








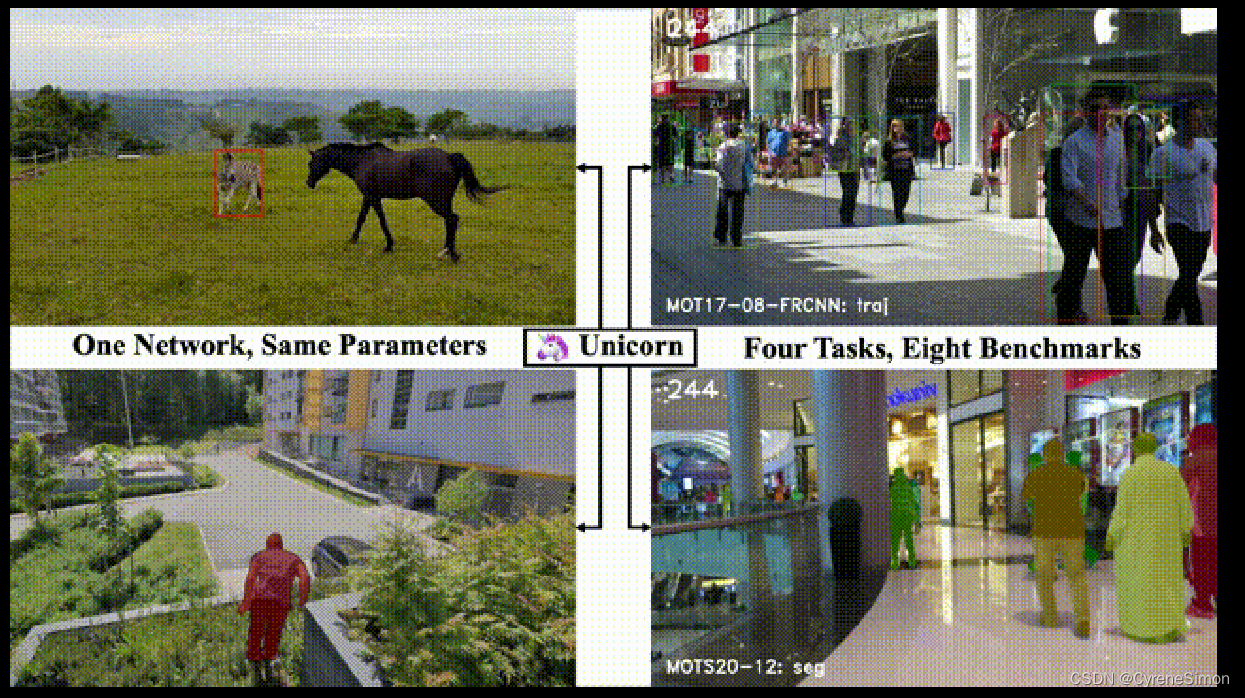
论文的模型可在四个视觉跟踪任务中取得优异的成绩
1.单目标跟踪(SOT)
2.视频目标分割(VOS)
3.多目标跟踪(MOT)
4.多目标跟踪与分割(MOTS)
demo图
1.Abstrac
论文提出了一个统一的方法,称为Unicorn,可以同时解决四个跟踪问题(SOT,MOT,VOS,MOTS)与一个单一的网络使用相同的模型参数。由于对目标跟踪问题本身的不完整定义,大多数现有的跟踪器都是针对单个或部分任务开发的,并且过于专注于特定任务的特征。相比之下,Unicorn提供了一个统一的解决方案,在所有跟踪任务中采用相同的输入、主干、嵌入和头部(the same input, backbone, embedding, and head across all tracking tasks)。我们第一次实现了跟踪网络结构和学习范式的大统一。在8个跟踪数据集上,Unicorn的性能相当于或优于其特定任务的计数器部分,包括LaSOT、TrackingNet、MOT17、BDD100K、DAVIS16-17、MOTS20和BDD100K MOTS。
2.Related Work
作者认为大多数跟踪方法仅针对一个或部分子任务而开发,尽管对于特定的应用来说很方便,但是这种分散的情况带来了以下缺点。
(1)Trackers可能过度专注于特定子任务的特征,缺乏概括能力。
(2)独立模型设计导致参数冗余。
例如,最近基于深度学习的跟踪器通常采用类似的主干架构,但独立的设计理念阻碍了参数的潜在重用。
本文研究问题:
所有主流跟踪任务都可以用一个统一的模型解决吗?
