




 本文介绍了如何基于tensorflow2实现Transformer模型,并应用于多变量风电功率负荷预测。与传统的LSTM相比,Transformer在精度上有优势,但需要更多数据和更高的GPU资源。作者通过去除Transformer的解码器,直接使用编码器输出作为特征,然后通过全连接层预测功率值。实验中,Transformer在处理大量数据时遇到内存问题,需要分批输入。
本文介绍了如何基于tensorflow2实现Transformer模型,并应用于多变量风电功率负荷预测。与传统的LSTM相比,Transformer在精度上有优势,但需要更多数据和更高的GPU资源。作者通过去除Transformer的解码器,直接使用编码器输出作为特征,然后通过全连接层预测功率值。实验中,Transformer在处理大量数据时遇到内存问题,需要分批输入。
本博客来源于CSDN机器鱼,未同意任何人转载。
更多内容,欢迎点击本专栏,查看更多内容。
为啥无法添加目录???
0 引言
Transformer目前大火,作为一个合格的算法搬运工自然要跟上潮流,本文基于tensorflow2.6.1深度学习框架构建transformer模型,并将其用于多变量的风电功率负荷预测。实验结果表明,相比与传统的LSTM,该方法精度更高,缺点也很明显,该方法需要更多的数据训练效果才能超过传统方法,而且占用很高的gpu资源(我的3060笔记本显卡,在推理测试阶段,一次性输入所有测试集数据直接会OOM,需要分批输入),如果采用cpu就更慢了。

接着进入正题
1 Transformer网络结构
原始的transformer网络是用来的处理文本翻译这样的任务,输入=输出(输出是另一种形式的输入),是先编码再解码的结构,首先数据进入编码器,得到隐含特征kv,然后利用解码器输入q,将其还原成另外一种表达。由于翻译任务是不定长的输入,因此采用了解码器循环预测,具体预测过程是:首先输入起始符<s>,对编码器的特征进行查询,输出预测的第一个值y1;第二步输入<s> y1,对编码器的特征进行查询,输出预测的第二个值y2;第三步输入<s> y1 y2,对编码器的特征进行查询,输出预测的第三个值y3,当查询不到特征时,输出结束符</s>,得到完整输出,即<s> y1 y2 ...yn </s>。而我这博客的进行风电功率预测,其负荷预测的输入和输出的长度是固定的,所以我在网络中去掉了解码器,直接将编码器的输出作为提取的特征,然后接一个全连接层作为输出层来预测功率值。
1.1 输入输出层
本文采用的数据形式如图1所示,数据含有6个特征,采用滚动序列建模的方法,生成输入数据与输出数据。具体为:设定输入时间步m与输出时间步n,然后取第1到m时刻的所有数据作为输入,取第m+1到第m+n时刻的实际发电功率作为输出,作为第一个样本;然后取第2到m+1时刻的所有数据作为输入,取第m+2到第m+n+1时刻的实际发电功率作为输出,作为第二个样本。。。依次类推,通过这种滚动的方法获得输入输出数据。举个例子,当m取10,n取3时,则输入层的维度为[None,10,6],输出层的维度为[None,3],模型训练好后,只需要输入过去10个时刻的所有数据,就能预测得到未来3个时刻的发电功率预测值。我用的数据可以在【这里】下载,名字叫风电数据. xlsx。不要忘记了对数据进行归一化或者标准化操作。
def data_split(data,n,m):
# data: 10000*6
# 前n个样本的所有值为输入,来预测未来m个功率值
in_,out_=[],[]
n_samples=data.shape[0]-n-m
for i in range(n_samples):
in_.append(data[i:i+n,:])
out_.append(data[i+n:i+n+m,-1])
input_data=np.array(in_).reshape(len(in_),-1)
output_data=np.array(out_).reshape(len(out_),-1)
return input_data,output_data
data = pd.read_excel('data.xlsx').iloc[:10000,1:].values.astype(np.float32)
n_steps=100
m=1
input_data,output_data=data_split(data,n_steps,m)
# 数据划分 前70%作为训练集 后30%作为测试集
n=range(input_data.shape[0])
m1=int(0.7*input_data.shape[0])
