






conformal tights 是一个python包
特征:
sklearn元估计器:向任何scikit-learn回归器添加分位数和区间的共形预测
darts预测:向任何scikit-learn回归器添加共形校准的概率预测
保形校准:准确的分位数和可靠的覆盖的区间
相干分位数:分位数单调增加而不是相互交叉
紧密分位数:选择提供所需覆盖范围的最低分散度
数据高效:仅需要少量校准示例即可拟合
pandas支持:可选择预测Dataframe并接收dataframe输出
给定置信水平,可以通过统计方法获得置信区间。
置信区间是一个范围,用于估计一个参数(如平均值、比例等)的可能性。这个范围是基于样本数据计算得出的,并且以一定的置信水平包含总体参数的真实值。
一般步骤
1、收集样本数据:从总体中随机抽取一个样本
2、计算样本统计量:根据样本数据计算所需的统计量,例如样本均值、样本比例等
3、给定置水平:选择一个置信水平,通常为95%或99%
4、查找临界值:根据所选的置信水平和统计量的分布,查找相应的临界值,这些临界值决定了置信区间的宽度。
5、计算标准误差:计算统计量的标准误差,反映了样本估计的精确度
6、构建置信区间:使用临界值和标准误差,更具公式构建置信区间
统计量
z
标准误差
Z是分布的临界值,这些临界值可以从统计表中查找。
置信区间的宽度受置信水平和样本大小的影响,更高的置信水平或更小的样本会导致更宽的置信区间。
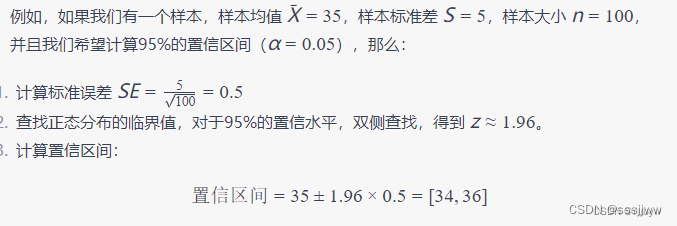
预测分位数
conformal tights导出一个称为元估计器ConformalCoherenrQuantileRegressor,可以使用它来为任何scikit-learn回归器配备predict_quantiles预测共形校准分位数的方法。
conformal prediction 是一种统计方法,用于生成预测区间,这些区间具有固定的覆盖率,这意味着预测区间有很高的概率包含未来的观测值。这种方法不仅适用于传统的点预测,还可以用于预测数据的分位数。
conformal tight prediction 是conformal prediction的一种变体,特别适合用于分位数预测,原理:对与给定的数据集,可以使用非参数方法来预估一个分位数,然后通过计算这个分位数的置信区间来得到一个预测区间。
关键步骤:
1、非参数分位数估计:首先,使用非参数方法(如核密度估计)来估计数据集的特定分位数
2、计算校正因子:为了确保预测区间的固定覆盖率,需要计算一个校正因子。这个因子是基于数据集的规模和分位数的估计值来计算的。
3、构造预测区间:使用校正因子来构造一个预测区间,这个区间以给定的置信水平包含未来观测值的真实分位数。
获取数据:
X, y = fetch_openml("ames_housing", version=1, return_X_y=True, as_frame=True, parser="auto")从OPENML数据库中下载数据集,OPENML是一个在线服务,提供了大量的数据集,共数据科学家和机器学习研究人员使用。
ames_housing:数据集的名称,是一个关于房价的中等规模数据集,常用于回归任务
version=1:数据集的版本号,OPENML中的数据集可能会随着时间的推移而更新
创建回归器,在训练集上拟合,然后基于测试集预测
# Create a regressor, equip it with conformal prediction, and fit on the train set
my_regressor = XGBRegressor(objective="reg:absoluteerror")
conformal_predictor = ConformalCoherentQuantileRegressor(estimator=my_regressor)
