







1. What does literature study?
利用注意力网络和神经协同过滤设计了基于神经网络的解决方案。**首先,**我们采用一种注意网络,通过聚合group成员的嵌入来形成group表征,从而动态地从数据中获取group成员注意权重。**其次,**通过另一个注意网络将社交followee信息整合起来,增强个体用户的表征能力,有助于捕获用户的个人偏好。**最后,**考虑到许多在线group系统也存在大量用户在项目上的交互,我们进一步将user-item交互的建模集成到我们的方法中。
2. What’s the innovation?
- Past shortcomings
1. 基于内存的group推荐采用偏好聚合以及分数聚合,这两种方法都是预定义的。不灵活并且使用繁琐的方式来聚合用户偏好。 - innovation:
1. 利用神经注意网络从数据中动态学习聚合策略。
2. 通过利用用户的社交followee信息进一步提高了用户的表征学习,此外,user-item交互进一步整合。group-item和user-item推荐性能可以相互加强。
3. What was the methodology?
1,分层注意网络,利用双层注意网络在一个分层结构中表示group组和用户。
2,利用NCF交互学习为用户和组推荐。
n
u
n_u
nu个用户,
U
=
{
u
1
,
u
2
,
.
.
.
,
u
n
u
}
\mathcal{U}=\{ u_1,u_2,...,u_{n_u}\}
U={u1,u2,...,unu},
n
g
n_g
ng个组
G
=
{
g
1
,
g
2
,
.
.
.
,
g
n
g
}
\mathcal{G}=\{ g_1,g_2,...,g_{n_g}\}
G={g1,g2,...,gng},
n
f
n_f
nf个followee用户
F
=
{
f
1
,
f
2
,
.
.
.
,
f
n
f
}
\mathcal{F}=\{ f_1,f_2,...,f_{n_f}\}
F={f1,f2,...,fnf}以及
n
i
n_i
ni个items
V
=
{
v
1
,
v
2
,
.
.
.
,
v
n
i
}
\mathcal{V}=\{ v_1,v_2,...,v_{n_i}\}
V={v1,v2,...,vni},第
l
l
l个group
g
l
∈
G
g_l \in \mathcal{G}
gl∈G由一系列用户组成,组成员用户索引
K
l
=
{
k
l
,
1
,
k
l
,
2
,
.
.
.
,
k
l
,
∣
g
l
∣
}
\mathcal{K_l}=\{ k_{l,1},k_{l,2},...,k_{l,|g_l|}\}
Kl={kl,1,kl,2,...,kl,∣gl∣},其中
∣
g
l
∣
|g_l|
∣gl∣是组的大小,第
i
i
i个用户的followees下标为
H
i
=
{
h
i
,
1
,
h
i
,
2
,
.
.
.
,
h
i
,
∣
u
i
∣
}
\mathcal{H_i}=\{ h_{i,1},h_{i,2},...,h_{i,|u_i|}\}
Hi={hi,1,hi,2,...,hi,∣ui∣},
∣
u
i
∣
|u_i|
∣ui∣是followees的数量。有四种观察的交互数据
U
,
G
,
F
,
V
\mathcal{U},\mathcal{G},\mathcal{F},\mathcal{V}
U,G,F,V分别为user-item交互,group-item交互,group-user交互以及user-followee交互。给定一个目标组(或目标用户),我们的任务被定义为推荐组(或用户)可能感兴趣的项目列表。
a. 分层注意网络学习:
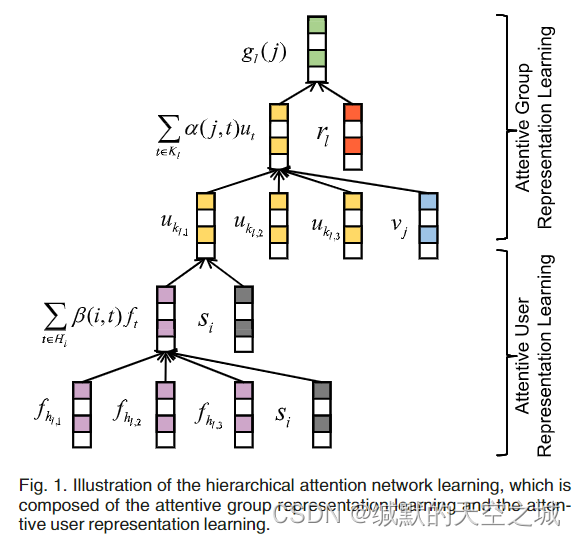
α
(
j
,
t
)
\alpha(j,t)
α(j,t)表示第
i
i
i用户对item
j
j
j的喜好程度,
β
(
i
,
t
)
\beta(i,t)
β(i,t)表示第
t
t
t个followee对用户
i
i
i影响程度。