train_data=input_data[n[0:m1],:]
train_label=output_data[n[0:m1]]
test_data=input_data[n[m1:],:]
test_label=output_data[n[m1:]]
# 归一化
# ss_X=MinMaxScaler().fit(train_data)
# ss_Y=MinMaxScaler().fit(train_label)
ss_X=StandardScaler().fit(train_data)
ss_Y=StandardScaler().fit(train_label)
train_data = ss_X.transform(train_data).reshape(train_data.shape[0],n_steps,-1)
test_data = ss_X.transform(test_data).reshape(test_data.shape[0],n_steps,-1)
train_label = ss_Y.transform(train_label).reshape(train_data.shape[0],-1)
test_label = ss_Y.transform(test_label).reshape(test_data.shape[0],-1)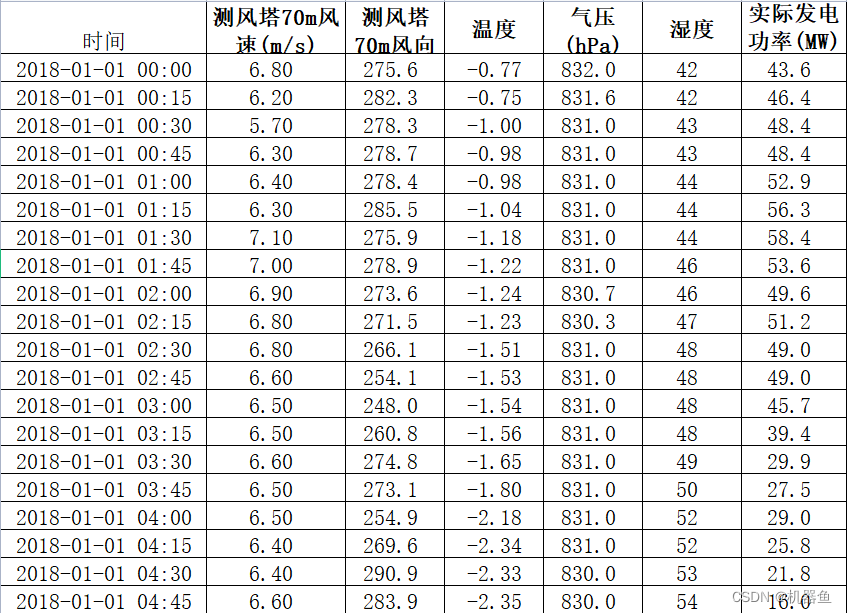
1.2 编码器结构
1.2.1 嵌入层
嵌入层实际上只是一个简单的全连接层,将原本维度变换到d_model,其目的有两个:1)对原始数据进行特征变换,原始只有6个特征,假设这些特征之间是有联系的,采用一个全连接层可以让特征之间进行交互,起到变换特征的作用;2)是增加网络复杂度,为了后续使用多头自注意力机制,多头的数量必须与能被特征整除,打个比方,假如原始的6个特征变换到64个,然后就能用1、2、4、8、16、32、64头数,可选择性较高,如果只是6的话,就只能设置1、2、3,采用更多的头数可以增加网络复杂度,如果风电数据有几万条,网络过于简单无法有效的学习到这么长的序列的特征。
在程序中我将d_model设成16,则经过嵌入层之后的数据为:
d_model=16
embedding = tf.keras.layers.Dense(d_model)
x=np.random.rand(64,10,6)#64是batchsize 10是输入时间步 6是6个特征
y=embedding (x) #y的shape变成 64,10,161.2.2 位置编码
Transformer使用的是正余弦位置编码。位置编码通过使用不同频率的正弦、余弦函数生成,然后和对应的位置的输入向量(嵌入层的输出数据)相加,位置向量维度必须和词向量的维度一致
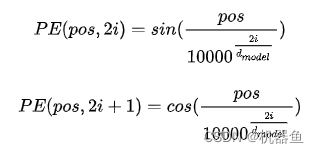
def get_angles(pos, i, d_model):
# 这里的i等价与公式中的2i和2i+1
angle_rates = 1 / np.power(10000, (2 * (i//2)) / np.float32(d_model))
return pos * angle_rates
def positional_encoding(maximum_position_encoding, d_model):
angle_rads = get_angles(np.arange(maximum_position_encoding)[:, np.newaxis], np.arange(d_model)[np.newaxis, :],d_model)
# apply sin to even indices in the array; 2i
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
# apply cos to odd indices in the array; 2i+1
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)
x=np.random.rand(64,10,16)
pos_enc=positional_encoding(5000, 16)
x +=pos_enc[:,x.shape[1],:] #x的shape还是[64,10,16]1.2.3 self-attention自注意力机制