conformal_predictor.fit(X_train, y_train)
# Predict with the underlying regressor
ŷ_test = conformal_predictor.predict(X_test)使用一致性预测器预测分位数
ŷ_test_quantiles = conformal_predictor.predict_quantiles(
X_test, quantiles=(0.025, 0.05, 0.1, 0.9, 0.95, 0.975)
)
print(ŷ_test_quantiles)使用一致性预测器来预测测试集的多个分位数,quantiles参数指定了一组分位数,分别是0.025(2.5%)、0.05(5%)、0.1(10%)、0.9(90%)、0.95(95%)和0.975(97.5%)。这些分位数对应于预测分布的不同位置。
原理:
1、模型训练:需要一个训练好的预测模型,这个模型能够基于输入特征预测输出值
2、计算校准分数:对于每个测试样本,一致性预测方法会计算一个校准分数,这个分数反映了模型预测的不确定性。校准分数通常是基于模型预测的误差来计算的。
3、构建预测区间:对于给定的置信水平(例如95%),预测区间是通过将校准根数排序并选择合适的百分位点来构建的。例如,对于95%的置信水平,你会选择第2.5%和第97.5%的校准分数,这样构建的区间将有95%的把我包含未来的观测值。
4、分位数预测:quantiles参数指定了一组分位数,这意味着方法将计算这些分位数的预测值,这些分位数预测将给出不同置信水平下的预测区间。
返回的部分结果:
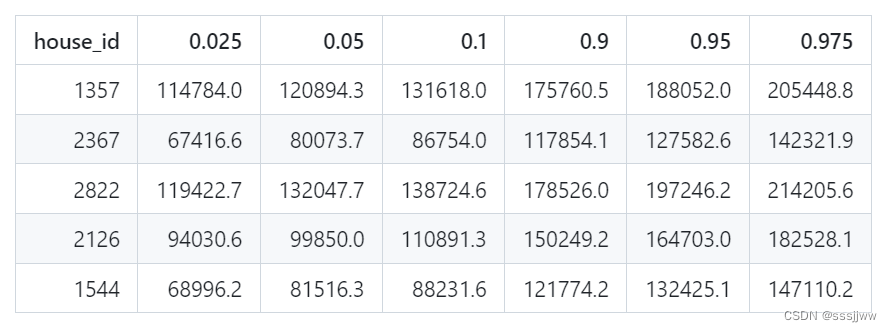
可视化测试集上的预测分位数:
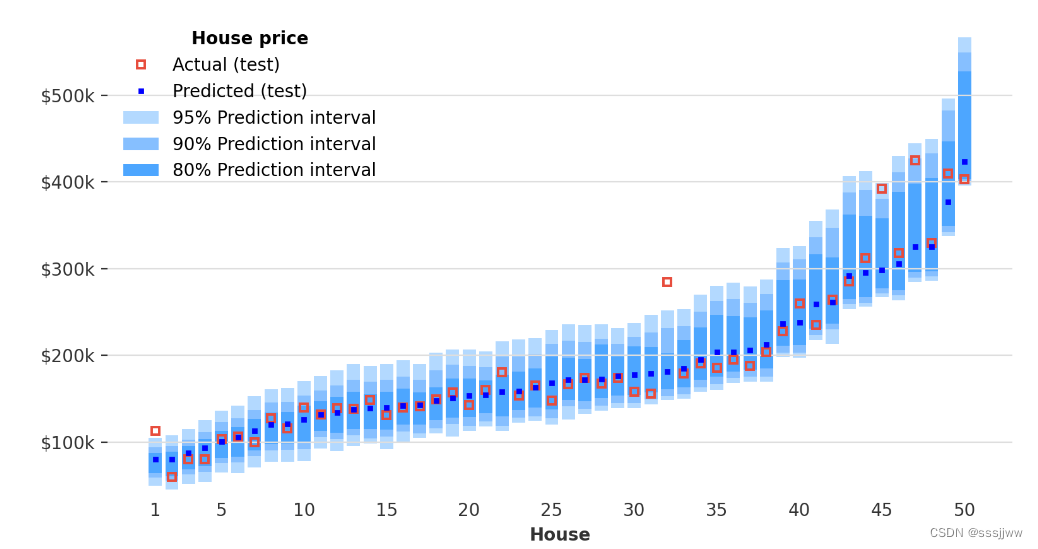
预测间隔
除了分位数预测外,还可以用predict_interval预测共形校准的预测区间,与分位数相比,这些侧重于可靠的覆盖范围而不是分位数精度
ŷ_test_interval = conformal_predictor.predict_interval(X_test, coverage=0.95)使用一致性预测器来预测测试集上每个样本的房价区间,并且制定了期望的覆盖率(coverage为0.95)
conformal_predictor.predict_interval方法计算了对于给定测试数据集X_test中每个样本的95%预测区间。这个区间是一个范围,表达了预测值的不确定性,95%的覆盖率意味着我们期望95%的实际观测值会落在这个区间内。
计算出来的预测区间被存储在ŷ_test_interval变量中,这个变量通常是一个二维的dataframe或numpy数组,其中每一行对应于x_test中内的一个样本,每一列对应于区间的下界和上界。
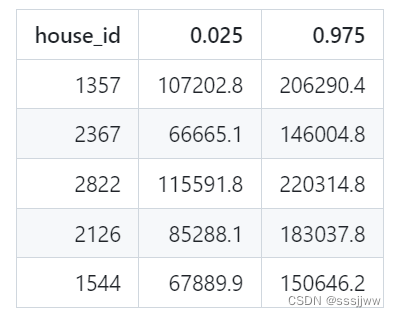
coverage = ((ŷ_test_interval.iloc[:, 0] <= y_test) & (y_test <= ŷ_test_interval.iloc[:, 1])).mean()ŷ_test_interval.iloc[:, 0]:预测区间的下界
ŷ_test_interval.iloc[:, 1]:预测区间的上界
y_test:测试集的实际目标
&用来判断测试集的实际目标值是否同时大于等于预测区间的下界且小于等于预测区间的上界
mean():计算平均值的方法,计算所有测试样本中落在预测区间内的比例。
预测时间序列
