







一.前言
1.1.何为内存对齐
现代计算机中内存空间都是按照字节(byte)进行划分的,所以从理论上讲对于任何类型的变量访问都可以从任意地址开始,但是在实际情况中,在访问特定类型变量的时候经常在特定的内存地址访问,所以这就需要把各种类型数据按照一定的规则在空间上排列,而不是按照顺序一个接一个的排放,这种就称为内存对齐,内存对齐是指首地址对齐,而不是说每个变量大小对齐。
1.2.为何要有内存对齐
1.平台原因:不是所有的硬件平台都能够访问任意地址上的任意数据。
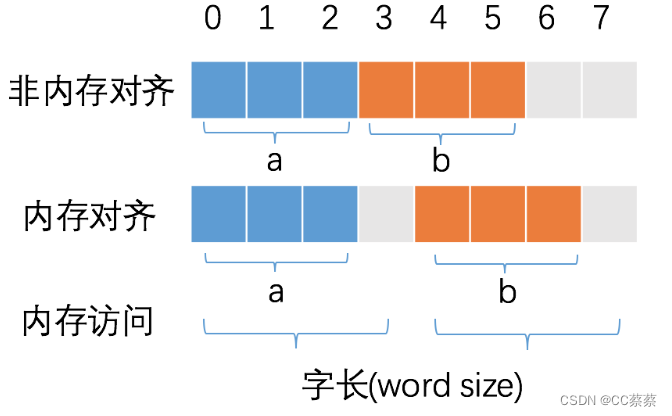
2.性能原因:操作系统并非一个字节一个字节访问内存,而是按2, 4, 8这样的字长来访问。因此,当CPU从存储器读数据到寄存器,或者从寄存器写数据到存储器,IO的数据长度通常是字长。
3.CPU每次寻址都是要消费时间的,并且CPU 访问内存时,并不是逐个字节访问,而是以字长(word size)为单位访问,所以数据结构应该尽可能地在自然边界上对齐**,如果访问未对齐的内存,处理器需要做两次内存访问,然后拼接字节流;而对齐的内存访问仅需要一次访问,内存对齐后可以提升性能**。
二.数据类型
2.1.go类型字节大小
package main
import (
"fmt"
"unsafe"
)
func method1() {
fmt.Println("bool", unsafe.Sizeof(bool(true))) // 1
fmt.Println("int8", unsafe.Sizeof(int8(1))) // 1
fmt.Println("int16", unsafe.Sizeof(int16(1))) // 2
fmt.Println("int32", unsafe.Sizeof(int32(1))) // 4
fmt.Println("int64", unsafe.Sizeof(int64(1))) // 8
fmt.Println("int", unsafe.Sizeof(int(1))) // 8
fmt.Println("---------------------------")
fmt.Println("uint8", unsafe.Sizeof(uint8(1))) // 1
fmt.Println("uint16", unsafe.Sizeof(uint16(1))) // 2
fmt.Println("uint32", unsafe.Sizeof(uint32(1))) // 4
fmt.Println("uint64", unsafe.Sizeof(uint64(1))) // 8
fmt.Println("uint", unsafe.Sizeof(uint(1))) // 8
fmt.Println("---------------------------")
fmt.Println("float32", unsafe.Sizeof(float32(1))) // 4
fmt.Println("float64", unsafe.Sizeof(float64(1))) // 8
fmt.Println("---------------------------")
fmt.Println("*T", unsafe.Sizeof(uintptr(1))) // 8
fmt.Println("*T", unsafe.Sizeof(uintptr('0'))) // 8
fmt.Println("---------------------------")
fmt.Println("map", unsafe.Sizeof(map[string]string{})) // 8
fun := func() {}
fmt.Println("func", unsafe.Sizeof(fun)) // 8
fmt.Println("---------------------------")
fmt.Println("string", unsafe.Sizeof(string(""))) // 16
var a interface{}
fmt.Println("interface", unsafe.Sizeof(a)) // 16
fmt.Println("---------------------------")
fmt.Println("[]T", unsafe.Sizeof([]string{})) // 24
var s [15]uint32
fmt.Println("[15]T",unsafe.Sizeof(s)) //60
// go 图像库中头信息类
type TGIHeader struct {
_ uint16 // Reserved
_ uint16 // Reserved
Width uint32
Height uint32
//_ [15]uint32 // 15 "don't care" dwords
SaveTime int64
}
fmt.Println(unsafe.Sizeof(TGIHeader{})) //80
}
func main() {
method1()
}
对于Go语言的内置类型,占用内存大小如下:
| 类型 | 字节数 |
|---|---|
| bool | 1个字节 |
| intN, uintN, floatN, complexN | N/8 个字节 (int32 是 4 个字节) |
| int, uint, uintptr | 计算机字长/8 (64位 是 8 个字节) |
| *T, map, func, chan | 计算机字长/8 (64位 是 8 个字节) |
| string (data、len) | 2 * 计算机字长/8 (64位 是 16 个字节) |
| interface (tab、data 或 _type、data) | 2 * 计算机字长/8 (64位 是 16 个字节) |