Can all main-stream tracking tasks be solved by a unified model?
尽管一些作品试图通过在现有的盒子级跟踪系统中添加一个掩码分支来统一SOT&VOS或MOT&MOTS,但在SOT和MOT的统一方面仍然进展甚微。
阻碍这一进程的主要有三个障碍。
(1)被跟踪对象的特征各不相同。MOT通常跟踪几十甚至几百个特定类别的实例。
相比之下,SOT需要跟踪参考坐标系中给定的一个目标,而不管它属于哪一类。
(2) SOT和MOT要求不同类型的通信。SOT要求将目标从背景中区分出来。
然而,MOT需要将当前检测到的物体与之前的轨迹进行匹配。
(3)大多数SOT方法只进行一次小的搜索区域作为输入以节省计算并过滤潜在的干扰物。
然而,MOT算法通常将高分辨率(high-resolution full image)
的完整图像作为输入,以尽可能完整地检测实例。
2.论文方法
two core design
1. target prior 目标先验
2. pixel-wise correspondence 像素级对应关系
具体方法如下:
1.target prior 是detection head 的附加输入,并作为四个任务之间的开关
(the target prior is an additional input for the detection head and serves as the switch among four tasks.)
对于SOT&VOS,目标先验是传播的参考目标图,使得头部能够聚焦在被跟踪的目标上。