自注意力网络上很多解释,这里我们简单的理解一下计算步骤:通过嵌入层与位置编码后,我们的数据是64 x 10 x 16 其中64表示batchsize ,10表示时间步 ,16为特征维度。如果我们想要获得第i个样本的input-1(每一个样本含10个input,每个input的维度是16)的输出,那么我们进行如下几步:
1、构建3个全连接层,每个维度都是d_model,输入input-1,分别得到3个变量,即Q、K、V,可以将QKV就理解成input-1的另一种表达;
1、利用input-1的Q,分别乘上input-1、input-2、....、input-16的K',此时我们获得了16个score。这个score,这就是相较于input-1、input-2、....、input-16,input-1的重要程度。
这里你会很奇怪为啥score就是input-1相较于其他input的重要程度。我的理解是:Q乘K'是点积。啥时点积?点积就是余弦相似度的分子,QK'近似等于余弦相似度,如果两个变量越相似,QK‘就越大;可推,如果一个变量最重要,那他可以近似代替其他变量,那他与其他变量的点积就会很大。(也可以理解成相关性,一样的推理)
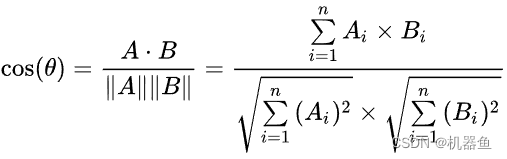
2、然后对这些score取softmax,归一化重要程度。
3、然后将这个重要程度乘上input-1、input-2、....、input-16的值向量,求和。
4、此时我们获得了input-1的输出。
1.2.4 多头注意力
多头注意力,可以理解为我们每个头只计算部分特征,比如第一个头只计算input-1到input-4,第二个头计算input-5到input-8,16个特征就是4个头。
1.2.5 编码器
编码器就是输入经嵌入层+位置编码+多头注意力层+多头注意力层+多头注意力层+...+多头注意力层,得到输出特征,然后输入一个全连接层,就能得到我们的输出
def scaled_dot_product_attention(q, k, v, mask):
"""Calculate the attention weights.
q, k, v must have matching leading dimensions.
k, v must have matching penultimate dimension, i.e.: seq_len_k = seq_len_v.
The mask has different shapes depending on its type(padding or look ahead)
but it must be broadcastable for addition.
Args:
q: query shape == (..., seq_len_q, depth)
k: key shape == (..., seq_len_k, depth)
v: value shape == (..., seq_len_v, depth_v)
mask: Float tensor with shape broadcastable to (..., seq_len_q, seq_len_k). Defaults to None.
Returns:
output, attention_weights
"""
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# scale matmul_qk
dk = tf.cast(tf.shape(k)[-1], tf.float32) ## 64
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# add the mask to the scaled tensor.
if mask is not None:
scaled_attention_logits = scaled_attention_logits + (mask * -1e9)
# softmax is normalized on the last axis (seq_len_k) so that the scores
# add up to 1.
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0# d_model self.num_heads 要能够整除
self.depth = d_model // self.num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
"""Split the last dimension into (num_heads, depth).
