






RDD操作
- 转化(Transformation):泛指接收RDD作为输入,并输出RDD的函数。被划分为窄依赖和宽依赖。
- 行为(Action):将RDD转化为非RDD的变量的操作。通常用于返回RDD计算的最终结果。
窄依赖和宽依赖
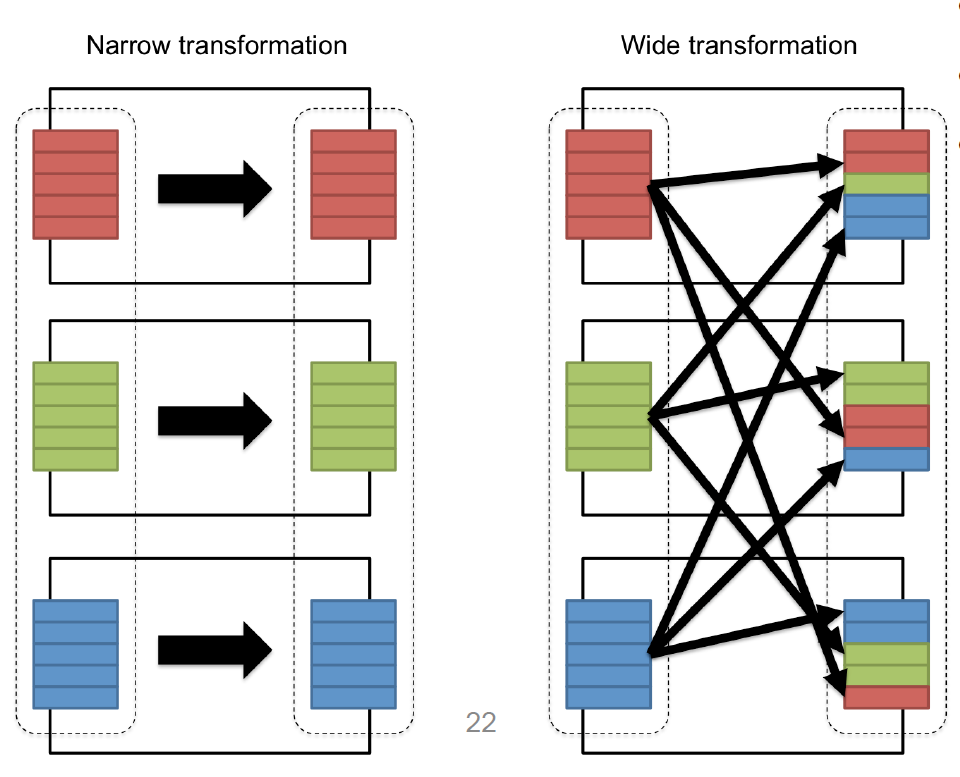
- 窄依赖(Narrow Dependencies):父RDD集的一个分区最多被子RDD集的一个分区所依赖。
常见的有map, flatMap, filter, sample ...
- 宽依赖(Wide Dependencies):父RDD集的一个分区可以被子RDD集的多个分区所依赖。
常见的有sortByKey, reduceByKey, groupByKey, join ...
什么是Shuffle
在Spark中,每个任务对应一个分区,通常不会跨分区操作数据。但如果遇到宽依赖的操作,Spark必须从所有分区读取数据,并查找所有键的对应值,然后汇总在一起以计算每个键的最终结果,这称为Shuffle。Shuffle是一项昂贵的操作,因为它通常会跨节点操作数据,这会涉及磁盘 I/O,网络 I/O,和数据序列化。某些Shuffle操作还会消耗大量的堆内存,因为它们使用堆内存来临时存储需要网络传输的数据。
如何划分Stage
言归正传,Stage的划分,是以result和shuffle这两种类型来划分task。对于窄依赖,由于分区依赖关系的确定性,partition的转换处理可以在同一个线程里完成,称之为resultTask。而对于宽依赖,只能等父RDD集的shuffle处理完成后,在下一个stage才能开始接下来的计算,称之为shuffleMapTask。
因此划分Stage的规则如下:从后往前推RDD算子,如果遇到宽依赖就断开,划分为一个stage;如果遇到窄依赖就将这个RDD加入当前的stage。
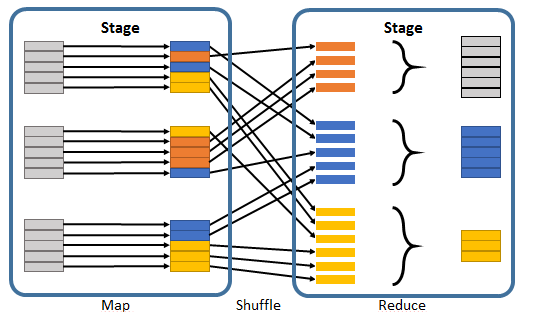
举个栗子,如下图的Spark任务应该被划分为2个stage。















 760
760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