对于MOT&MOTS,通过将目标先验设置为零,头部平滑地退化为通常的特定类别检测头。
2.逐像素对应是来自参考帧和当前帧的所有点对之间的相似性。
The pixel-wise correspondence is the similarity between all pairs of points from the reference frame and the current frame
SOT对应和MOT对应都是逐像素对应的子集。
(3)在提供信息的 target prior和精确的逐像素对应的帮助下,搜索区域的设计对于SOT变得不必要。直接采用统一的完整图像输入。
With the help of the informative target prior and the accurate pixel-wise correspondence, the design of the search region becomes unnecessary for SOT, leading to unified inputs as the full image for SOT and MOT.
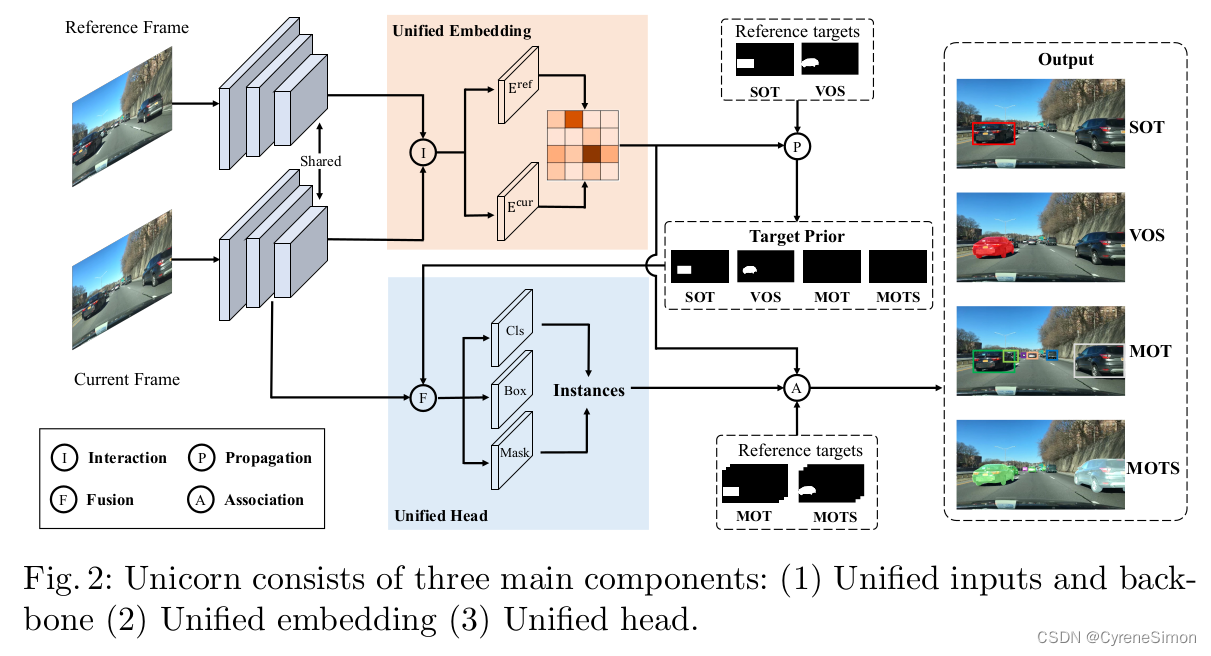
为了统一目标跟踪,论文提出了Unicorn,一个单一的网络架构来解决四个跟踪任务。它以参考帧和当前帧作为输入,通过一个权重共享(weight-shared)的主干产生它们的视觉特征。然后,利用特征交互模块(feature interaction module )来建立两帧之间的逐像素对应关系。基于该对应关系,通过将参考目标传播到当前帧来生成target prior。最后,融合目标先验信息和视觉特征,发送给detection head,得到所有任务的跟踪目标。

