







热数据缓存
这是使用缓存最频繁最直接的方式,即我们把需要频繁访问DB的数据加载到内存里面,以提高响应速度。通常我们的做法是使用一个ConcuccrentHashMap来记录一天当中每个请求的次数,每天凌晨取出昨天访问最频繁的K个请求(K取多少个取决你的可用内存有多少),从DB中读取这些请求的返回结果放到一个ConcuccrentHashMap容器中,然后把所有请求计数清0,重新开始计数。
LRU缓存
热数据缓存适用于那些热数据比较明显且稳定的业务场景,而对于那些热数据不稳定的应用场景我们需要发明一种动态的热数据识别方式。我们都知道常用的内存换页算法有2种:LFU和LRU。
LFU(Least Frequently Used)是把那些最近最不经常使用的页面置换出去,这跟上面讲的热数据缓存是一个道理,缺点有2个:
需要维护一个计数器,记住每个页面的使用次数。
上一个时间段频繁使用的,在下一个时间段不一定还频繁。
LRU(Least Recently Used)策略是把最近最长时间未使用的页面置换出去。实现起来很简单,只需要一个链表结构,每次访问一个元素时把它移到链表的尾部,当链表已满需要删除元素时就删除头部的元素,因为头部的元素就是最近最长时间未使用的元素。


1 importjava.util.ArrayList;2 importjava.util.Collection;3 importjava.util.LinkedHashMap;4 importjava.util.Map;5 importjava.util.concurrent.locks.ReadWriteLock;6 importjava.util.concurrent.locks.ReentrantReadWriteLock;7
8 /**
9 * 利用LinkedHashMap实现一个定长容量的,先进先出的队列。当指定按访问顺序排序时,就实际上是一个最近最少使用LRU队列
10 *
11 * 根据链表中元素的顺序可以分为:按插入顺序的链表,和按访问顺序(调用get方法)的链表。
12 * 默认是按插入顺序排序,如果指定按访问顺序排序,那么调用get方法后,会将这次访问的元素移至链表尾部。
13 * 不断访问可以形成按访问顺序排序的链表。
14 * 可以重写removeEldestEntry方法返回true值指定插入元素时移除最老的元素。
15 *16 * @Author:zhangchaoyang17 * @Since:2014-9-518 * @Version:1.019 */
20 public class LRUCache extends LinkedHashMap{21
22 private static final long serialVersionUID = -2045058079564141163L;23
24 private final intmaxCapacity;25
26 //本类中设置装载因子实际没有意义,因为容量超过maxCapacity时就会把元素移除掉
27 private static final float DEFAULT_LOAD_FACTOR =1f;28
29 private final ReadWriteLock lock = newReentrantReadWriteLock();30
31 public LRUCache(intmaxCapacity) {32 super(maxCapacity, DEFAULT_LOAD_FACTOR, true);//第3个参数false表示维持插入顺序,这样最早插入的将最先被移除。true表示维持访问顺序,调用get方法后,会将这次访问的元素移至链表尾部,删除老元素时会删除表头元素。
33 this.maxCapacity =maxCapacity;34 }35
36 @Override37 protected boolean removeEldestEntry(java.util.Map.Entryeldest) {38 return size() > maxCapacity;//到达maxCapacity时就移除老元素,这样实现定长的LinkedHashMap
39 }40
41 @Override42 public booleancontainsKey(Object key) {43 try{44 lock.readLock().lock();45 return super.containsKey(key);46 } finally{47 lock.readLock().unlock();48 }49 }50
51 @Override52 publicV get(Object key) {53 try{54 lock.readLock().lock();55 return super.get(key);56 } finally{57 lock.readLock().unlock();58 }59 }60
61 @Override62 publicV put(K key, V value) {63 try{64 lock.writeLock().lock();65 return super.put(key, value);66 } finally{67 lock.writeLock().unlock();68 }69 }70
71 public intsize() {72 try{73 lock.readLock().lock();74 return super.size();75 } finally{76 lock.readLock().unlock();77 }78 }79
80 public voidclear() {81 try{82 lock.writeLock().lock();83 super.clear();84 } finally{85 lock.writeLock().unlock();86 }87 }88
89 public Collection>getAll() {90 try{91 lock.readLock().lock();92 return new ArrayList>(super.entrySet());93 } finally{94 lock.readLock().unlock();95 }96 }97 }
View Code
TimeOut缓存
Timeout缓存常用于那些跟用户关联的请求数据,比如用户在翻页查看一个列表数据时,他第一次看N页的数据时,服务器是从DB中读取的相应数据,当他看第N+1页的数据时应该把第N页的数据放入缓存,因为用户可能呆会儿还会回过头来看第N页的数据,这时候服务器就可以直接从缓存中获取数据。如果用户在5分钟内还没有回过头来看第N页的数据,那么我们认为他再看第N页的概率就非常低了,此时可以把第N页的数据从缓存中移除,实际上相当于我们为缓存设置了一个超时时间。
我想了一种Timeout缓存的实现方法。还是用ConcurrentHashMap来存放key-value,另建一棵小顶堆,每个节点上存放key以及key的到期时间,建堆时依据到期时间来建。开一个后台线程不停地扫描堆顶元素,拿当前的时间戳去跟堆顶的到期时间比较,如果当前时间晚于堆顶的到期时间则删除堆顶,把堆顶里存放的key从ConcurrentHashMap中删除。删除堆顶的时间复杂度为$O(log_2{N})$,具体步骤如下:
用末元素替换堆顶元素root
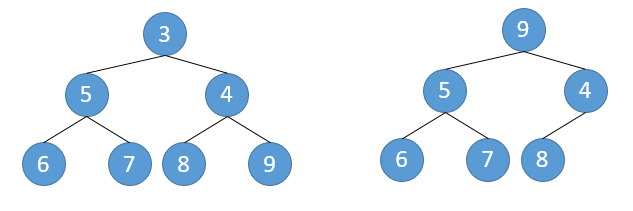
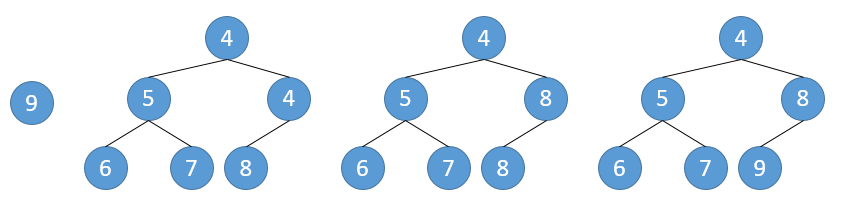
临时保存root节点。从上往下遍历树,用子节点中较小那个替换父节点。最后把root放到叶节点上
下面的代码是直接基于java中的java.util.concurrent.Delayed实现的,Delayed是不是基于上面的小顶堆的思想我也没去深入研究。
TimeoutCache.java
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8535
8535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









