







文章目录
- 前言
- 第一课:论文导读
- 第二课 论文精读
- 论文整体框架
- 经典算法模型
- 论文提出改进后的模型
- 实验和结果
- 讨论和总结
- 参考文章
- 作业:
- 第三课 论文复现
前言
本课程来自深度之眼deepshare.net,部分截图来自课程视频。
文章标题:Transformer: attention is all you need
原标题翻译:变形金刚,你只需要注意力
基于深度学习的序列模型(基于Pytorch实现)
作者:Ashish Vaswani等
单位:Google
发表会议及时间:NIPS2017
在线LaTeX公式编辑器
这篇文章是业界第一篇基于自注意力机制的模型
感谢提Eclick•洛风供参考文章:https://blog.csdn.net/qq_41664845/article/details/84969266
第一课:论文导读
a. 序列问题
自然语言处理的输入输出基本上都是序列,序列问题是自然语言处理最本质的问题,甚至一些计算机视觉问题也是序列问题,包括金融上的一些问题,交通流上的一些问题等等。序列问题非常的宽泛,掌握nlp序列问题的学习不仅仅帮助我们能快速地切入到其他更具体场景的nlp应用,也能帮助我们更好地迁移到其他应用领域的问题上。
b. seq2seq的基本框架
seq2seq是序列问题中一个非常重要的模型,很多的序列问题都可以用seq2seq来解决,比如说机器翻译、语音转文字、图像标注、文本总结等等。seq2seq基本框架还适用于图像压缩,超分辨率等计算机视觉的问题。掌握seq2seq的基本框架是学习这篇论文的基础。
c. 经典的seq2seq模型
了解当前的seq2seq模型的主要流派,了解他们提出的动机,模型的优缺点,更好地引出本篇论文,也帮助我们更好地学习论文。
序列模型简介
序列问题
Speech Recognition

Machine Translation

Sentiment Classification

Video Activity Recognition

Summarization, Question Answering, Image Captioning,………
序列模型
序列模型:就是输入输出均为序列数据的模型,序列模型将输入序列数据转换为目标序列数据。下面的分类NG的深度学习课程里面也有介绍。
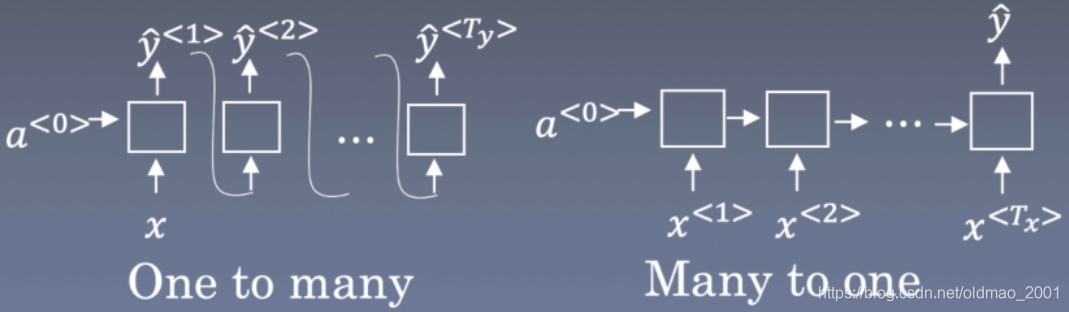
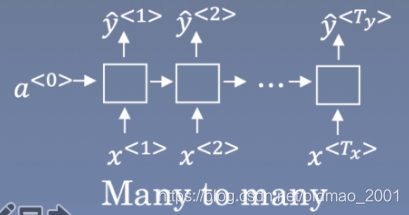
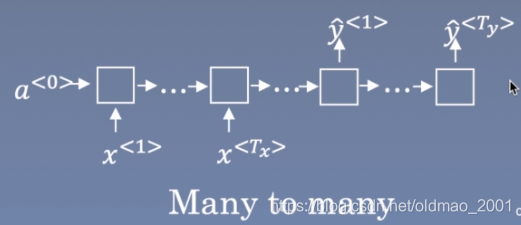
多到多的序列转换模型Sequence To Sequence Models
这篇文章主要研究的就是上面的最后一种情况。
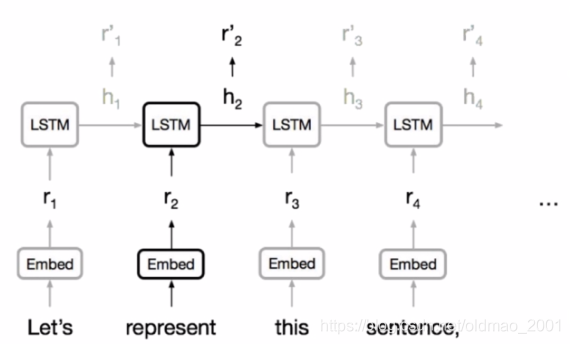
一种是基于RNN的
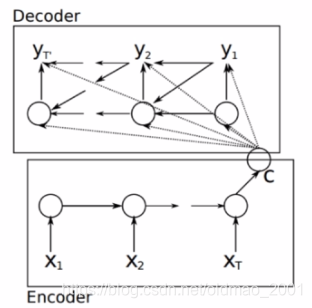
其实在上一篇带读paper中有讲过,来自:Learning phrase representations using RNN encoder-decoder for statistical machine translation, Cho et al.
大概就是通过encoder对源语言(输入)进行编码得到fixed length的上下文向量(content vector)c,然后在从c恢复出要翻译的目标语言(输出)。
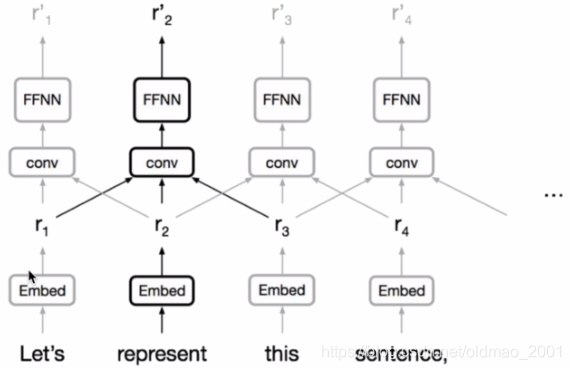
还有基于CNN的:
来自:Neural machine translation in linear time, Kalchbrenner et al.