group-level attention和user-level attention
Attentive 组表示学习:
u
i
,
v
j
\mathbf{u_i},\mathbf{v_j}
ui,vj分别表示
u
i
,
v
j
u_i,v_j
ui,vj嵌入,目标是获取每个组的嵌入向量,以估计其对一个item的偏好,为了从数据中学习动态聚合策略,需要将组嵌入定义为依赖于其成员用户和目标项的嵌入,抽象为:
g
l
(
j
)
=
f
g
(
v
j
,
{
u
l
l
∈
K
l
}
)
g_l(j) = f_g(\mathbf{v_j},\{\mathbf{u_l}_{l\in \mathcal{K_l}}\})
gl(j)=fg(vj,{ull∈Kl}),
g
l
(
j
)
g_l(j)
gl(j)表示组
g
l
g_l
gl的嵌入,用来预测其对目标item
v
j
v_j
vj的偏好,
K
l
\mathcal{K_l}
Kl包含组
g
l
g_l
gl的用户索引,
f
g
f_g
fg是聚合函数。
忽略社交影响的组推荐Attentive group中组嵌入由两个部分组成:用户嵌入聚合以及组偏好嵌入。
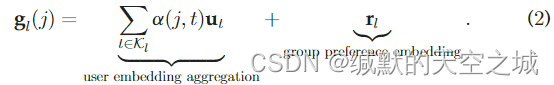
componet1用户嵌入聚合:
在组
g
l
g_l
gl成员用户的嵌入上执行了加权和,其中
α
(
j
,
t
)
\alpha(j,t)
α(j,t)是可权重参数表示用户
u
l
u_l
ul在决定group对item
v
j
v_j
vj选择时的影响,如果一个用户对某个item(或类似类型的项目)有更多的expertise,他应该对group的选择产生更大的影响力,例如:(一个团队讨论去哪个城市旅行; 如果一个用户去过中国很多次,那么在团队考虑是否应该去中国的一个城市时,她应该更有影响力。)表示学习框架中,嵌入
u
l
\mathbf{u_l}
ul编码了用户的历史偏好,嵌入
v
j
\mathbf{v_j}
vj编码了目标项目的属性,参数化
α
(
j
,
t
)
\alpha(j,t)
α(j,t)作为一个神经注意网络的输入。
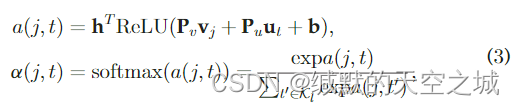
其中
P
v
\mathbf{P_v}
Pv和
P
u
\mathbf{P_u}
Pu分别作为将项目嵌入和用户嵌入转换为隐藏层的注意网络的权重矩阵,
b
\mathbf{b}
b作为隐藏层的偏向量。ReLU作为隐藏层的激活函数,通过softmax正则化分数,使注意网络成为一种概率,可以处理不同大小的group,允许每个成员用户参与group决策,其中用户的贡献取决于用户的历史偏好和目标项目的属性,这些从group-item以及user-item交互中学到。
**componet2组偏好嵌入:**考虑到在某些情况下,当用户组成一个group时,他们可能会追求一个与每个用户偏好不同的目标,例如:(例如,在一个三个家庭中,孩子更喜欢卡通电影,父母倾向于浪漫电影;但是,当他们一起去看电影时,最终的电影可以成为一个教育电影。)因此,将一个group与一个embedding联系起来表示她的一般偏好是有效的。为了将组偏好嵌入与用户嵌入聚合进行组合,执行了一个简单的加法操作
Attentive 用户表示学习:
社交followee信息整合到用户表示学习中,用户的followee被视为其属性,利用注意权重聚合。followee
f
i
f_i
fi的嵌入向量
f
i
\mathbf{f_i}
fi是推断社交影响的基本成分。定义用户嵌入为一个函数,其followee嵌入为输入。
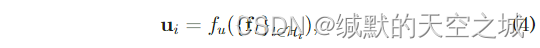
H
i
\mathcal{H_i}
Hi包含用户
u
i
u_i
ui的followee 索引,
f
u
f_u
fu是聚合函数,定义用户嵌入为followee嵌入聚合以及用户偏好嵌入。

用户
u
i
u_i
ui的第
t
t
t个followee的注意分数也是一个两层网络:
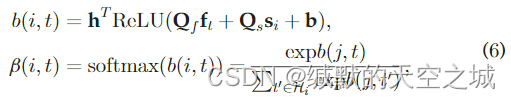
