








回归分析是指的是建立两个或两个以上变量间相互依赖量化关系的一种统计分析方法。 回归分析是一种预测性的建模技术, 它研究的是因变量(结果)和自变量(原因)之间的数量化关系。 回归分析按照涉及的变量的多少,分为一元回归和多元回归分析; 按照因变量的多少,可分为简单回归分析和多重回归分析。 按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。 1.分析目的线性回归通常是在学习预测模型时首选的技术之一。在这种技术中, 因变量是连续的, 自变量可以是连续的也可以是离散的, 回归线的性质是线性的。 线性回归寻求最佳的拟合直线(也就是回归线)在因变量(Y)与一个或多个自变量(X)之间建立一种关系。 2.主要解决的问题:1、确定变量之间是否存在相关关系, 若存在, 则找出数学表达式; 2、进行预测或控制, 且估计这种预测或控制的精度。 步骤如下: 1、根据自变量与因变量的现有数据以及关系, 设定回归模型; 2、求出合理的回归系数; 3、进行检验, 残差分析, 共线性诊断等; 4、在符合要求后, 即可根据已得的回归方程进行预测, 并计算预测值的置信区间等。 |
|
| 一个因变量与多个解释变量之间的相关关系是线性的回归模型。 假设多项式: |
![]()
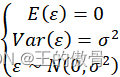
| 其中ε |
![]()
参数估计、假设检验、预测。
对于多项式里β 是未知的,所以使 |
|
达到最小
|
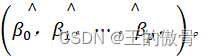
| 通过解方程组: |
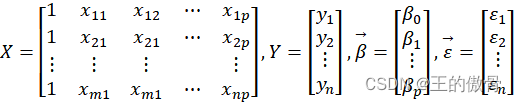
| 得到: 参数 |
对模型的回归系数评估依据偏差平方和进行分解
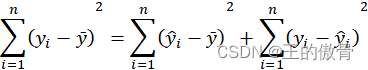
| 总平方和(SST)=回归平方和(SSR)+残差平方和(SSRes) 可以得到Y的估计多项式: 把s的值代入得到 |
决定系数(判定系数法) |

|
|
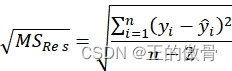
| 1、反映实际观察值在回归直线周围的分散状况; 2、说明了回归直线的拟合程度 (衡量回归方程的代表性, 测定回归估计的精度)。越大表示回归效果差,越小表示回归效果好。 |
|
![]()
![]()
| 原假设表示所有的自变量对因变量都没有线性预测效果,备择假设有至少有一个预测效果。 |

| 当 |
|
| 检验每个自变量与y之间的线性关系是否显著 H0:βj=0
原假设表示自变量与因变量之间没有线性关系,检验统计量服从t分布。 |
|
| 残差: 1、度量了数据和拟合值间的偏离 2、反映了反映变量中不能由回归模型解释的部分 3、残差分析就是通过残差所提供的信息, 分析模型的假定正确与否的方法。 目的:检验模型的正态性假设,例P-P图,Q-Q图。 |
|
| 1、 2、
|
|
1、为全面反映中国人口出生率,选择 “人口自然增长 率" 作为因变量, 以反映中国人口的增长; 选择 “国名收入" 及 “人均GDP” 作为经济增长的代表; 选择 “居民消费价格指数增长率” 作为居民消费水 平的代表。暂不考虑文化程度及人口分布的影响。
1. clear;clc
2. data = xlsread('工2.19.xlsx','B3:E20');
3. n =length(data);
4. x = data(:,2:4);
5. y = data(:,1);
6. X = [ones(n,1),x];
7. [b,bint,r,rint,stats] = regress(y,X);
8. b,bint,stats,
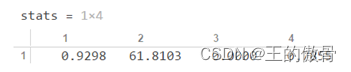
| 通过观察stats数据可以得出至少有一个变量和y之间的关系是显著的。通过 |

| 观察bint数据得到x2的数据的p值大于0.05,说明x2与y的关系不显著,我们把它在模型中剔除x2。 相应的程序部分也要改变,得到的数据如下: |
1. b = 3×1
2. 15.9372
3. 0.0003
4. -0.0053
5. bint = 3×2
6. 14.3429 17.5316
7. 0.0001 0.0006
8. -0.0085 -0.0022
9. stats = 1×4
10. 0.9228 89.6344 0.0000 0.8064
| 结论:x1,x3与y的关系都显著 得到最终的回归多项式: 例2 某科学基金会希望估计从事某研究学者的年薪y与研究成果的质量指标,从事研究工作时间、能成功获得资助的指标之间的关系。 |
1. clear;clc
2. data = xlsread('工2.20.xlsx','A2:D25');
3. n = length(data);
4. y = data(:,1);
5. x1 = data(:,2);
6. x2 = data(:,3);
7. x3 = data(:,4);
8. subplot(1,3,1);plot(x1,y,'*');
9. title('y与x1的散点图');
10. subplot(1,3,2);plot(x2,y,'+');
11. title('y与x2的散点图');
12. subplot(1,3,3);plot(x3,y,'o');
13. title('y与x3的散点图')
14. A = [x1,x2,x3];
15. a = ones(24,1);
16. X = [a,A];
17. [b,bint,r,rint,stats] = regress(y,X);
18. subplot(1,1,1);
19. rcoplot(r,rint);

| 运行后得到以下数据: |
1. b = 4×1
2. 16.7948
3. 1.2004
4. 0.3207
5. 1.3933
6.
7. bint = 4×2
8. 12.5350 21.0546
9. 0.5240 1.8768
10. 0.2433 0.3981
11. 0.7708 2.0159
12.
13. stats = 1×4
14. 0.9106 67.9028 0.0000 3.0726
| 观察数据得到回归系数b=(16.7948,1.2004,0.3207,1.3933)及其置信区间,且置信区间不包括原点和统计变量stats,包括四个检验统计量:相关系数的平方R2 (0.9106,67.9028,0,3.0726)。 利用检验统计量R,F,p的值判断模型是否可用,本例R的绝对值为0.9106,表明线性相关性强,F=67.9028>F(3,20)=3.10000,p=0.0000,显然满足p<0.05,三种统计推断的结果是一致的,说明因变量y与各自变量之间显著地有线性相关关系,所得的线性回归模型可用。 最后以观测值序号为横坐标,残差为纵坐标所得到的散点图称为时序残差图,得到下面此图。 |
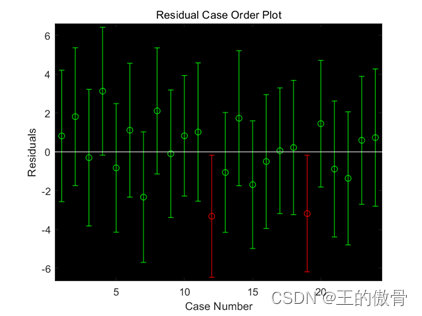
| 结论:得到的回归方程为: |
|
|
| 1、首先将全部p个回归变量, 分别对响应变量y建立p个一元线性回归方程, 并分别计算这p个一元线性回归方程的p个回归系数的F检验值, 设其最大值为F,若 2、y分别与 3、将所对应的回归变量引入回归方程。设引入的回归变是为 4、依上述方法接着做下去,直至没有引入也没有删除的回归变量为止。这时得到的回归方程就是最终确定的方程。 |
















 1888
1888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