工作有以下贡献
Unicorn首次实现了网络架构和四种跟踪任务学习范式的大统一。
Unicorn通过目标先验和逐像素对应,弥合了四种跟踪任务方法之间的差距。
Unicorn在具有相同模型参数的8个具有挑战性的跟踪基准测试中提出了新的最先进的性能。
这一成就将成为迈向通用愿景模型的坚实一步。
3.Approach
作者提出了一个用于对象跟踪的统一解决方案,称为Unicorn,它由三个主要组件组成:
unified inputs and backbone 统一输入和主干
unified embedding 统一嵌入
unified head 统一头
三个组件分别负责获取强大的视觉表示、建立精确的对应关系和检测不同的跟踪目标。图2展示了Unicorn的框架,给出了参考帧Iref、当前帧Icur和参考目标,Unicorn旨在使用统一网络预测四个任务在当前帧上被跟踪目标的状态。

3.1Unified Inputs and Backbone
为了有效地定位多个潜在目标,Unicorn采用整个图像(对于参考帧和当前帧)而不是局部搜索区域作为输入。这也赋予了Unicorn很高的抗跟踪失败能力,以及消失后re-detect被跟踪目标的能力。
在特征提取期间,参考帧和当前帧通过权重共享骨干网传递,以获得特征金字塔表示(FPN) [32]。为了在计算对应关系期间保持重要的细节并减少计算负担,我们选择stride为16的特征图作为后续嵌入模块的输入。来自参考帧和当前帧的相应特征分别被称为Fref和Fcur。