RNN在处理序列问题时有如下好处和特点:
Model of choice for learning variable-length representations(可处理变长句子)
Natural fit for sentences of pixels(可按单词为单位进行处理)
LSTMs GRUs and variants dominate recurrent models(常用模型有两种)
下图是LSTM处理英文输入的一个例子:
RNN缺点:
Sequential computationsinhibits parallelization(无法并行计算)
No explicit modeling of long and short range dependencies(对于长短期的记忆没有明显的表征建模,我理解应该是有定性无定量的意思吧)
We want to model hierarchy(我理解:模型不是层次的,而是摊开的)
Transmitting local and global information through one bottleneck[hidden state](所有的输入信息都是压缩在了上下文向量c中)
CNN的优点
Trivial to parallelize(per layer)(非常适合并行化处理)
Exploits local dependencies(很好的捕捉到局部依赖,我理解:卷积操作就是一个个step挪动的,每个细节都会cover到)
'interaction distance’between positions linear or logarithmic
Long-distance dependencies require many layers(例如下图中的例子,每个卷积只会捕捉到3个词的信息,如果词相隔较远,则需要在后面的conv层才能捕捉到它们的相关信息)
Notable Work:·Neural GPU·ByteNet·ConvS2S(常见的基于CNN的机器翻译模型)
带有注意力的循环神经网络RNNs With Attention
Removes bottleneck of Encoder-Decoder Model
Provides context for given decoder step
案例分析Case Study
·Machine Translation
The animal didn’t cross the street because it was too tired.
The animal didn’t cross the street because it was too wide.
上面两句话中的it分别指animal和street(由加黑部分的两个形容词决定),如果用RNN,就直接把句子压缩为一个向量了,没有办法强调it是dependent on 后面的形容词,也就没法还原it指的是什么,如果用CNN,虽然可以找到词和词之间的依赖关系(it和形容词),但是无法将it和animal和street关系起来,它们之间距离太大了。
带有注意力机制的翻译模型就可以解决上面提到的问题。
I arrived at the bank after crossing the river.
I arrived at the bank after crossing the street.
分析:翻译时关键的信息词与当前翻译的词之间的距离,距离越长依赖信息越难学到。
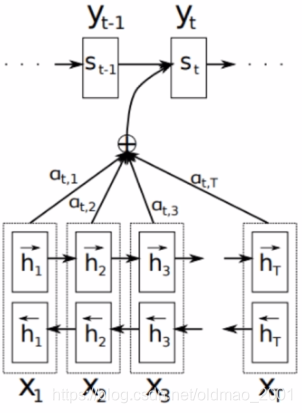
自注意力序列模型相关技术
注意力机制
这部分相当于复习了,上篇文章有相关内容
1.Encode所有输入序列,得到对应的representation
h
1
h
2
h
3
.
…
…
h
T
h_1 h_2 h_3.……h_T
h1h2h3.……hT(T为输入序列的长度)
2.Decode输出目标
y
t
y_t
yt之前,会将上一步输出的隐藏状态
S
t
−
1
S_{t-1}
St−1与之前encode好的representation进行对比,计算相似度(
e
t
,
j
=
a
(
s
t
−
1
,
h
j
)
e_{t,j}=a(s_{t-1},h_j)
et,j=a(st−1,hj),
h
j
h_j
hj为之前第j个输入字符encode得到的隐藏向量,a为任意一种计算相似度的方式)
3.然后再通过softmax,
a
t
,
j
=
e
x
p
(
e
t
,
j
)
∑
k
=
1
T
x
e
x
p
(
e
t
,
k
)
a_{t,j}=\frac{exp(e_{t,j})}{\sum_{k=1}^{T_x}exp(e_{t,k})}
at,j=∑k=1Txexp(et,k)exp(et,j)将之前得到的各个部分的相关系数进行归一化,得到
a
t
,
1
a
t
,
2
a
t
,
3
.
.
.
.
.
.
a
t
,
T
a_{t,1} a_{t,2} a_{t,3} ......a_{t,T}
at,1at,2at,3......at,Ta
4.再对输入序列的隐藏层进行相关性加权求和得到此时decode需要的context vector
c
j
=
∑
j
=
1
T
x
a
i
,
j
h
j
c_j=\sum_{j=1}^{T_x}a_{i,j}h_j
cj=∑j=1Txai,jhj
既能并行计算又能缩短距离
答案就是完全自注意力模型
前期知识储备
CNN
了解卷积神经网络(CNN)的结构,掌握CNN的基本工作原理
RNN
了解循环神经网络(RNN)的结构,掌握RNN的基本工作原理
注意力机制
了解注意力机制的思想,掌握注意力机制的实现方式
Seq2Seq
了解序列转换模型的输入输出,基本的编码解码组成结构
第二课 论文精读
论文整体框架
■Abstract
■Introduction
■Background
■Model Architecture(比较短,最好能手推一遍)
■Why Self-Attention(一般论文没有这一节)
■Training(复现时重点看)
■Results(复现时重点看)
■Conclusion
■References
■Appendix
阅读方法:
1.快速了解文章大意
·Abstract
·Model Architecture
2.复现论文
·Abstract
·Model Architecture
3.分析
·Why Self-Attention
·Appendix
4.背景学习
·Introduction
·Background
经典算法模型
循环卷积神经网络Recurrent Neural Networks
Original Sequence Prediction
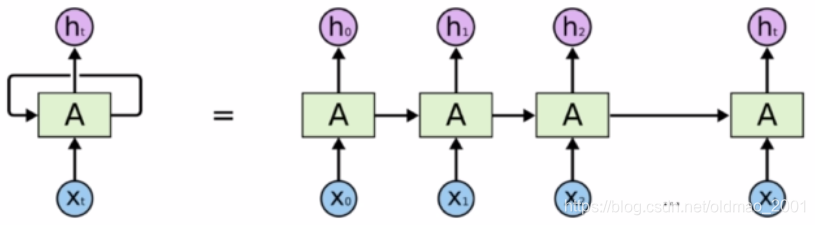
h
<
t
>
=
f
(
h
<
t
−
1
>
,
x
t
)
h_{<t>}=f(h_{<t-1>,x_t})
h<t>=f(h<t−1>,xt)
p
(
x
t
,
j
=
1
∣
x
t
−
1
,
.