| []T (array、len、cap) | 3 * 计算机字长/8 (64位 是 24 个字节) |
| [nums]T | nums * T类型的字节数 |
2.2.对齐系数
- 对于任意类型的变量 x ,unsafe.Alignof(x) 至少为 1。
- 对于 struct 结构体类型的变量 x,计算 x 每一个字段 f 的 unsafe.Alignof(x.f),unsafe.Alignof(x) 等于其中的最大值。
- 对于 array 数组类型的变量 x,unsafe.Alignof(x) 等于构成数组的元素类型的对齐倍数。
| type | 对齐系数 |
|---|---|
| bool,byte,uint8,int8 | 1 |
| uint16,int16 | 2 |
| uint32,int32,float32 | 4 |
| uint32,int32,float32 | 4 |
| arrays | 由其元素决定 |
| struct | 由其字段决定 |
对齐规则
我们讲内存对齐,就是把变量放在特定的地址,那么如何计算特定地址呢,这就涉及到内存对齐规则:
- 成员对齐规则:针对一个基础类型变量,如果 unsafe.AlignOf() 返回的值是 m,那么该变量的地址需要 被m整除 ,如果当前地址不能整除,填充空白字节,直至可以整除。
- 整体对齐规则:针对一个结构体,如果 unsafe.AlignOf() 返回值是 m,需要保证该结构体整体内存占用是 m的整数倍,如果当前不是整数倍,需要在后面填充空白字节。
通过内存对齐后,就可以在保证在访问一个变量地址时:
- 如果该变量占用内存小于字长:保证一次访问就能得到数据;
- 如果该变量占用内存大于字长:保证第一次内存访问的首地址,是该变量的首地址。
三.struct 内存对齐的技巧
type demo1 struct {
a int8
b int16
c int32
}
type demo2 struct {
a int8
c int32
b int16
}
func main() {
fmt.Println(unsafe.Sizeof(demo1{})) // 8
fmt.Println(unsafe.Sizeof(demo2{})) // 12
}
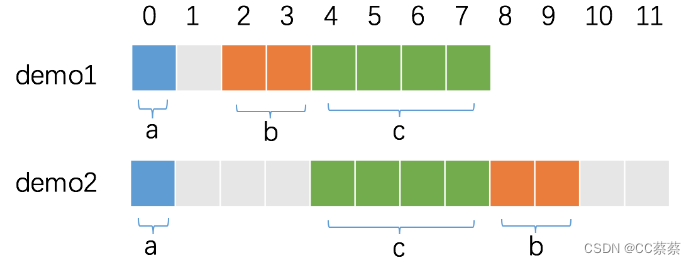
答案是会产生影响。每个字段按照自身的对齐倍数来确定在内存中的偏移量,字段排列顺序不同,上一个字段因偏移而浪费的大小也不同。
接下来逐个分析,首先是 demo1:
- a 是第一个字段,默认是已经对齐的,从第 0 个位置开始占据 1 字节。
- b 是第二个字段,对齐倍数为 2,因此,必须空出 1 个字节,偏移量才是 2 的倍数,从第 2 个位置开始占据 2 字节。
- c 是第三个字段,对齐倍数为 4,此时,内存已经是对齐的,从第 4 个位置开始占据 4 字节即可。
因此 demo1 的内存占用为 8 字节。
其实是 demo2:
- a 是第一个字段,默认是已经对齐的,从第 0 个位置开始占据 1 字节。
- c 是第二个字段,对齐倍数为 4,因此,必须空出 3 个字节,偏移量才是 4 的倍数,从第 4 个位置开始占据 4 字节。
- b 是第三个字段,对齐倍数为 2,从第 8 个位置开始占据 2 字节。
demo2 的对齐倍数由 c 的对齐倍数决定,也是 4,因此,demo2 的内存占用为 12 字节。
四.空结构体的对齐规则
空 struct{} 大小为 0,作为其他 struct 的字段时,一般不需要内存对齐。但是有一种情况除外:即当 struct{} 作为结构体最后一个字段时,需要内存对齐。
func method3() {
type demo1 struct {
c struct{}
a int32
b int32
}
type demo2 struct {
a int32
c struct{}
b int32
}
type demo3 struct {
a int32
b int32
c struct{}
}
type demo4 struct {
a int32
b int64
c struct{}
}
type demo5 struct {
b int64
a int32
c struct{}
}
fmt.Println(unsafe.Sizeof(demo1{})) // 8
fmt.Println(unsafe.Sizeof(demo2{})) // 8
fmt.Println(unsafe.Sizeof(demo3{})) // 12
fmt.Println(unsafe.Sizeof(demo4{})) // 24
fmt.Println(unsafe.Sizeof(demo5{})) // 16
}
demo4 结构体尾部size为0的变量(字段)会被分配内存空间进行填充,原因是如果不给它分配内存,该变量指针将指向一个非法的内存空间(内存泄漏的风险)。
比如说我连续分配了两个demo4 结构体,那么如果不存在这个内存填充,那么demo4.c的位置实际上是等于下一个demo4的位置的,导致了非法内存访问.
结论:如果空结构体作为结构体的内置字段:当变量位于结构体的前面和中间时,不会占用内存;当该变量位于结构体的末尾位置时,需要进行内存对齐,内存占用大小和前一个变量的大小保持一致。
五.总结
总结- 内存对齐是为了让 cpu 更高效访问内存中数据
- unsafe.Sizeof(x) 返回了变量x的内存占用大小;
- 两个结构体,即使包含变量类型的数量相同,但是位置不同,占用的内存大小也不同,由此引出了内存对齐;
- 内存对齐包含成员对齐和整体对齐,与 unsafe.AlignOf(x) 息息相关;
- 空结构体作为成员变量时,要避免作为 struct 最后一个字段,会有内存浪费;















 1110
1110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