3.2Unified Embedding
目标跟踪的核心任务是在视频中的帧之间建立准确的对应关系。 对于 SOT 和 VOS,逐像素对应将用户提供的目标从参考帧(通常是第 1 帧)传播到第 t 帧,为最终的框或掩码预测提供强大的先验信息。
此外,对于 MOT 和 MOTS,实例级对应有助于将第 t 帧上检测到的实例与参考帧(通常是第 t-1 帧)上的现有轨迹相关联。
在 Unicorn 中,给定空间扁平化的参考帧嵌入 Eref 和当前帧嵌入 Ecur ,像素级对应关系 Cpix 通过它们之间的矩阵乘法计算。对于将完整图像作为输入的 SOT&VOS,对应关系本身就是逐像素对应关系。 对于MOT&MOTS,假设参考帧上有M个轨迹,当前帧上分别有N个检测到的实例,实例级(instance-level )对应关系C inst是参考实例嵌入(reference instance embedding)e ref的矩阵乘法, 当前实例嵌入 e cur 。 实例嵌入 e 是从实例中心所在的帧嵌入 E 中提取的。
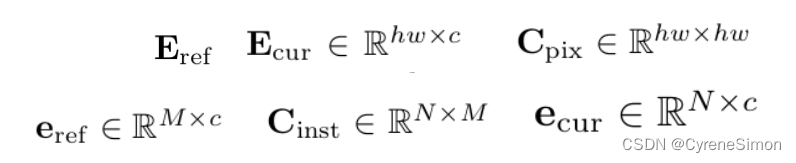
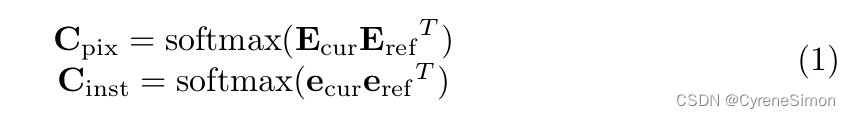
可以看出,MOT和MOTS所需的实例级对应关系C inst 是像素级对应关系C pix 的子矩阵。此外,学习高度判别嵌入{E ref , E cur } 是为所有跟踪任务建立精确对应关系的关键。
Feature Interaction
由于其捕捉远程依赖性的优势,Transformer是增强原始特性的直观选择