.
.
,
x
1
)
=
e
x
p
(
w
j
h
<
t
>
)
∑
j
′
=
1
K
e
x
p
(
w
j
′
h
<
t
>
)
)
p(x_{t,j}=1|x_{t-1},...,x_1)=\frac{exp(w_jh_{<t>})}{\sum_{j'=1}^Kexp(w_{j'}h_{<t>}))}
p(xt,j=1∣xt−1,...,x1)=∑j′=1Kexp(wj′h<t>))exp(wjh<t>)
p
(
X
)
=
∏
t
=
1
T
p
(
x
t
∣
x
t
−
1
,
.
.
.
,
x
1
)
p(X)=\prod_{t=1}^Tp(x_t|x_{t-1},...,x_1)
p(X)=t=1∏Tp(xt∣xt−1,...,x1)
Encoder-Decoder
Learning phrase representations using RNN encoder-decoder for statistical machine translation, Cho et al. 2014
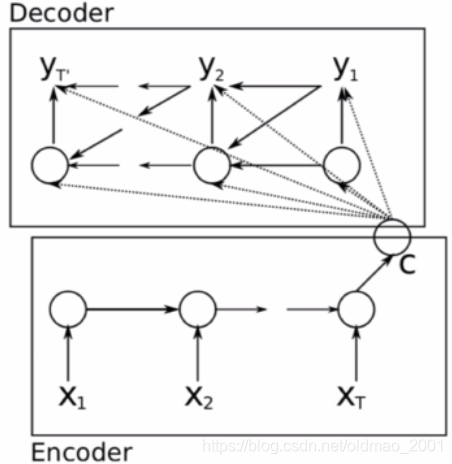
h
<
t
>
=
f
(
h
<
t
−
1
>
,
y
t
−
1
,
c
)
h_{<t>}=f(h_{<t-1>},y_{t-1},c)
h<t>=f(h<t−1>,yt−1,c)
p
(
y
t
∣
y
t
−
1
,
y
t
−
2
,
.
.
.
,
y
1
,
c
)
=
g
(
h
<
t
>
,
y
t
−
1
,
c
)
p(y_{t}|y_{t-1},y_{t-2},...,y_1,c)=g(h_{<t>},y_{t-1},c)
p(yt∣yt−1,yt−2,...,y1,c)=g(h<t>,yt−1,c)
m
a
x
θ
1
N
∑
n
=
1
N
l
o
g
p
θ
(
y
n
∣
x
n
)
\underset{\theta}{max}\frac{1}{N}\sum_{n=1}^Nlogp_\theta (y_n|x_n)
θmaxN1n=1∑Nlogpθ(yn∣xn)
带有注意力的循环卷积网络Recurrent Neural Networks with attention mechanisms
·Use “query” vector(decoder state)and “key” vectors(all encoder states)
·For each query-key pair,calculate weight
·Normalize to add to one using softmax
例如下图,query vector是检索向量,例子中为hate这个词,在预测翻译hate对应的词的时候,从目标语言字典中计算相似度a1,a2,。。。然后通过softmax层进行归一化得到相应权重α1,α2.。。。
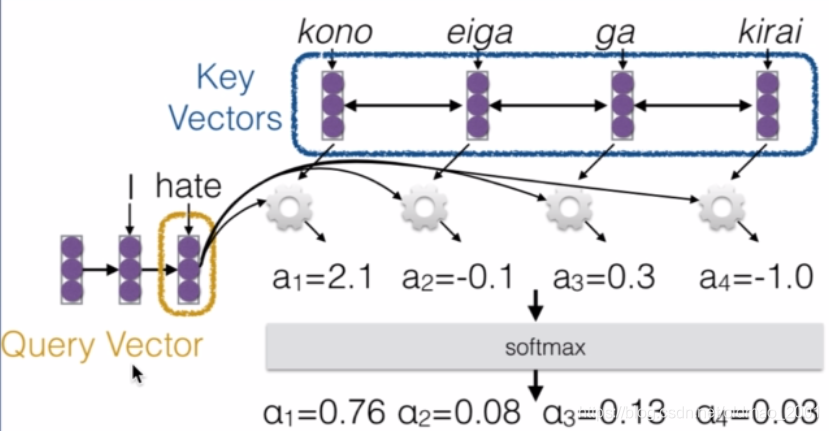
·Combine together value vectors(usually encoder states,like key vectors)by taking the weighted sum
·Use this in any part of the model you like
然后把权重和vector相乘求和
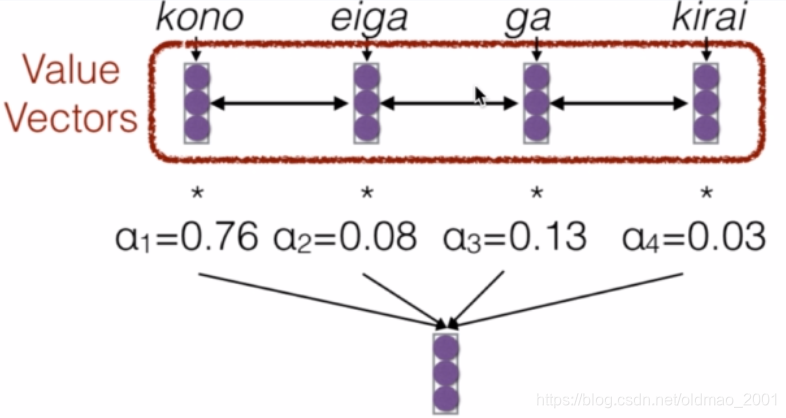
注意力权重函数
计算相似度所用函数有下面几种:
q is the query and k is the key
1.Multi-layer Perceptron(Bahdanau et al.2015)多层感知机
a
(
q
,
k
)
=
w
2
T
t
a
n
h
(
W
1
[
q
;
k
]
)
a(q,k)=w_2^Ttanh(W_1[q;k])
a(q,k)=w2Ttanh(W1[q;k])
· Flexible, often very good with large data
2.Bilinear(Luong et al.2015)双线性模型
a
(
q
,
k
)
=
q
T
W
k
a(q,k)=q^TWk
a(q,k)=qTWk
3. Dot Product(Luong et al.2015)点乘模型
a
(
q
,
k
)
=
q
T
k
a(q,k)=q^Tk
a(q,k)=qTk
· No parameters! But requires sizes to be the same.
