







Decentralized Collaborative Learning Framework for Next POI Recommendation
标定的(校准的)快速公平联邦推荐系统
1. What does literature study?
- 提出一个经过校准的快速而公平的联邦推荐框架Cali3F,通过集群内参数共享解决了收敛问题,另外使用全局模型校准本地模型提高公平性。
2. What’s the innovation?
1. Past shortcomings && Unsolved problems
- 联邦参与者之间的公平性(跨设备推荐性能的一致性)
- 数据异构和网络限制对收敛的影响
2.Innovation:
- 提出一种个性化联邦推荐算法,使用全局模型参数进行标定,提高推荐性能的公平性。
- 采用基于聚类的聚合方法加快训练。
- 提出的框架提高了预测准确性、收敛速度和通信成本。
3. What was the methodology?

Cali3F框架:基于聚类的客户端采样(Clussamp),校准的本地模型更新(CaliUp)和快速聚合方法(FastAgg)。基本推荐模型选择NCF(低延迟和低成本)。
1.基于聚类的客户端采样(Clussamp)
将客户端分组为P个集群,从每个集群中随机选择一个给定数量的客户端参与训练,所选择的客户端被称为委托客户端,其余的为从属客户端。
2.快速聚合方法(FastAgg)
维护具有类似用户嵌入的客户端集群,并向包含它们的集群的所有其他客户端广播客户端更新。FastAgg结合本地模型来更新共享全局模型,使联邦模型更快地收敛并产生更高质量的推荐。
3.校准的本地模型更新(CaliUp)
Cali3F 的前提是,通过减少对全局模型的依赖,我们可以减少代表性差异,从而促进公平。通过全局模型校准本地模型训练的方法,同时保持与全局模型的差异。
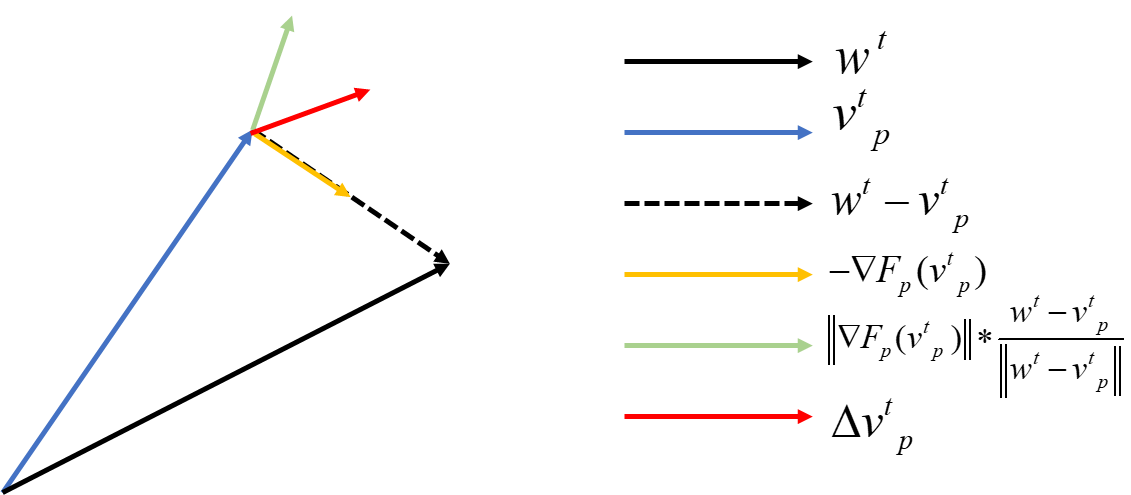
通过每个FL回合,每个集群维护本地模型
v
p
v^p
vp,首先计算
p
p
p的梯度,应用一个额外梯度方向为全局分量和局部分量的差,对局部模型约束,使其不会发散太远。
v
p
t
+
1
←
v
p
t
−
η
(
∇
F
p
(
v
p
t
)
+
φ
∥
∇
F
p
(
v
p
t
)
∥
v
p
t
−
w
t
∥
v
p
t
−
w
t
∥
)
v_p^{t+1} \leftarrow v_p^t-\eta\left(\nabla F_p\left(v_p^t\right)+\varphi\left\|\nabla F_p\left(v_p^t\right)\right\| \frac{v_p^t-w^t}{\left\|v_p^t-w^t\right\|}\right)
vpt+1←vpt−η(∇Fp(vpt)+φ
∇Fp(vpt)
∥vpt−wt∥vpt−wt)
4. What are the conclusions?
-
数据集:
-
评价指标: 使用命中率(HR)和标准化的累积增益(NDCG)评估推荐的性能。HR计算推荐列表前十名中出现的测试项目的百分比,而NDCG将相关结果除以log2(i + 1),以鼓励测试项目的更高排名。
-
实验对比:与联邦方法相比,我们的 Cali3F 始终优于 FedAvg 基线。个性化可以有效地提高推荐的公平性。
-
总结:Cali3F在保持快速收敛速度的同时提高联邦客户端推荐性能公平性,将神经网络集成到联邦协同过滤推荐框架,采用 MTL (多任务学习)通过一个自适应 L2规范正则化项同时训练局部和全局模型。采用委托抽样策略和基于用户配置相似性的块更新组件,加快分布式训练的速度。
5. others
- 《Calibrated Recommendations》
https://dl.acm.org/doi/pdf/10.1145/3240323.3240372
https://github.com/tanmay17061/cf_project
推荐系统公平性之校准化推荐–calibrated recommendations_cqu_shuai的博客-CSDN博客
深入理解推荐系统:Fairness、Bias和Debias - 多任务学习(MTL)包括硬参数共享和加权组合方法,
本文所说的多任务是不是就是全局任务和局部任务?
多任务学习旨在用其他相关任务提升主要任务的泛化性能。简单来说多任务学习是一种集成学习方法(ensemble approach),通过对几个任务同时训练而使得多个任务之间相互影响。这种影响会一起反映到共享参数上,当所有任务收敛的时候,这个结构就相当于融合了所有任务。 - NCF将模型分为三个部分:用户嵌入组件,项目嵌入组件,非嵌入组件。
Update of non-embedding component (CaliUp). - 定义的"公平":两个模型的NDCG在K个客户端上(归一化折现累积增益)方差越小越稳定,表示模型越公平。使用标准差来表征公平程度。标准偏差越大表明客户端模型之间的性能差距较大且不太公平。
- 使用 K-均值聚类方法将用户重新聚类为 P 个聚类,共享同一集群的客户机平均他们的非嵌入组件参数以创建一个表示集群的新本地模型。
- 将 Cali3F 与另一种方法 Ditto 进行了比较,后者使用局部和全局模型参数差的 l2范数作为约束项来训练局部模型,但在正则化项的固定系数上与我们的方法有所不同。















 177
177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









