









对源代码中TF2已经移除的方法作了替换
1、embedding 函数
- word embedding:从数据中自动学习到输入空间到Distributed representation空间的映射,降低训练所需要的数据量
- tf.compat.v1.variable_scope:A context manager for defining ops that creates variables (layers)
- look_table:查找表,相当于字典的作用
- tf.compat.v1.get_variable:Gets an existing variable with these parameters or create a new one.
- initializer=tf.initializers.GlorotUniform:“Xavier”初始化方法是一种很有效的神经网络初始化方法,方法来源于2010年的一篇论文《Understanding the difficulty of training deep feedforward neural networks》
- tf.nn.embedding_lookup(lookup_table, inputs):在lookup_table中查找下标为inputs的元素
- tf.compat.v1.disable_v2_behavior():这个函数可以在程序开始时调用(在创建张量、图形或其他结构之前,以及在初始化设备之前)。它将所有在tensorflow1和2之间不同的全局行为切换为预期为1的行为。
def embedding(inputs,
vocab_size,
num_units,
zero_pad=True,
scale=True,
scope="embedding",
reuse=None):
with tf.compat.v1.variable_scope(scope, reuse=reuse):
# 构件查找表
lookup_table = tf.compat.v1.get_variable(name='lookup_table',
dtype=tf.float32,
shape=[vocab_size, num_units],
initializer=tf.initializers.GlorotUniform())
if zero_pad:
# 将lootup_table中第一个张量替换为全0张量
# 张量拼接
lookup_table = tf.concat((tf.zeros(shape=[1, num_units]),
lookup_table[1:, :]), 0) #(拼接对象,维度)
outputs = tf.nn.embedding_lookup(lookup_table, inputs)
# 选取一个张量(lookup_table)里面索引对应的元素(inputs)
if scale:
outputs = outputs * (num_units ** 0.5)
return outputs
def main():
inputs = tf.dtypes.cast(tf.reshape(tf.range(2 * 3), (2, 3)), tf.int32)
# 数据类型转换
outputs = embedding(inputs, 6, 2, zero_pad=True)
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
if __name__ == '__main__':
main()输出示例:
inputs:
[[0 1 2]
[3 4 5]]
outputs:
[[[ 0. 0. ]
[-0.6018285 0.36682096]
[-1.1781635 -0.9732541 ]]
[[-1.0972805 0.67716676]
[-0.09731749 -0.4502349 ]
[-0.88273793 -0.16005561]]]2、position encoding
- 由于我们的模型不包含递归和卷积,为了使模型能够利用序列的顺序,我们必须注入一些关于序列中标记的相对或绝对位置的信息。为此,我们将“位置编码”添加到编码器和解码器堆栈底部的输入嵌入中。位置编码具有与嵌入相同的维度dmodel,因此这两个维度可以相加。--《attention is all you need》
- tf.tile(input, multiples, name=None):通过复制扩展张量,multiple表示对应维度复制的倍数。详解:https://blog.csdn.net/tsyccnh/article/details/82459859
- tf.expand_dims(input, dim, name=None):在dim的位置增加一维
def positional_encoding(inputs, num_units, zero_pad = True, scale = True, scope = "positional_encoding", reuse=None): N,T = inputs.get_shape().as_list() with tf.compat.v1.variable_scope(scope, reuse=reuse): # scope = "positional_encoding" position_ind = tf.tile(tf.expand_dims(tf.range(T), 0), [N, 1]) position_enc = np.array([ [pos / np.power(10000, 2.*i / num_units) for i in range(num_units)] # pos代表的是第几个词,i代表embedding中的第几维 for pos in range(T)]) position_enc[:, 0::2] = np.sin(position_enc[:, 0::2]) # dim 2i 递增 position_enc[:, 1::2] = np.cos(position_enc[:, 1::2]) # dim 2i+1 递减 print('position_enc:\n', position_enc) lookup_table = tf.convert_to_tensor(position_enc) if zero_pad: t1 = tf.cast(tf.zeros(shape=[1, num_units]),dtype=tf.float64) # lookup_table数据类型为float64 lookup_table = tf.concat((t1, lookup_table[1:, :]), 0) outputs = tf.nn.embedding_lookup(lookup_table, position_ind) if scale: outputs = outputs * num_units ** 0.5 return outputs输出示例:
-
未经过zero_padding和scale的position_encoding
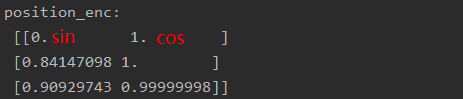
-
inputs: [[0 1 2] [3 4 5]] outputs: [[[0. 0. ] [1.19001968 1.41421356] [1.28594075 1.41421353]] [[0. 0. ] [1.19001968 1.41421356] [1.28594075 1.41421353]]]3、multihead_attention
- Q、K、V含义:Q表示当前要翻译的单词(向量),K表示句子中的所有单词,通过一系列计算得到每个K对应的V表示K与V的相关程度。关于attention的原理这篇文章解释的很好:https://baijiahao.baidu.com/s?id=1622064575970777188&wfr=spider&for=pc;Q、K的输入为embedding后的句子,维度为三
-
tf.transpose(a, perm):对张量按照perm的顺序重排
-
tf.sign(x):返回一个数字符号的元素指示。如果x < 0,则有 y = sign(x) = -1;如果x == 0,则有 0 或者tf.is_nan(x);如果x > 0,则有1。对于NaN输入返回零。对于复杂的数字,如果x != 0,则有y = sign(x) = x / |x|,否则y = 0。
-
对Padding部分进行掩码:
# 这里是对填充的部分进行一个mask,这些位置的attention score变为极小,我们的embedding操作中是有一个padding操作的,
# 填充的部分其embedding都是0,加起来也是0,我们就会填充一个很小的数。
key_masks = tf.sign(tf.abs(tf.reduce_sum(keys,axis=-1))) #全为0的行被标记,二维
key_masks = tf.tile(key_masks,[num_heads,1]) #扩大回512
key_masks = tf.tile(tf.expand_dims(key_masks,1),[1,tf.shape(queries)[1],1])
paddings = tf.ones_like(outputs) * (-2 ** 32 + 1)
outputs = tf.where(tf.equal(key_masks,0),paddings,outputs) # 8*10*10- Mask掩码:在decoder的输入部分(Q=K=dec)使用
#tril = tf.contrib.linalg.LinearOperatorTriL(diag_vals).to_dense()
tril = tf.linalg.LinearOperatorLowerTriangular(diag_vals).to_dense() #10*10下三角为1,上三角为0[[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[1. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[1. 1. 1. 0. 0. 0. 0. 0. 0. 0.]
[1. 1. 1. 1. 0. 0. 0. 0. 0. 0.]
[1. 1. 1. 1. 1. 0. 0. 0. 0. 0.]
[1. 1. 1. 1. 1. 1. 0. 0. 0. 0.]
[1. 1. 1. 1. 1. 1. 1. 0. 0. 0.]
[1. 1. 1. 1. 1. 1. 1. 1. 0. 0.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 0.]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]]最后呢,有一个之前不太清楚的问题:attention学习的参数到底有哪些?除了其他网络层,计算K、Q、V其实分别是queries,key,key,与系数矩阵相乘得到的,也属于训练参数。
4、Normalize
- tf.nn.moments(x, axes, name=None, keep_dims=False):求x在指定维度(axes)上的均值和方差














 3627
3627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









