,说明第m个变量和其他的变量相关性越大,假如某变量的VIF>10,说明该回归方程存在严重的多重共线性。
多重共线性处理方法:
如果发现存在多重共线性,可以采取以下处理方法。
(1)如果不关心具体的回归系数,而只关心整个方程预测被解释变量的能力,则通常可以 不必理会多重共线性(假设你的整个方程是显著的)。这是因为,多重共线性的主要后果是使得对单个变量的贡献估计不准,但所有变量的整体效应仍可以较准确地估计。
(2)如果关心具体的回归系数,但多重共线性并不影响所关心变量的显著性,那么也可以不必理会。即使在有方差膨胀的情况下,这些系数依然显著;如果没有多重共线性,则只会更加显著。
(3) 如果多重共线性影响到所关心变量的显著性,则需要增大样本容量,剔除导致严重共线性的变量(不要轻易删除哦,因为可能会有内生性的影响),或对模型设定进行修改。
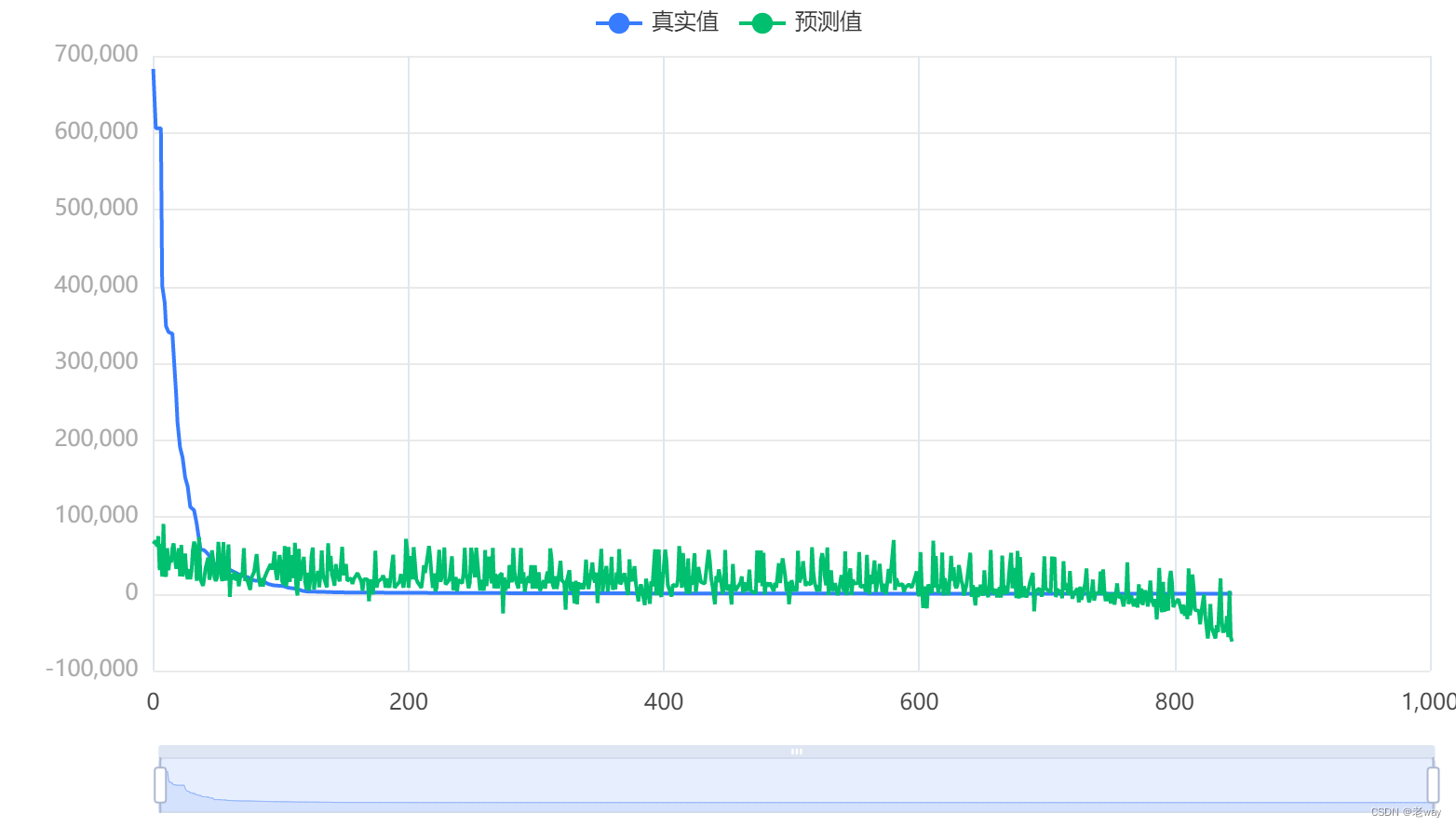
拟合效果图















 2700
2700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