4. Scaled Dot Product(Vaswani et al.2017)放缩点乘模型
· Problem: scale of dot product increases as dimensions get larger
· Fix: scale by size of the vector
a
(
q
,
k
)
=
q
T
k
∣
k
∣
a(q,k)=\frac{q^Tk}{\sqrt{|k|}}
a(q,k)=∣k∣qTk
卷积神经网络Convolutional Neural Networks
·Encoder-Decoder Stacking
·Dynamic Unfolding(解决编码和解码的长度问题)
∣
t
^
∣
=
a
∣
s
∣
+
b
|\widehat t|=a|s|+b
∣t
∣=a∣s∣+b
·Input Embedding Tensor
·Masked One-dimensional Convolutions
·Dilation(类似ngram跳字作用)
·Residual Blocks
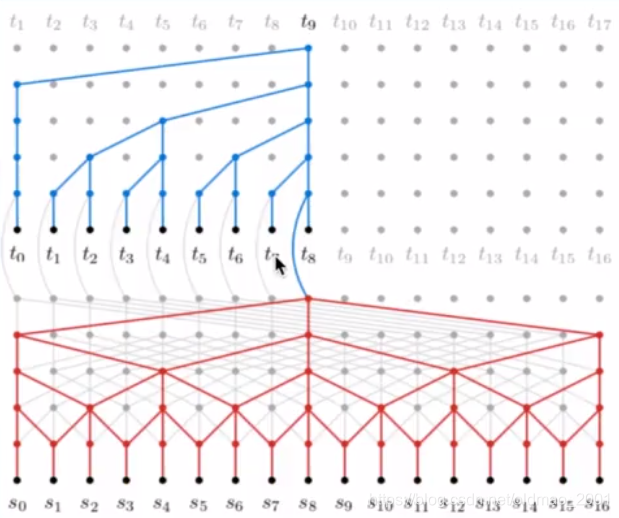
Neural machine translation in linear time, Kalchbrenner et al.
论文提出改进后的模型
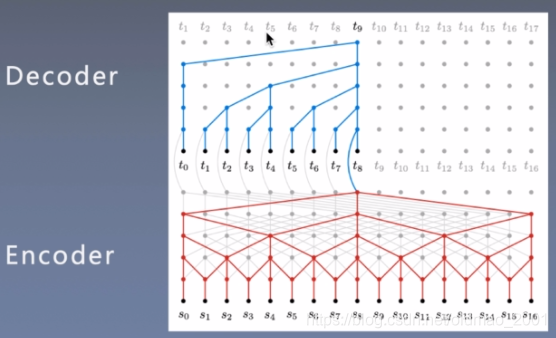
编解码框架Encoder and decoder stacks
·Left:Encoder
·Right:Decoder
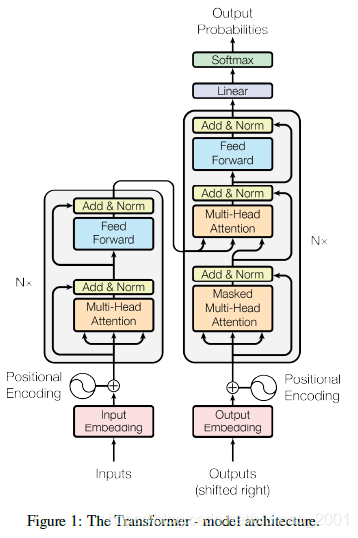
编码器Encoder:6 identical layers
论文中说编码器是有六层,图中只画了1层,就是Nx那里
每层结构如下:
·Layer:
1.multi-head self-attention
2.fully connected feed-forward network
·Residual Connection:残差连接就是图中黄色框框
·LayerNorm
(
x
+
S
u
b
l
a
y
e
r
(
x
)
)
(x+Sublayer(x))
(x+Sublayer(x))
·
D
m
o
d
e
l
=
512
D_{model}=512
Dmodel=512
解码器Decoder:6 identical layers
解码器也是6层,但是每一层由三个部分构成
·Layer:
1.masked multi-head self-attention
2.multi-head self-attention
3.fully connected feed-forward network
·Residual Connection:
·LayerNorm(x+Sublayer(x))
·Dmodel=512
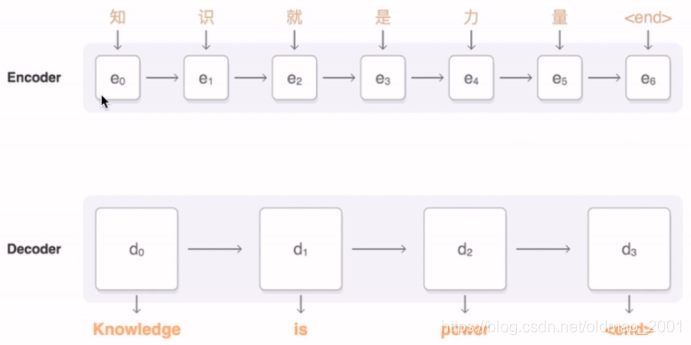
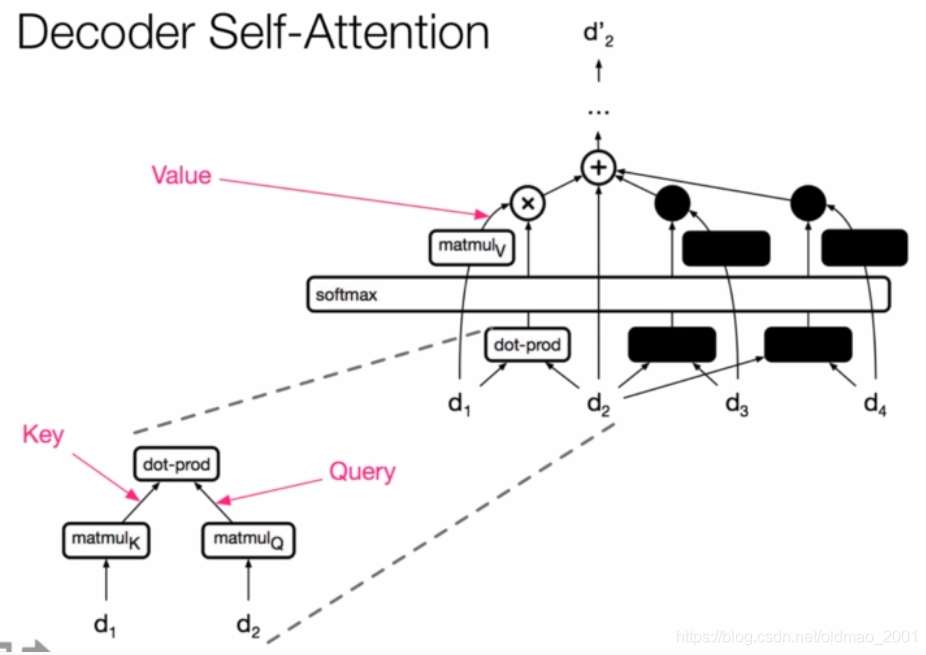
编解码器的区别——遮挡
·Encode whole sequence编码是针对整个句子
·Decode character by character解码只能一个词一个词的来弄,没有翻译的部分相当于遮挡了的。
1.I love China------
2.I love China-------我