其中
Q
f
\mathbf{Q_f}
Qf和
Q
s
\mathbf{Q_s}
Qs分别作为将followee嵌入和用户偏好嵌入转换为隐藏层的注意网络的权重矩阵,
b
\mathbf{b}
b作为隐藏层的偏向量。ReLU作为隐藏层的激活函数,通过softmax正则化分数。用户followee对用户的表征贡献是不平等的,用户嵌入与用户偏好嵌入
s
i
s_i
si相关联,用户偏好嵌入考虑了用户的一般偏好。
b. 利用NCF交互学习
NCF是一个多层神经网络框架,将用户嵌入和项目嵌入feed into 神经网络以便从数据中学习交互函数,神经网络由较强的数据拟合能力,NCF框架比传统的MF模型更具通用性,简单地应用与数据无关的内积函数作为交互函数。
同时学习group-item交互函数和user-item交互函数,给定一个user-item对
(
u
i
,
v
j
)
(u_i,v_j)
(ui,vj)或一个group-item对
(
g
l
,
v
j
)
(g_l,v_j)
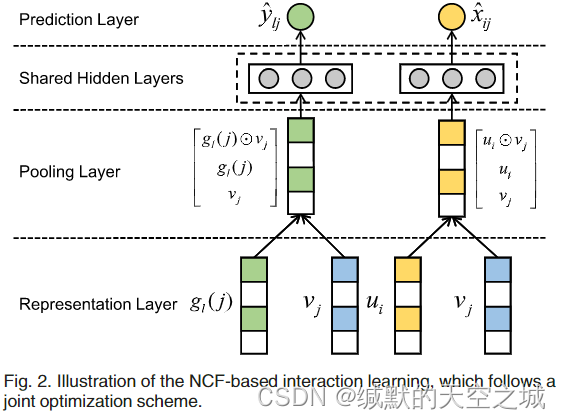
(gl,vj),表示层为每个给定的实体返回嵌入向量,embeddings进入pooling 层和hidden 层获得预测分数。
pooling layer将原始用户嵌入和项目嵌入连接起来,方便后续隐藏层的学习,(element-wise乘积可能会在原始嵌入中丢失一些信息)
hidden layer捕捉用户,组,和项目之间的非线性和高阶相关性。最后一层隐藏层的输出用来预测分数:
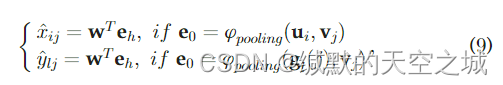
x
^
i
j
\hat{x}_{ij}
x^ij表示user-item对
(
u
i
,
v
j
)
(u_i,v_j)
(ui,vj)的预测,
y
^
l
j
\hat{y}_{lj}
y^lj表示对group-item对
(
g
l
,
v
j
)
(g_l,v_j)
(gl,vj)的预测。这两个任务共享相同的隐藏层,因为group嵌入是通过用户嵌入聚合来的,它们在本质上具有相同的语义空间。这个可以通过利用user-item交互数据增强group-item交互函数的训练,反之亦然。
c. 模型优化
从排名的角度来处理推荐任务,选择成对学习的方法来优化模型参数,pairwise学习的假设是:观察到的交互要比未观察到的有更高的预测分数。
用户推荐损失:采用基于回归的pairwise损失:
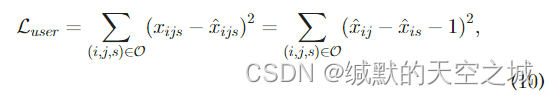
三元组
(
i
,
j
,
s
)
(i,j,s)
(i,j,s)表示用户
u
i
u_i
ui交互过项目
v
j
v_j
vj,没有交互过
v
s
v_s
vs,
x
^
i
j
s
=
x
^
i
j
−
x
^
i
s
\hat{x}_{ijs}=\hat{x}_{ij}-\hat{x}_{is}
x^ijs=x^ij−x^is为观察到的交互
(
u
i
,
v
j
)
(u_i,v_j)
(ui,vj)和未观察到的交互
(
u
i
,
v
s
)
(u_i,v_s)
(ui,vs)的预测边缘,由于我们关注的是隐式反馈,其中每个观察到的交互作用值为1,而未观察到的交互作用值为0,
x
i
j
s
=
x
i
j
−
x
i
s
=
1
x_{ijs}=x_{ij}-x_{is}=1
xijs=xij−xis=1。
对于组推荐任务:
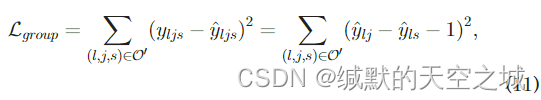
(
l
,
j
,
s
)
(l,j,s)
(l,j,s)表示组
g
l
g_l
gl交互过item
v
j
v_j
vj但是没有交互过
v
s
v_s
vs。
简单来说:
(1)利用自注意机制作为group成员聚合策略执行group推荐。使group成员对群体贡献不同,group成员的注意力权值是在群里与不同项目互动时动态调整的。
(2)通过另一个注意网络将社交followee信息纳入用户表征学习中。group级和user级注意力网络通过层次结构连接,有助于加强groups和users表征学习。
