





import keras
keras.__version__
我们现在来看一个神经网络的第一个具体例子,它使用Python库Keras来学习分类
手写数字。除非您已经有使用Keras或类似库的经验,否则您不会完全理解这一点
第一个例子马上。你可能还没有安装Keras。别担心,那很好。在下一章中,我们将
回顾我们例子中的每个元素并详细解释它们。所以,不要担心某些步骤在你看来是武断的还是魔术般的!
我们得从某个地方开始。
我们试图解决的问题是将手写数字的灰度图像(28像素乘28像素)分类为10个
类别(0到9)。我们将使用的数据集是MNIST数据集,它是机器学习社区中的一个经典数据集
几乎和这个领域一样长的时间里,人们对它进行了非常深入的研究。这是一组60000张训练图片,加上10000次测试
图片,由美国国家标准与技术研究所(NIST)在20世纪80年代组装而成。你可以考虑“解决”MNIST
作为深度学习的“你好世界”——你要做的就是验证你的算法是否按预期工作。当你变成一台机器
学习实践者,你会看到MNIST一次又一次的出现,在科学论文,博客文章,等等。
MNIST数据集以四个Numpy数组的形式预先加载在Keras中:
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
`train_images和train_labels构成“训练集”,模型将从中学习数据。然后将在
“测试集”、“测试图像”和“测试标签”。我们的图像被编码为Numpy数组,标签只是一个数字数组,范围很广
从0到9。图像和标签之间有一对一的对应关系。
让我们看看培训数据:
train_images.shape
len(train_labels)
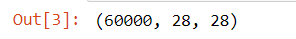
len(train_labels)
train_labels

train_labels
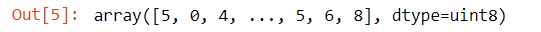
 同样可以获得测试样本的数据信息
同样可以获得测试样本的数据信息
我们的工作流程如下:首先,我们将呈现我们的神经网络与训练数据,训练图像和训练标签。然后,网络将学习关联图像和标签。最后,我们将要求网络为test_图像生成预测,并且我们将验证这些预测是否与test_标签中的标签匹配。
from keras import models
from keras import layers
network = models.Sequential()
network.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,)))
network.add(layers.Dense(10, activation='softmax'))
神经网络的核心组成部分是“layer”,这是一个数据处理模块,你可以把它看作是数据的“过滤器”。一些数据以一种更有用的形式出现。准确地说,层从提供给它们的数据中提取表示——希望表示对当前的问题更有意义。大多数深度学习实际上包括将简单的层链接在一起,从而实现一种渐进的“数据蒸馏”形式。一个深度学习模型就像一个数据处理的筛子,由一系列越来越精细的数据过滤器——“layer”组成。
在这里,我们的网络由两个密集层组成,这两个密集层是密集连接(也称为“完全连接”)的神经层。第二层(也是最后一层)是一个10路“softmax”层,这意味着它将返回一个由10个概率分数组成的数组(总和为1)。每个分数将是当前数字图像属于我们的10位数类之一的概率。
为了使我们的网络做好培训准备,我们还需要选择三件事,作为“编译”步骤的一部分:
损失函数:是指网络如何能够根据其培训数据来衡量其工作有多出色,从而如何能够将自己引导到正确的方向。
优化器:这是一种机制,通过它,网络将根据它看到的数据和它的丢失功能来更新自己。
在培训和测试期间监控的指标。这里我们只关心准确性(正确分类的图像的分数)。
损失函数和优化器的确切用途将在之后阐明。
network.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
在训练之前,我们将对数据进行预处理,方法是将其重塑为网络所期望的形状,并对其进行缩放,使所有值都在[0,1]区间内。例如,我们的训练图像存储在uint8类型的形状数组(60000,28,28)中,其值在[0,255]区间内。我们将其转换为值介于0和1之间的float32形状数组(60000,28*28)。
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype('float32') / 255
我们还需要对标签进行分类编码
from keras.utils import to_categorical
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
我们现在已经准备好训练我们的网络了,这在Keras中是通过调用网络的fit方法来完成的:我们将模型“fit”到它的训练数据。
network.fit(train_images, train_labels, epochs=5, batch_size=128)

训练过程中显示两个数量:网络在训练数据上的“loss”和网络在训练数据上的accuracy。
在训练数据上,我们很快达到了0.989(即98.9%)的准确率。现在让我们检查一下我们的模型在测试集上是否也表现良好:
test_loss, test_acc = network.evaluate(test_images, test_labels)
print('test_acc:', test_acc)
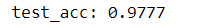
我们的测试集准确率是97.8%——这比训练集的准确率要低很多。训练精度和测试精度之间的差距就是“过度拟合”的一个例子,即机器学习模型在新数据上的表现往往比在其训练数据上的表现差。之后会介绍到overfitting
我们的第一个例子到此结束——您刚刚看到了我们如何构建和训练一个神经网络,用不到20行的Python代码对手写数字进行分类。接下来,将详细介绍我们刚刚预演的每一步,并澄清幕后到底发生了什么。您将了解“张量”,存储进入网络的对象的数据,张量操作,由哪些层组成,以及梯度下降,这使我们的网络能够从其训练示例中学习。















 256
256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