3.Ilove China--------我爱
4.I love China-------我爱中国
自注意力网络
这个图老师也没解释太多,貌似论文上也没有,应该是整个模型的结构吧。
前馈网络Feed-Forward Network
这一节本来是放后面的,但是考虑到是在描述整个模型的框架,这节描述的是框架中的蓝色框框部分,就放这里了。
increase non-linear property
F
F
N
(
x
)
=
m
a
x
(
0
,
x
W
1
+
b
1
)
W
2
+
b
2
FFN(x)=max(0,xW_1+b_1)W_2+b_2
FFN(x)=max(0,xW1+b1)W2+b2
位置嵌入Position Embedding
位置嵌入在模型中像太极球的那里。。。
在注意力机制中,无论使用RNN还是CNN都是不需要考虑词的位置的,例如CNN是靠卷积核的移动来扫描。在自注意力机制里面就需要自己来标注词的位置(位置信息很重要,不然你咋知道如何表示A和B的关系),标注的方法就是位置嵌入(以上是自己的理解,估计有偏差。)
·Positional encoding provides relative or absolute position of given token
·Many options to select positional encoding,in this work:
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
1000
0
2
i
/
d
m
o
d
e
l
)
PE_{(pos,2i)}=sin(\frac{pos}{10000^{2i/d_{model}}})
PE(pos,2i)=sin(100002i/dmodelpos)
P
E
(
p
o
s
,
2
i
+
1
)
=
c
o
s
(
p
o
s
1000
0
2
i
/
d
m
o
d
e
l
)
PE_{(pos,2i+1)}=cos(\frac{pos}{10000^{2i/d_{model}}})
PE(pos,2i+1)=cos(100002i/dmodelpos)
i是维度,词在不同维度的时候,sin或者cos的周期不一样,体现出词位置的唯一性。
为什么要残差连接
残差网络在CNN中是防止梯度弥散的,从而达到更加多的层的效果。
而残差在自注意力机制中传递的是位置信息。
Residuals carry positional information to higher layers, among other information.

放缩后的点乘注意力Scaled Dot-product Attention
这篇文章中注意力机制中计算注意力权重函数用的是:Scaled Dot-product Attention
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt {d_k}})
Attention(Q,K,V)=softmax(dkQKT)
其中d是确定的值
整体结构如下图
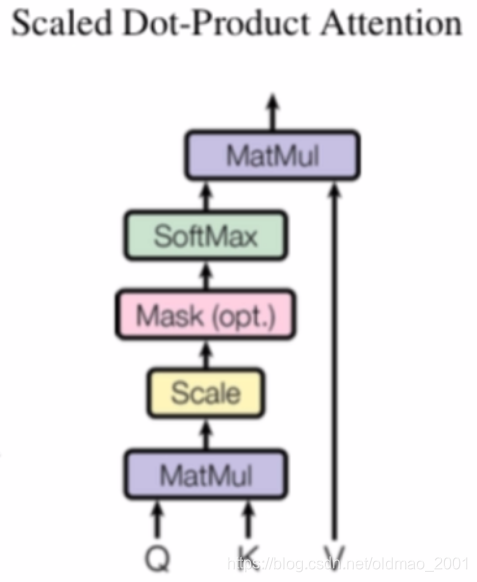
具体的计算都是可以转化为矩阵运算,计算速度很快。
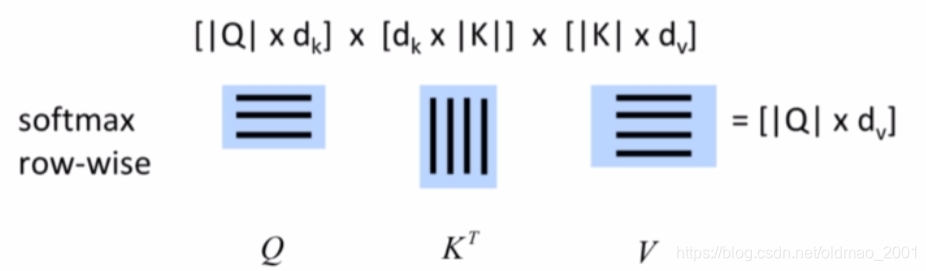
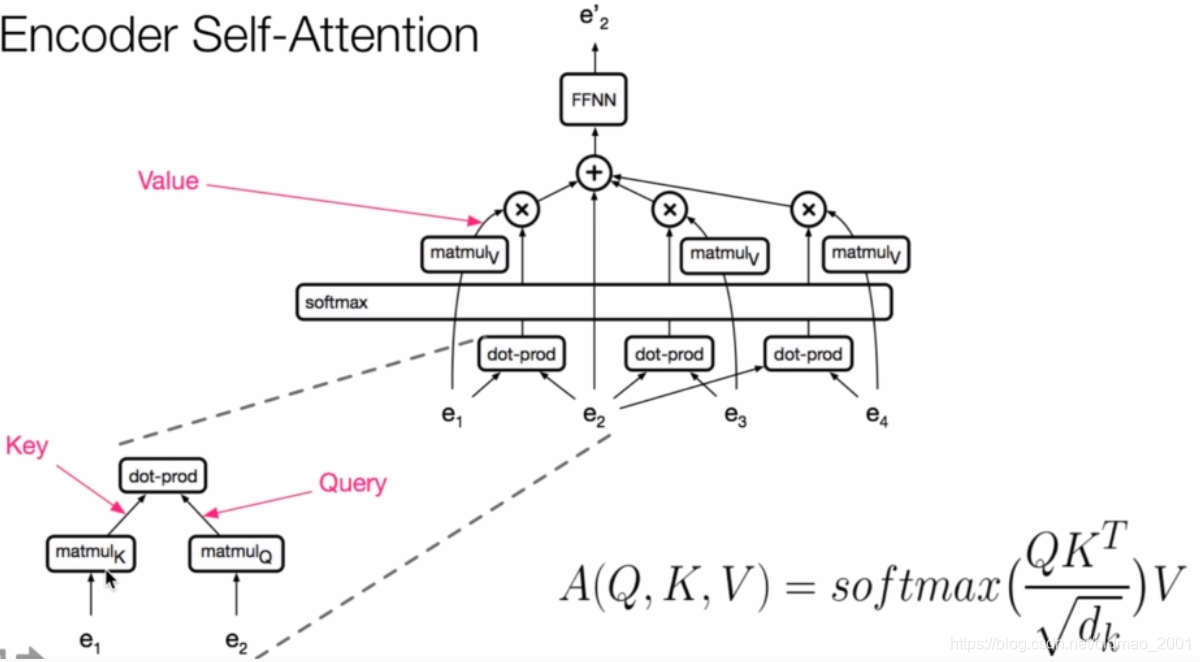
解码部分有遮挡