Transpose the result such that the shape is (batch_size, num_heads, seq_len, depth)
"""
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k) # (batch_size, seq_len, d_model)
v = self.wv(v) # (batch_size, seq_len, d_model)
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
# scaled_attention.shape == (batch_size, num_heads, seq_len_q, depth)
# attention_weights.shape == (batch_size, num_heads, seq_len_q, seq_len_k)
scaled_attention, attention_weights = scaled_dot_product_attention(q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3]) # (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model)) # (batch_size, seq_len_q, d_model)
output = self.dense(concat_attention) # (batch_size, seq_len_q, d_model)
return output, attention_weights
def point_wise_feed_forward_network(d_model, dff):
return tf.keras.Sequential([
tf.keras.layers.Dense(dff, activation='relu'), # (batch_size, seq_len, dff)
tf.keras.layers.Dense(d_model) # (batch_size, seq_len, d_model)
])
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
attn_output, _ = self.mha(x, x, x, mask) # (batch_size, input_seq_len, d_model)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(x + attn_output) # (batch_size, input_seq_len, d_model)
ffn_output = self.ffn(out1) # (batch_size, input_seq_len, d_model)
ffn_output = self.dropout2(ffn_output, training=training)
out2 = self.layernorm2(out1 + ffn_output) # (batch_size, input_seq_len, d_model)
return out2
class Encoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size,
maximum_position_encoding, rate=0.1):
super(Encoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.embedding = tf.keras.layers.Dense(d_model)
self.pos_encoding = positional_encoding(maximum_position_encoding, self.d_model)
self.enc_layers = [ EncoderLayer(d_model, num_heads, dff, rate) for _ in range(num_layers) ]
self.dropout = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
seq_len = tf.shape(x)[1]
# adding embedding and position encoding.
x = self.embedding(x) # (batch_size, input_seq_len, d_model)
# print('------------------\n',seq_len)
# x=tf.tile(tf.expand_dims(x,2),self.d_model)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
# print(x.shape)
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x, training=training)
# print(x.shape)
# print(mask.shape)
for i in range(self.num_layers):
x = self.enc_layers[i](x, training, mask)
return x # (batch_size, input_seq_len, d_model)
2 完整代码
# -*- coding: utf-8 -*-
#https://blog.csdn.net/qq_31456593/article/details/89923913
# transformer包含编码与解码,我们的模型不含解码部分
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler,StandardScaler
import pandas as pd
from sklearn.metrics import r2_score
import numpy as np
import time
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False
def data_split(data,n,m):
# 前n个样本的所有值为输入,来预测未来m个功率值
in_,out_=[],[]
n_samples=data.shape[0]-n-m
for i in range(n_samples):
in_.append(data[i:i+n,:])
out_.append(data[i+n:i+n+m,-1])
input_data=np.array(in_).reshape(len(in_),-1)
output_data=np.array(out_).reshape(len(out_),-1)
return input_data,output_data
def result(real,pred,name):
# ss_X = MinMaxScaler(feature_range=(-1, 1))
# real = ss_X.fit_transform(real).reshape(-1,)
# pred = ss_X.transform(pred).reshape(-1,)
real=real.reshape(-1,)
pred=pred.reshape(-1,)
# mape
test_mape = np.mean(np.abs((pred - real) / real))
# rmse
test_rmse = np.sqrt(np.mean(np.square(pred - real)))
# mae
test_mae = np.mean(np.abs(pred - real))
# R2
test_r2 = r2_score(real, pred)
print(name,'的mape:%.4f,rmse:%.4f,mae:%.4f,R2:%.4f'%(test_mape ,test_rmse, test_mae, test_r2))
# In[]
def get_angles(pos, i, d_model):
# 这里的i等价与公式中的2i和2i+1
angle_rates = 1 / np.power(10000, (2 * (i//2)) / np.float32(d_model))
return pos * angle_rates
def positional_encoding(maximum_position_encoding, d_model):
angle_rads = get_angles(np.arange(maximum_position_encoding)[:, np.newaxis], np.arange(d_model)[np.newaxis, :],d_model)
# apply sin to even indices in the array; 2i
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
# apply cos to odd indices in the array; 2i+1
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)
def create_padding_mask(seq):
seq = tf.cast(tf.math.equal(seq, 0), tf.float32)
# add extra dimensions to add the padding
# to the attention logits.
return seq[:, tf.newaxis, tf.newaxis, :,0] # (batch_size, 1, 1, seq_len)
def scaled_dot_product_attention(q, k, v, mask):
"""Calculate the attention weights.
q, k, v must have matching leading dimensions.
k, v must have matching penultimate dimension, i.e.: seq_len_k = seq_len_v.
The mask has different shapes depending on its type(padding or look ahead)
but it must be broadcastable for addition.
