







 本文记录了使用TextCNN模型参与新闻文本分类竞赛的过程,详细介绍了模型应用、参数调整及效果评估,最终在官方测试集中获得0.9328分。
本文记录了使用TextCNN模型参与新闻文本分类竞赛的过程,详细介绍了模型应用、参数调整及效果评估,最终在官方测试集中获得0.9328分。
本文是对阿里云新人竞赛中的“零基础入门NLP - 新闻文本分类”解体过程进行的记录,目前仅使用了textCNN模型进行预测,后续还会考虑使用LSTM进行对比。
赛题数据
赛题以新闻数据为赛题数据,数据集报名后可见并可下载。赛题数据为新闻文本,并按照字符级别进行匿名处理。整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐的文本数据。
赛题数据由以下几个部分构成:训练集20w条样本,测试集A包括5w条样本,测试集B包括5w条样本。为了预防选手人工标注测试集的情况,我们将比赛数据的文本按照字符级别进行了匿名处理。
解题思路:
官方给出了多种模型的解题方法,包括fastText、TextCNN、TF-IDF、TextRNN等。我按照官方教程跑通TF-IDF后发现得分只有0.87左右,尝试更改参数后提升不大,故考虑改用TextCNN进行预测。
目前使用的网络结构如下:

其中使用三种不同尺寸的fiter对文本数据进行卷积。
由于原始数据长度分布中位值大概在2000字符左右,作为初次试算,选择构建vocabulary的的最大字长取为1000字符。
第一次选择1w数据量进行训练和验证,其中训练集80%,结果如下,可见在40次迭代后训练集精度达到1左右,已经很难再继续下降了。此时考虑增加数据量至10w,并将学习率设置为随迭代梯度下降。目前训练到50epoch,使用官方提供的测试数据,打分为0.9328,排名大概60+。
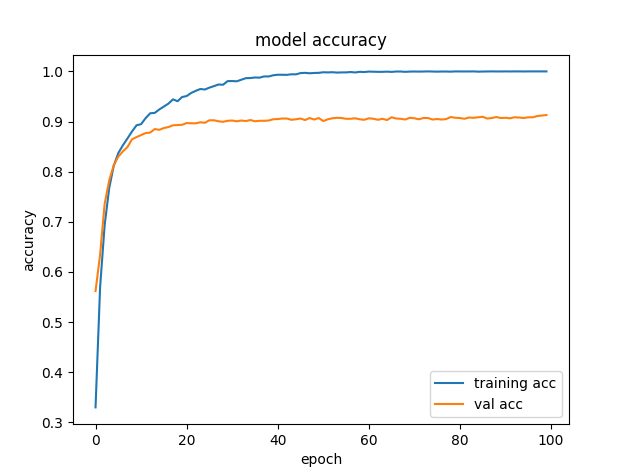
精度收敛曲线
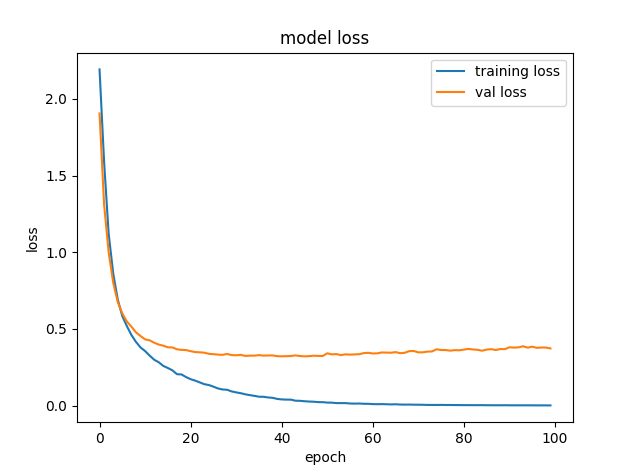
损失收敛曲线
发布于 55 分钟前

















 528
528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