自注意力机制与卷积网络的对比comparison between Self-Attention and Convolution
Self-Attention:variable-sized perceptive field自注意力机制的视野是不一样的,可以看得更广,范围可以自己设置。
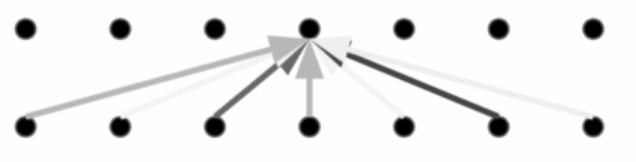
Convolution:local dependency,卷积受制于卷积的大小(即使可以设置大小也不能太大,不然就失去卷积的意义了),学习到的依赖关系是有限的,只能学到局部的依赖
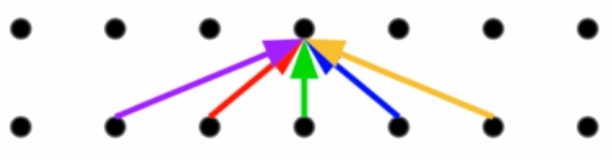
Question:How to convey multi-channel information?
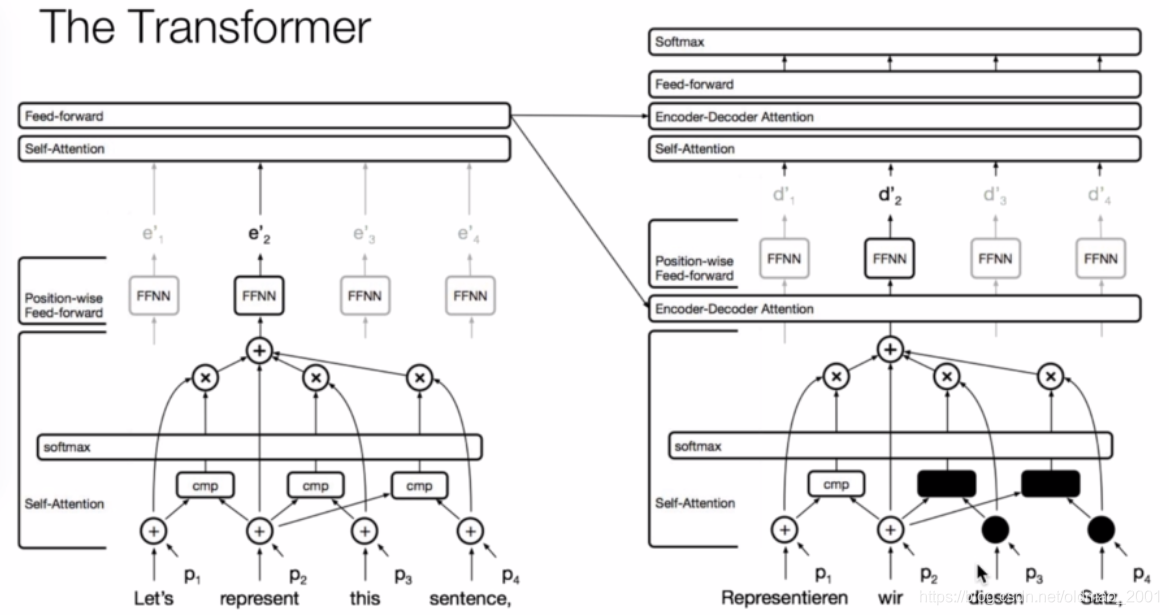
在CNN中,进行图像识别的时候,是可以一次读取到目标的多个特征的,例如一个卷积核是检测人的耳朵,有的检测眼睛,类似这样的,翻译的时候也一样(下图右边可以一次捕获到句子中的主谓宾分别是I,kicked,ball),也可以同时获取到多处或多个信息。但是只注意力机制能否有类似的功能?答案是有,就是文章中提到的并行的注意力头

并行的注意力头parallel attention heads
为了实现像CNN一样能够一次获取多处信息,自注意力机制设置了多个并行的注意力头,每个头负责不同信息的捕获,例如一个头负责主语,一个负责谓语,一个负责宾语,下面的图有点乱,我也没看清哪个对哪个。。。

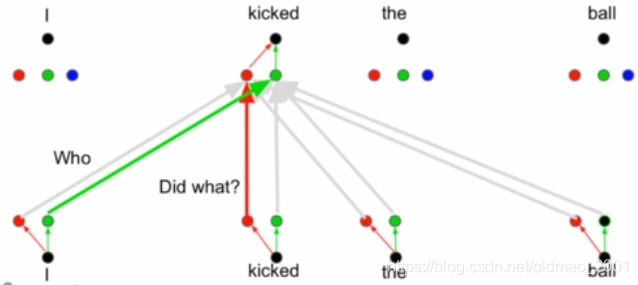
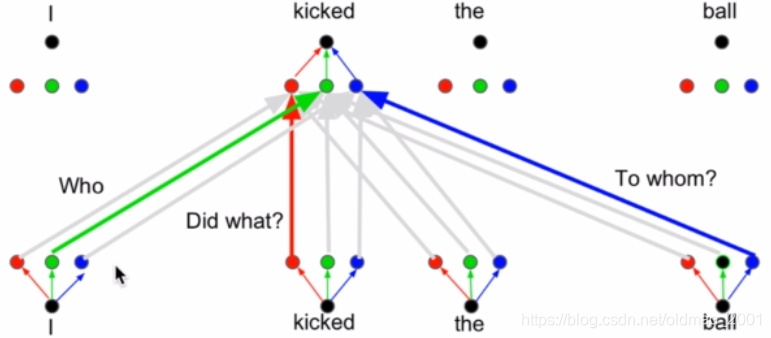
多头注意力的实现
VKQ前面加了不同的线性映射,就是下面公式里面的W矩阵,可以让自注意力机制能够模仿CNN的多通道的这种关系。
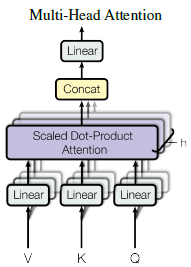
M
u
l
t
i
H
e
a
d
(
Q
,
K
,
V
)
=
C
o
n
c
a
t
(
h
e
a
d
1
,
.
.
.
,
d
e
a
d
h
)
W
O
MultiHead(Q,K,V)=Concat(head_1,...,dead_h)W^O
MultiHead(Q,K,V)=Concat(head1,...,deadh)WO
w
h
e
r
e
h
e
a
d
i
=
A
t
t
e
n
t
i
o
n
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
where head_i=Attention(QW_i^Q,KW_i^K,VW_i^V)
whereheadi=Attention(QWiQ,KWiK,VWiV)
W
i
Q
∈
ℜ
d
m
o
d
e
l
×
d
k
W_i^Q\in\real^{d_{model}\times d_k}
WiQ∈ℜdmodel×dk
W
i
K
∈
ℜ
d
m
o
d
e
l
×
d
k
W_i^K\in\real^{d_{model}\times d_k}
WiK∈ℜdmodel×dk
W
i
V
∈
ℜ
d
m
o
d
e
l
×
d
v
W_i^V\in\real^{d_{model}\times d_v}
WiV∈ℜdmodel×dv
W