Args:
q: query shape == (..., seq_len_q, depth)
k: key shape == (..., seq_len_k, depth)
v: value shape == (..., seq_len_v, depth_v)
mask: Float tensor with shape broadcastable to (..., seq_len_q, seq_len_k). Defaults to None.
Returns:
output, attention_weights
"""
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# scale matmul_qk
dk = tf.cast(tf.shape(k)[-1], tf.float32) ## 64
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# add the mask to the scaled tensor.
if mask is not None:
scaled_attention_logits = scaled_attention_logits + (mask * -1e9)
# softmax is normalized on the last axis (seq_len_k) so that the scores
# add up to 1.
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0# d_model self.num_heads 要能够整除
self.depth = d_model // self.num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
"""Split the last dimension into (num_heads, depth).
Transpose the result such that the shape is (batch_size, num_heads, seq_len, depth)
"""
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k) # (batch_size, seq_len, d_model)
v = self.wv(v) # (batch_size, seq_len, d_model)
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
# scaled_attention.shape == (batch_size, num_heads, seq_len_q, depth)
# attention_weights.shape == (batch_size, num_heads, seq_len_q, seq_len_k)
scaled_attention, attention_weights = scaled_dot_product_attention(q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3]) # (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model)) # (batch_size, seq_len_q, d_model)
output = self.dense(concat_attention) # (batch_size, seq_len_q, d_model)
return output, attention_weights
def point_wise_feed_forward_network(d_model, dff):
return tf.keras.Sequential([
tf.keras.layers.Dense(dff, activation='relu'), # (batch_size, seq_len, dff)
tf.keras.layers.Dense(d_model) # (batch_size, seq_len, d_model)
])
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
attn_output, _ = self.mha(x, x, x, mask) # (batch_size, input_seq_len, d_model)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(x + attn_output) # (batch_size, input_seq_len, d_model)
ffn_output = self.ffn(out1) # (batch_size, input_seq_len, d_model)
ffn_output = self.dropout2(ffn_output, training=training)
out2 = self.layernorm2(out1 + ffn_output) # (batch_size, input_seq_len, d_model)
return out2
class Encoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size,
maximum_position_encoding, rate=0.1):
super(Encoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.embedding = tf.keras.layers.Dense(d_model)
self.pos_encoding = positional_encoding(maximum_position_encoding, self.d_model)
self.enc_layers = [ EncoderLayer(d_model, num_heads, dff, rate) for _ in range(num_layers) ]
self.dropout = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
seq_len = tf.shape(x)[1]
# adding embedding and position encoding.
x = self.embedding(x) # (batch_size, input_seq_len, d_model)
# print('------------------\n',seq_len)
# x=tf.tile(tf.expand_dims(x,2),self.d_model)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
# print(x.shape)
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x, training=training)
# print(x.shape)
# print(mask.shape)
for i in range(self.num_layers):
x = self.enc_layers[i](x, training, mask)
return x # (batch_size, input_seq_len, d_model)
class Transformer(tf.keras.Model):
def __init__(self, num_layers, d_model, num_heads, dff,
input_vocab_size, target_vocab_size, maximum_position_encoding, rate=0.1):
super(Transformer, self).__init__()
self.encoder = Encoder(num_layers, d_model, num_heads, dff, input_vocab_size, maximum_position_encoding, rate)
self.final_layer = tf.keras.layers.Dense(target_vocab_size)
def call(self, inp, training, enc_padding_mask):
enc_output = self.encoder(inp, training, enc_padding_mask) # (batch_size, inp_seq_len, d_model)
final_output = self.final_layer(enc_output) # (batch_size, inp_seq_len, target_vocab_size)
return final_output[:,-1,:]
def train_step(inp, tar):
enc_padding_mask = create_padding_mask(inp)