(3)group-item和user-item交互都嵌入到神经协同过滤框架中,可以相互增强group-item和user-item推荐性能。
4. What are the conclusions?
- 在这项工作中,我们从神经表征学习的角度来解决群体推荐问题。在该框架下,有两个关键因素可以评价一个群体对一个项目的偏好: 1)如何获得一个群体的语义表示,2)如何建模一个群体和一个项目之间的互动。我们提出了一个新的解决方案AGREE,通过注意力网络解决了组表示学习首要因素,通过NCF解决了交互学习的第二个因素。
通过利用注意力网络,AGREE 可以从数据中自动学习群组成员的重要性; 通过利用 NCF,它能够学习群组、用户和项目之间复杂的交互。此外,社会followee流动信息进一步纳入框架工作,并被称为 SoAGREE。在 SoAGREE 中,followee的注意力被视为用户的属性,通过另一个注意力网络聚合,动态调整用户注意力的权重。此后,我们将用户-项交互数据的建模集成到 AGREE 中,从而允许组和用户推荐项这两个任务相互加强。
结果表明,AGREE 和 SoAGREE 在群体决策中取得了最佳的性能。
5. others
- 组推荐
基于内存的方法可以进一步细分为偏好聚合[16]和分数聚合[17]。偏好聚合策略首先将群体成员的个人信息聚合为一个新的个人信息中,然后采用针对个人的推荐技术进行群体推荐。分数聚合策略首先预测个体在候选项目上的得分,然后通过预先设定的策略(如平均、最小痛苦、最大满意度等)聚合群体中成员的预测得分来表示群体的偏好。然而,这两种方法都是预定义的,不灵活,它们利用琐碎的方法来聚合模型的偏好。
不同于基于内存的方法,基于模型的方法通过模拟组的生成过程来利用成员之间的交互。我们的工作属于基于模型的范畴。除了学习深度学习框架下用户、组和项目之间的高层次互动外,我们的工作还采用注意力机制作为用户嵌入表示聚合的基本原则。同时,在该框架下,用户推荐和群组推荐相互增强。 - The least misery strategy [1] tries to please all members in a group by choosing the lowest preference score among its members over an item. The maximum satisfaction strategy [5] tries to maximize the greatest preference of a group, and it averages the preference scores of members above a certain threshold. The expertise strategy [28] endows an individualized weight for a user based on her expertise on the items
最小痛苦策略[1]试图取悦一个群体中的所有成员,在其成员中选择对一个项目最低的偏好分数。最大满意策略[5]试图最大化一个群体的最大偏好,它平均超过一定阈值的成员的偏好分数。专业知识策略[28]根据用户对项目的专业知识,为其赋予个性化的权重 。 - 看一下代码里面这些是什么?
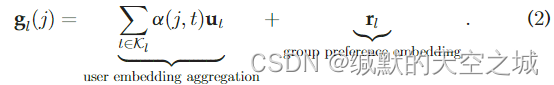
- 问题:
group推荐利用的用户嵌入与user 推荐使用的followee嵌入有什么区别?这些followee是组内还是全局的?一个用户的followee嵌入是如何的定义的?
main.py:获得用户followee
 config.py:
config.py:
说明某个用户的followee与组成员没有关系。
userFollow.txt数据集:131和132表示用户id
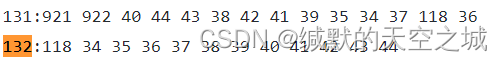
groupMember.txt数据集:131和132表示组的成员

看出用户的followee并不是组内的成员而是全局的。















 2855
2855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