O
∈
ℜ
h
d
v
×
d
m
o
d
e
l
W^O\in\real^{hd_v\times d_{model} }
WO∈ℜhdv×dmodel
d
k
=
d
v
=
d
m
o
d
e
l
h
=
64
d_k=d_v=\frac{d_{model}}{h}=64
dk=dv=hdmodel=64
注意力的可视化Attention Visualizations
不同的颜色代表不同的头,横的一行行的代表不同的channel,颜色的深浅代表相关性。
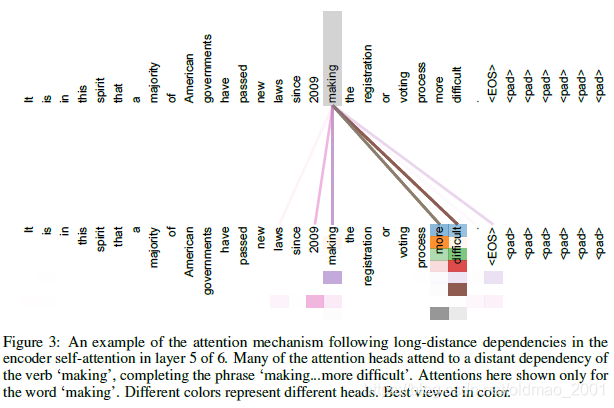
下面是代词指代信息的例子,its对应两个词
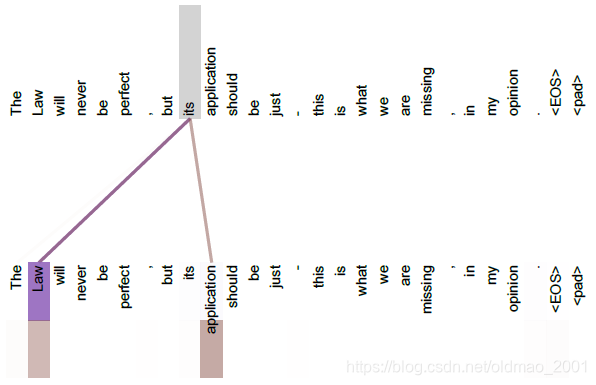
单头分析句子结构的可视化例子:
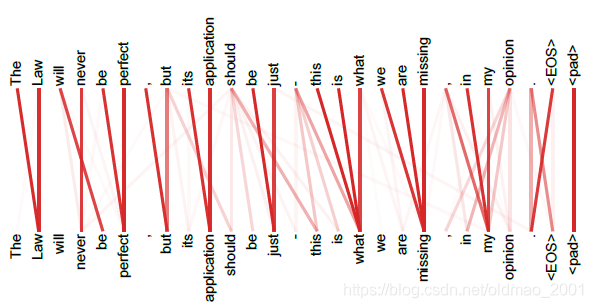
自注意力机制与注意力机制的区别The difference between Self-Attention and Attention
注意力机制:
h
i
=
a
t
t
e
n
t
i
o
n
(
(
K
,
V
)
,
q
i
)
=
∑
j
=
1
N
α
i
j
v
j
=
∑
j
=
1
N
s
o
f
t
m
a
x
(
s
(
k
j
,
q
i
)
)
v
j
h_i=attention((K,V),q_i)=\sum_{j=1}^N\alpha_{ij}v_j=\sum_{j=1}^Nsoftmax(s(k_j,q_i))v_j
hi=attention((K,V),qi)=j=1∑Nαijvj=j=1∑Nsoftmax(s(kj,qi))vj
编码中的:K是key,V是value,
q
i
q_i
qi是解码中的query向量,attention是求二者的相似度,然后加权求和。
自注意力机制:
H
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
H=softmax(\frac{QK^T}{\sqrt{d_k}})V
H=softmax(dkQKT)V
attention中的query是来自外部序列,Self-Attention的query来自于原本的序列
为什么选择自注意力机制
论文里面有这么一个小节,用来王婆卖瓜,实际上从时间复杂度、序列并行操作上可以看出来为什么:

最后一个是限制了范围的自注意力机制
训练
- ADAM optimizer with a learning rate warmup(warmup+exponential decay)
- Dropout during training at every layer just before adding residual
- Layer-Normalization(help ensure that layers remain in reasonable range)
- Attention dropout(for some experiments)
- Checkpoint-averaging
- Label smoothing(insert some uncertainty in the training process)
- Auto-regressive decoding with beam search and length biasing
实验和结果