# enc_padding_mask = None
with tf.GradientTape() as tape:
predictions = transformer(inp, True, enc_padding_mask)
loss = loss_function(tar, predictions)
gradients = tape.gradient(loss, transformer.trainable_variables)
optimizer.apply_gradients(zip(gradients, transformer.trainable_variables))
train_loss(loss)
# In[2] 加载数据
data = pd.read_excel('data.xlsx').iloc[:10000,1:].values.astype(np.float32)
n_steps=100
m=1
input_data,output_data=data_split(data,n_steps,m)
# 数据划分 前70%作为训练集 后30%作为测试集
n=range(input_data.shape[0])
m1=int(0.7*input_data.shape[0])
train_data=input_data[n[0:m1],:]
train_label=output_data[n[0:m1]]
test_data=input_data[n[m1:],:]
test_label=output_data[n[m1:]]
# 归一化
# ss_X=MinMaxScaler().fit(train_data)
# ss_Y=MinMaxScaler().fit(train_label)
ss_X=StandardScaler().fit(train_data)
ss_Y=StandardScaler().fit(train_label)
train_data = ss_X.transform(train_data).reshape(train_data.shape[0],n_steps,-1)
test_data = ss_X.transform(test_data).reshape(test_data.shape[0],n_steps,-1)
train_label = ss_Y.transform(train_label).reshape(train_data.shape[0],-1)
test_label = ss_Y.transform(test_label).reshape(test_data.shape[0],-1)
# exit()
# In[]
EPOCHS = 100 #训练次数
BATCH_SIZE = 256 ## batchsize
VAL_BATCH_SIZE=64 # valid batchsize
num_layers = 1 ## encoder 层数
d_model = 16 # dmodel要是num_heads的整数倍
dff = 100 # 编码层中前向网络的节点数
num_heads = 4 #多头注意力的头数量
dropout_rate = 0.5 #dropout
input_en_vocab_size = train_data.shape[-1] #输入节点数
target_sp_vocab_size = train_label.shape[-1] #输出节点数
optimizer = tf.keras.optimizers.Adam(0.01, beta_1=0.9, beta_2=0.98, epsilon=1e-9)
loss_function = tf.keras.losses.MeanSquaredError()
train_loss = tf.keras.metrics.Mean(name='train_loss')
valid_loss = tf.keras.metrics.Mean(name='valid_loss')
transformer = Transformer(num_layers, d_model, num_heads, dff,
input_en_vocab_size, target_sp_vocab_size,
maximum_position_encoding=5000,
rate=dropout_rate)
checkpoint_path = "./checkpoints/"
ckpt = tf.train.Checkpoint(transformer=transformer, optimizer=optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=10)
# In[] 训练
train_again=False #为 False 的时候就直接加载训练好的模型进行测试
if train_again:
num_samples,num_valid_samples = train_data.shape[0],test_data.shape[0]
num_batches,num_valid_batches = int(num_samples/BATCH_SIZE),int(num_valid_samples/VAL_BATCH_SIZE)
trainloss,validloss=[],[]
for epoch_n in range(EPOCHS):
start_time = time.time()
indices = np.arange(num_samples)
np.random.shuffle(indices)
cost,cost2=0,0
for batch_n in range(num_batches):
rand_index = indices[BATCH_SIZE*batch_n:BATCH_SIZE*(batch_n+1)]
inp = train_data[rand_index]
tar = train_label[rand_index]
train_loss.reset_states()
inp_tf = tf.convert_to_tensor(inp, dtype=tf.float32)
tar_tf = tf.convert_to_tensor(tar, dtype=tf.float32)
train_step(inp_tf, tar_tf)
cost += train_loss.result().numpy()/num_batches
end1_time=time.time()
# # compute validationset loss
for batch_n in range(num_valid_batches):
inp = test_data[batch_n*VAL_BATCH_SIZE:(batch_n+1)*VAL_BATCH_SIZE]
tar = test_label[batch_n*VAL_BATCH_SIZE:(batch_n+1)*VAL_BATCH_SIZE]
valid_loss.reset_states()
inp_tf = tf.convert_to_tensor(inp, dtype=tf.float32)
tar_tf = tf.convert_to_tensor(tar, dtype=tf.float32)
enc_padding_mask= create_padding_mask(inp_tf)
predictions = transformer(inp_tf, False, enc_padding_mask)
loss = loss_function(tar_tf, predictions)
valid_loss(loss)
cost2 += valid_loss.result().numpy() / num_valid_batches
end2_time = time.time()
if (epoch_n + 1) % 5 == 0:
ckpt_save_path = ckpt_manager.save()
print(epoch_n + 1,'train time:%.2f s,valid time:%.2f s,train loss:%.5f, valid loss:%.5f.'%(end1_time-start_time,end2_time-end1_time,cost,cost2))
trainloss.append(cost)
validloss.append(cost2)
plt.figure
plt.plot(trainloss,label='train_loss')
plt.plot(validloss,label='valid_loss')
plt.legend()
plt.ylabel('MSE')
plt.xlabel('Epoch')
plt.title('loss curve')
plt.savefig('model/transformer loss curve.jpg')
else:
# 加载最后一个模型
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
print ('Latest checkpoint restored!!')
