







本文为深度之眼pytorch训练营二期学习笔记,详细课程内容移步:深度之眼 https://ai.deepshare.net/index
目录
计算图
通过计算图的示意,我们很容易的可以理解模型参数训练的过程,这个过程很像模型的前向传播和方向传播。
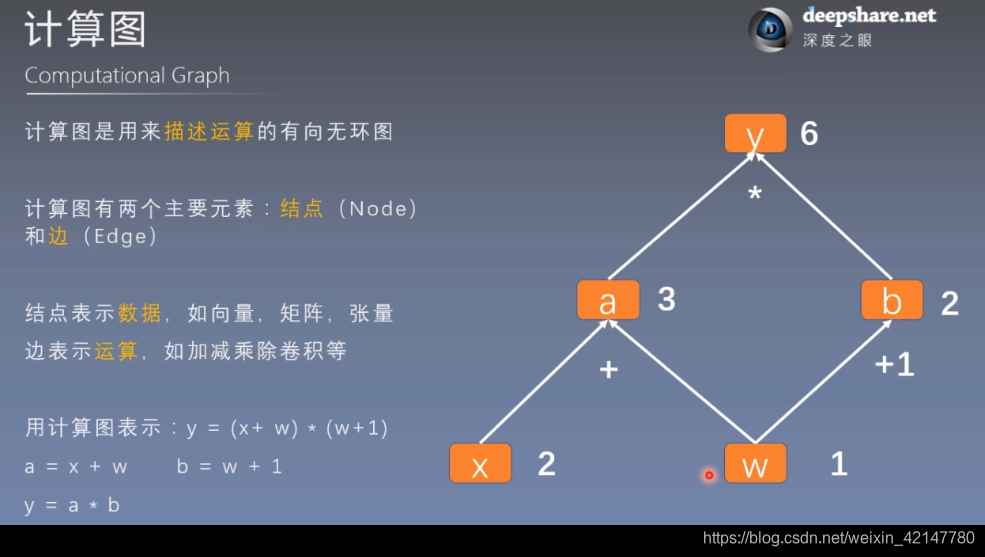
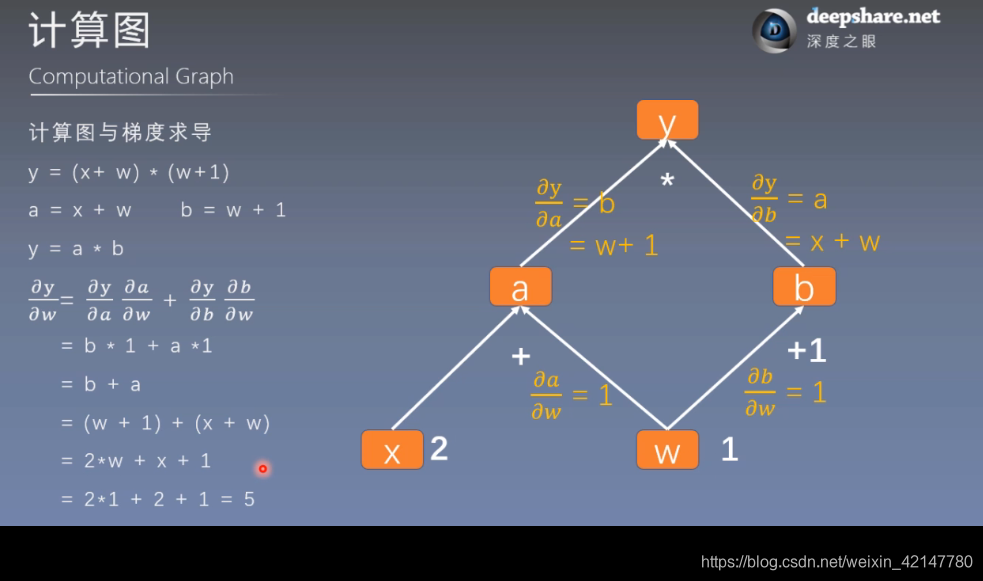

叶子节点很重要,非叶子节点的梯度在计算后会被释放,以优化内存开销,当然可以使用retain_grad()保存


线性回归实现

实现一:根据计算图的方式
import torch
import matplotlib.pyplot as plt
torch.manual_seed(10)
lr = 0.1 # 学习率
# 创建训练数据 x,y=2x+5 (加了随机噪声torch.randn)
x = torch.rand(20, 1) * 10 # x data (tensor), shape=(20, 1)
y = 2*x + (5 + torch.randn(20, 1)*0.5) # y data (tensor), shape=(20, 1)
# 构建线性回归参数
w = torch.randn((1), requires_grad=True)
b = torch.zeros((1), requires_grad=True)
for iteration in range(1000):
# 前向传播
wx = torch.mul(w, x)
y_pred = torch.add(wx, b)
# 计算 MSE loss
loss = (0.5 * (y - y_pred) ** 2).mean()
# 反向传播
loss.backward()
# 更新参数:原地操作,减去学习率乘以梯度
b.data.sub_(lr * b.grad)
w.data.sub_(lr * w.grad)
#梯度清零
w.grad.zero()
b.grad_zero()
# 绘图
if iteration % 20 == 0:
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), y_pred.data.numpy(), 'r-', lw=5)
plt.text(2, 20, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
plt.xlim(1.5, 10)
plt.ylim(8, 28)
plt.title("Iteration: {}\nw: {} b: {}".format(iteration, w.data.numpy(), b.data.numpy()))
plt.pause(0.5)
#停止条件
if loss.data.numpy() < 0.7:
break
实现二:nn.Linear()的范式
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# 超参数设置
input_size = 1
output_size = 1
num_epochs = 60
learning_rate = 0.001
# 数据
x_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167], [7.042],
[10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221], [2.827],
[3.465], [1.65], [2.904], [1.3]], dtype=np.float32)
# 线性回归模型实例化
model = nn.Linear(input_size, output_size)
# MSE损失函数 和 随机梯度下降算法
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# 训练模型
for epoch in range(num_epochs):
# 把数据转成tensor类型的
inputs = torch.from_numpy(x_train)
targets = torch.from_numpy(y_train)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, targets)
# 方向传播可优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 5 == 0:
print ('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))
# 画图
predicted = model(torch.from_numpy(x_train)).detach().numpy()
plt.plot(x_train, y_train, 'ro', label='Original data')
plt.plot(x_train, predicted, label='Fitted line')
plt.legend()
plt.show()
=============================推荐资源
深度之眼pytorch训练营















 2039
2039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