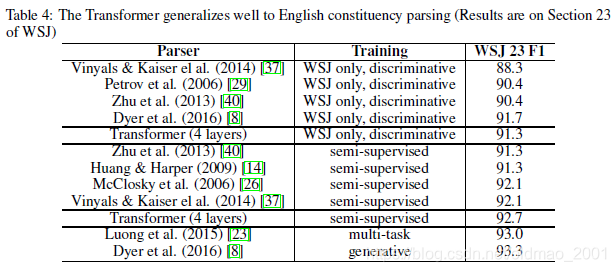
结果results
1.Machine translation
2.Model variations
3.English constituency parsing
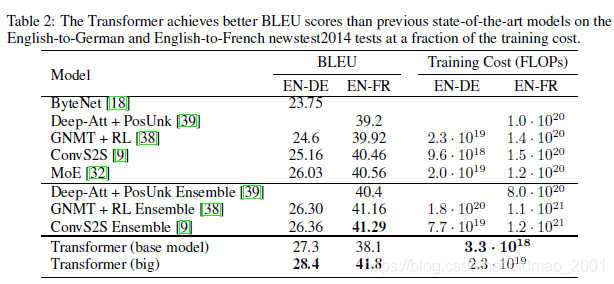
消融研究Ablation Studies
分ABCD…组,每个组切换不同参数,查看模型效果,弄明白模型的使用场景,例如A组中变化的是h(头数)
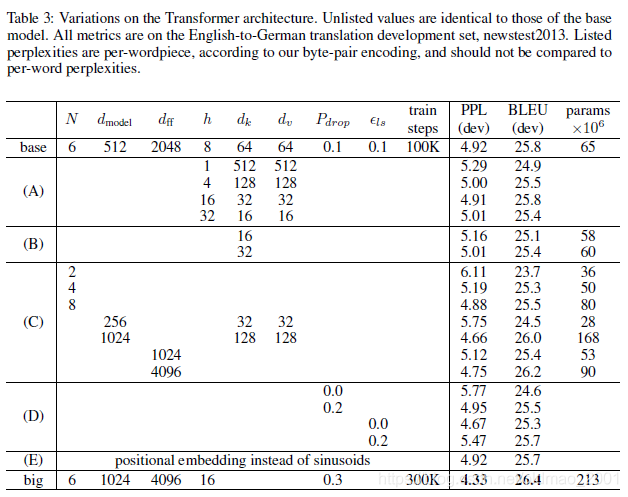
英语句法分析English Constituency Parsing
模型的泛化能力不错,用于句法分析也取得不错的成绩。
讨论和总结
| 问题 | 解决 |
|---|---|
| 如何实现并行计算同时缩短依赖距离 | 采用自注意力机制 |
| 如何像CNN一样考虑到多通道信息 | 采用多头注意力 |
| 自注意力机制损失了位置信息,如何补偿 | 位置嵌入 |
| 后面的层中位置信息消散 | 残差连接 |
创新点(都在摘要中)
新的序列模型:完全基于注意力
在标准的WMT翻译数据集上达到了state-of-the-art的结果
模型很快:并行的矩阵乘法
参考文章
[1]http://web.stanford.edu/class/cs224n/slides/cs224n-2019-lecture14-transformers.pdf cs224n中请的论文一作来讲的ppt
[2]http://nlp.seas.harvard.edu/2018/04/03/attention.html(复现需要看这个博客)
[3]http://ialammar.github.io/illustrated-transformer/
[4]https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
[5]https://mchromiak.github.io/articles/2017/Sep/12/Transformer-Attention-is-all-you-need/#.XLQ355MzaFO
[6]https://medium.com/@kolloldas/building-the-mighty-transformer-for-secuence-tagging-in-pytorch-part-i-a1815655cd8
[7I https://phontron.com/class/nn4nlp2017/
作业:
a. 自注意力与注意力的区别?
b. 为什么要进行残差连接?
c. 为什么要设置多头注意力 ?
d. 一个自注意力层计算的复杂度是多少,为什么?
e. 为什么要进行mask?
f. 位置嵌入除了文中的这种形式还有哪些?
第三课 论文复现
具体的不记了,反正还没时间复现,把几个要点mark一下
在编码器中用到了6个相同的层,在pytorch中可以用如下代码复制6个层,且不共享参数
nn. ModuleList([copy. deepcopy(module) for _in range(N)])
层的normalization

残差连接



















 1422
1422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