else:
ckpt.restore('checkpoints/ckpt-20')
#ckpt.restore('./checkpoints/ckpt-16')
# In[] 测试
pred=np.zeros((0,test_label.shape[1]))
batchsize=64#
n_samples=test_data.shape[0]
n_baches=np.ceil(n_samples/batchsize)
for i in range(int(n_baches)):
start = i*batchsize
end = min( (i+1)*batchsize,n_samples)
inp_tf = tf.convert_to_tensor(test_data[start:end,:,:], dtype=tf.float32)
enc_padding_mask = create_padding_mask(inp_tf)
predictions = transformer(inp_tf, False, enc_padding_mask)
pred=np.vstack([pred,predictions.numpy()])
predict = ss_Y.inverse_transform(pred)
truth = ss_Y.inverse_transform(test_label)
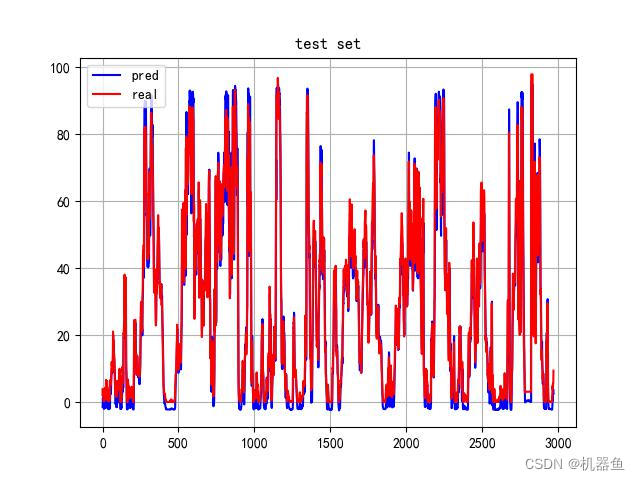
plt.figure()
plt.plot(predict[:,-1],c="b",label='pred')
plt.plot(truth[:,-1],c="r",label='real')
plt.grid()
plt.legend()
plt.title('test set')
plt.savefig('result/transformer_result.jpg')
plt.show()
np.savez('result/transformer.npz',true=truth,pred=predict)
# In[]计算各种指标
test_label = truth.reshape(-1, )
test_pred = predict.reshape(-1, )
result(test_label,test_pred,'transformer')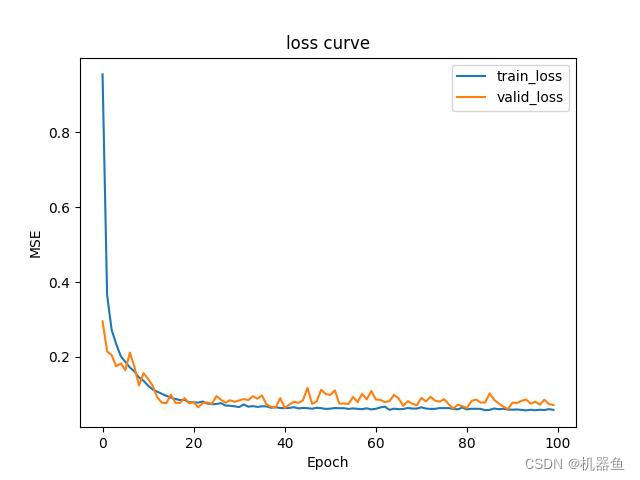
3 结语
获取更多内容请点击【专栏】,您的点赞与收藏是我持续更新【Python神经网络1000个案例分析】的动力。



















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











