






 文章目录导入各种包,设置基本参数import transformersfrom transformers import BertModel, BertTokenizer, AdamW, get_linear_schedule_with_warmupimport torchimport numpy as npimport pandas as pdimport seaborn as snsfrom pylab import rcParamsimport matplotlib.pyplot as
文章目录导入各种包,设置基本参数import transformersfrom transformers import BertModel, BertTokenizer, AdamW, get_linear_schedule_with_warmupimport torchimport numpy as npimport pandas as pdimport seaborn as snsfrom pylab import rcParamsimport matplotlib.pyplot as
文章目录
https://curiousily.com/posts/sentiment-analysis-with-bert-and-hugging-face-using-pytorch-and-python/
导入各种包,设置基本参数
import transformers
from transformers import BertModel, BertTokenizer, AdamW, get_linear_schedule_with_warmup
import torch
import numpy as np
import pandas as pd
import seaborn as sns
from pylab import rcParams
import matplotlib.pyplot as plt
from matplotlib import rc
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
from collections import defaultdict
from textwrap import wrap
from torch import nn, optim
from torch.utils.data import Dataset, DataLoader
%matplotlib inline
%config InlineBackend.figure_format='retina'
sns.set(style='whitegrid', palette='muted', font_scale=1.2)
HAPPY_COLORS_PALETTE = ["#01BEFE", "#FFDD00", "#FF7D00", "#FF006D", "#ADFF02", "#8F00FF"]
sns.set_palette(sns.color_palette(HAPPY_COLORS_PALETTE))
rcParams['figure.figsize'] = 12, 8
RANDOM_SEED = 42
np.random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
使用的是Google Play 的评论数据,用下面的程序,从谷歌drive上下载数据集
import gdown
url1 = "https://drive.google.com/uc?id=1S6qMioqPJjyBLpLVz4gmRTnJHnjitnuV"
url2 = 'https://drive.google.com/uc?id=1zdmewp7ayS4js4VtrJEHzAheSW-5NBZv'
gdown.download(url1) #'apps.csv'
gdown.download(url2) #'reviews.csv'
读取数据
df = pd.read_csv("reviews.csv")
df.head()
有这些类:
list(df.columns)
['userName',
'userImage',
'content',
'score',
'thumbsUpCount',
'reviewCreatedVersion',
'at',
'replyContent',
'repliedAt',
'sortOrder',
'appId']
最主要的还是content和score,分别是评论的内容和打分(1-5分)
查看数据形状
df.shape
(15746, 11)
查看缺失值情况
df.info()
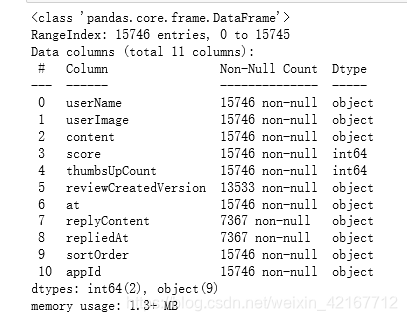
可以看到content和score没有缺失值,其他的并不影响
查看各个打分的分布情况
sns.countplot(df['score'])
plt.xlabel('review score')
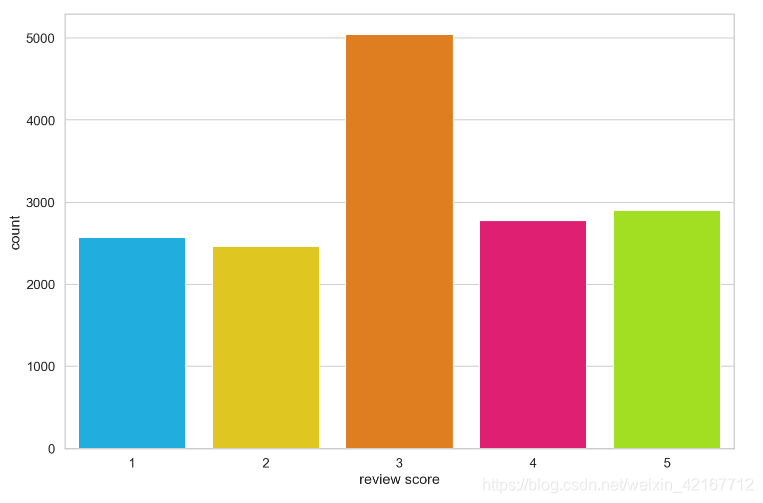
相当不平衡,所以考虑将其转化为negative,neutral,positive类,进行情感分析
将socre 转化为0,1,2
def to_sentiment(rating):
rating = int(rating)
if rating <= 2:
return 0 # 负面
elif rating == 3:
return 1 #中立
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