表示{F ref,F cur }。
然而,在处理高分辨率特征图时,这可能会导致巨大的内存消耗,因为内存消耗随着输入序列的长度呈二次方增加。为了缓解这个问题,我们用内存效率更高的可变形注意力( deformable attention)代替了全部注意力。
为了更准确的对应,将增强的特征图上采样 2 倍以获得步幅为 8 的高分辨率嵌入

Loss
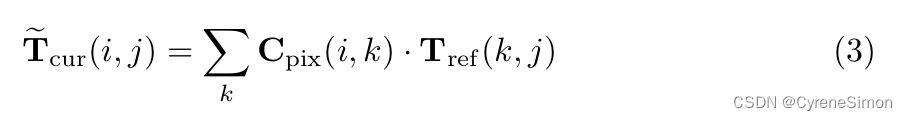
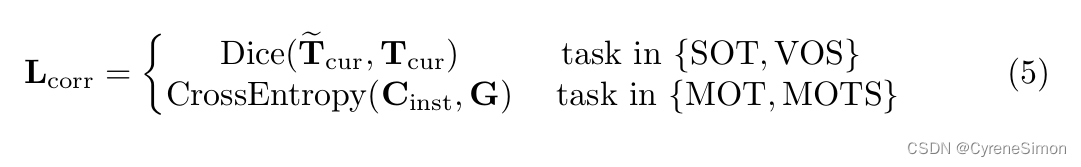
Unified Head
待更…
Experiments
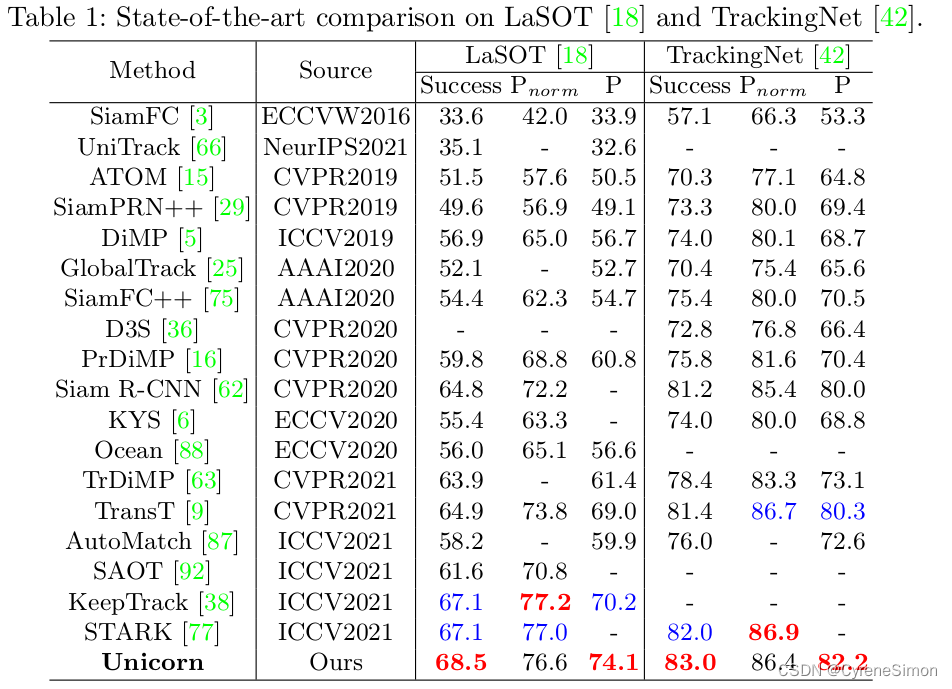
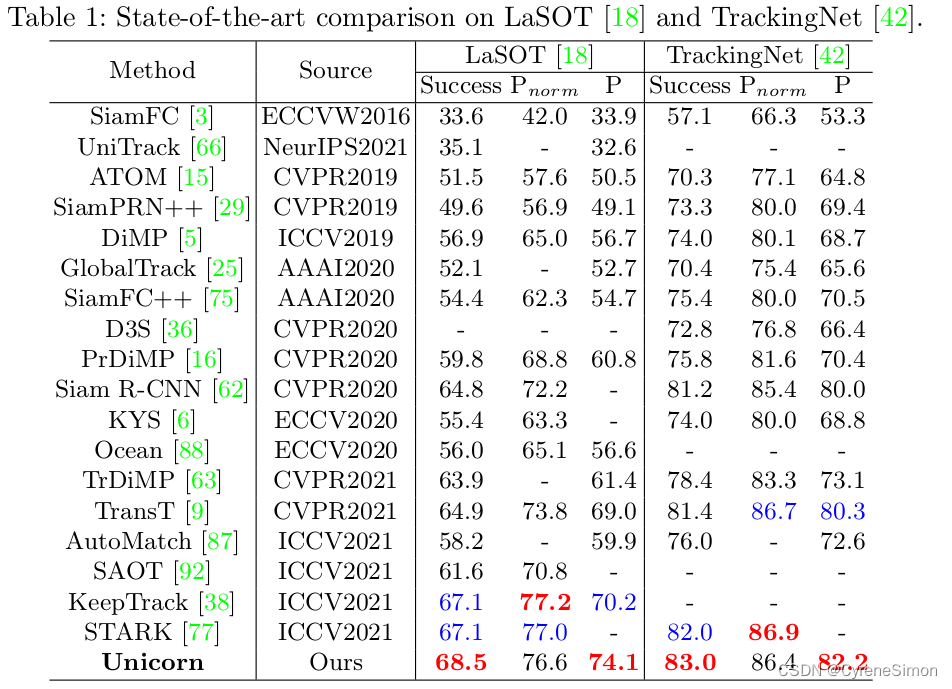
Evaluations on Single Object Tracking
Evaluations on Multiple Object Tracking
Evaluations on Video Object Segmentation
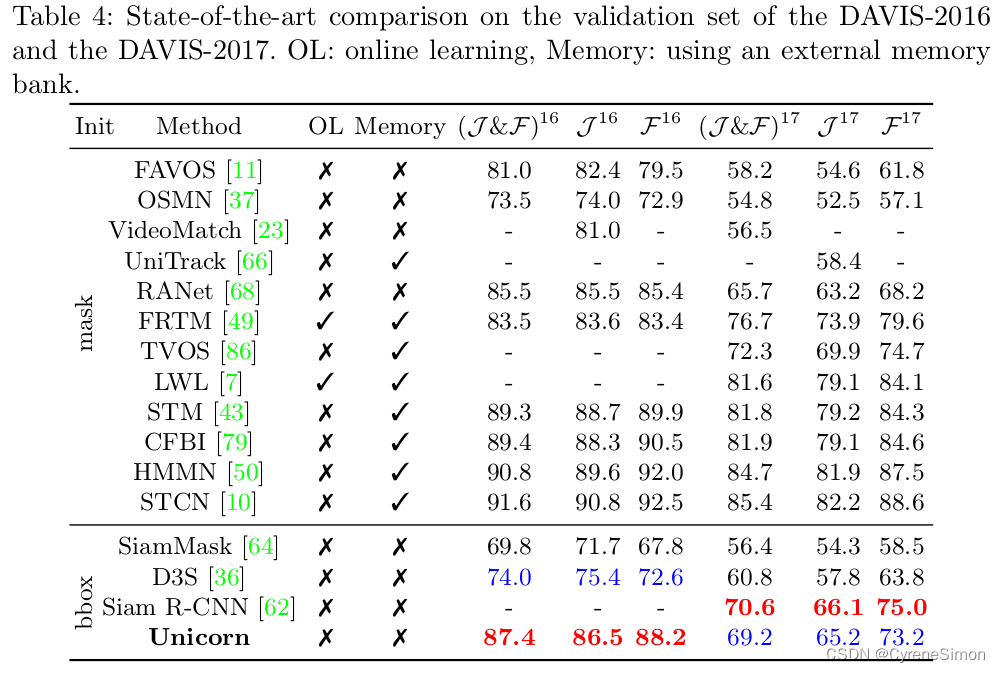
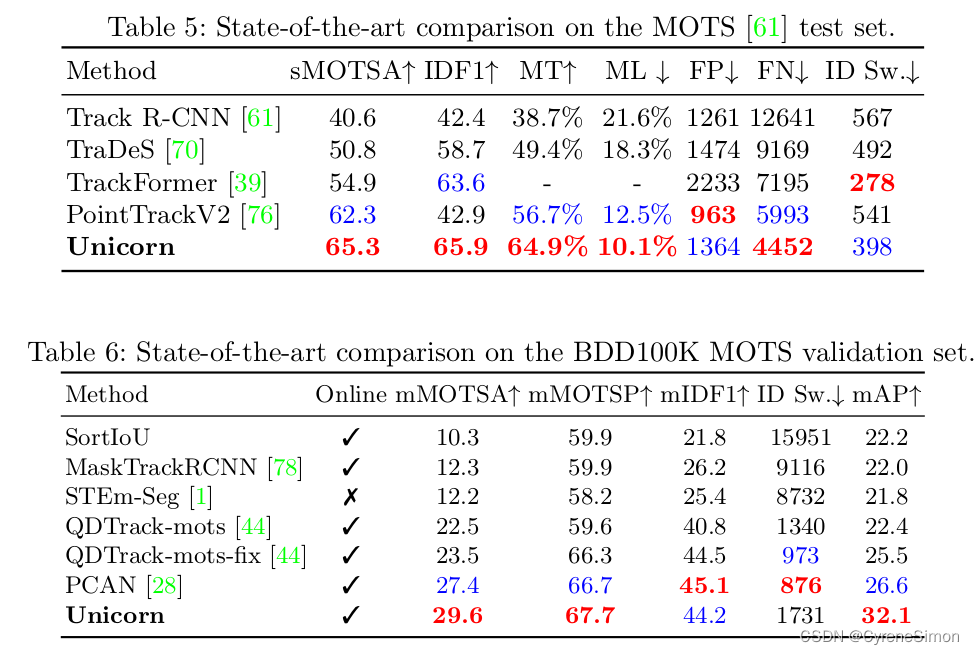
Evaluations on Multi-Object Tracking and Segmentation















 723
723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