conformal tights还导出一个名为darts预测器,dartsforecaster它使用ConformalCoherentQuantileRegressor来进行共形校准的概率时间序列预测。
ConformalCoherentQuantileRegressor是Darts库中的一个类,用于创建一个一致性校准分位数回归器,这个类的功能主要与概率预测和时间序列分析有关,特别是在需要预测不确定性的情况下。
ConformalCoherentQuantileRegressor的一些主要功能:
1、分位数预测:能够预测多个分位数,而不仅仅是单一的点估计。意味着它可以提供关于预测分布的更全面的信息,包括预测的置信区间。
2、一致性校准:这个回归器使用一致性校准技术来确保预测区间的大小是准确的。换句话说,如果模型声称有95%的置信区间,那么实际应用中,大约95%的观测值应该落在这个区间内。
3、时间序列预测:ConformalCoherentQuantileRegressor专门设计用于处理时间序列数据,它可以捕获数据中的时间依赖性。
4、处理协变量:这个回归器可以处理未来协变量,这意味着它可以利用未来的非目标变量来提高预测的准确性。
5、概率预测:除了提供点估计,ConformalCoherentQuantileRegressor还能够生成概率分布预测,有助于用户理解预测的不确定性和风险。
6、模型集成:在Darts库中,ConformalCoherentQuantileRegressor可以与其他模型集成,允许用户穿件更复杂的预测模型。
# 参数指定了回归的目标函数,即最小化预测值与真实值之间的绝对误差
xgb_regressor = XGBRegressor(objective="reg:absoluteerror")
# 创建一个一致性预测器,核心:对于任何新的输入,它都会生成一个预测区间,这个预测区间以一定的置信水平包含未来观测值的真实值
conformal_predictor = ConformalCoherentQuantileRegressor(estimator=xgb_regressor)
# 创建时间序预测器,以一致性预测器作为模型
forecaster = DartsForecaster(
model=conformal_predictor,
lags=1 * 24,
lags_future_covariates=[0],
categorical_future_covariates=X_categoricals,
)
forecaster.fit(y_train, future_covariates=x_train)
quantiles = (0.025, 0.05, 0.1, 0.25, 0.5, 0.75, 0.9, 0.95, 0.975)
forecast = forecaster.predict(
n=5 * 24, future_covariates=x_test, num_samples=500, quantiles=quantiles
)model:用于预测时间序列的模型,conformal——predictor是一个一致性预测器,它使用XGBoost回归器作为基础模型,一致性预测器提供一种生成预测区间的方法,这些区间以一定的置信水平包含未来的观测值。
lags:滞后参数指定模型在预测时将使用多少个历史目标值作为特征。
lags_future_covariates:未来协变量的滞后列表,用于指定模型在预测时使用多少个未来协变量的历史值作为特征,[0]表示模型将只使用当前时间点的协变量,而不使用任何历史值。
categorical_future_covariates:是一个包含列名的列表,指定了哪些列是分类协变量。这些列被转换为pd.categorical类型,这通常在进行统一建模时处理分类数据的一种方式。
X.pd_dataframe()的输出结果为:
接上
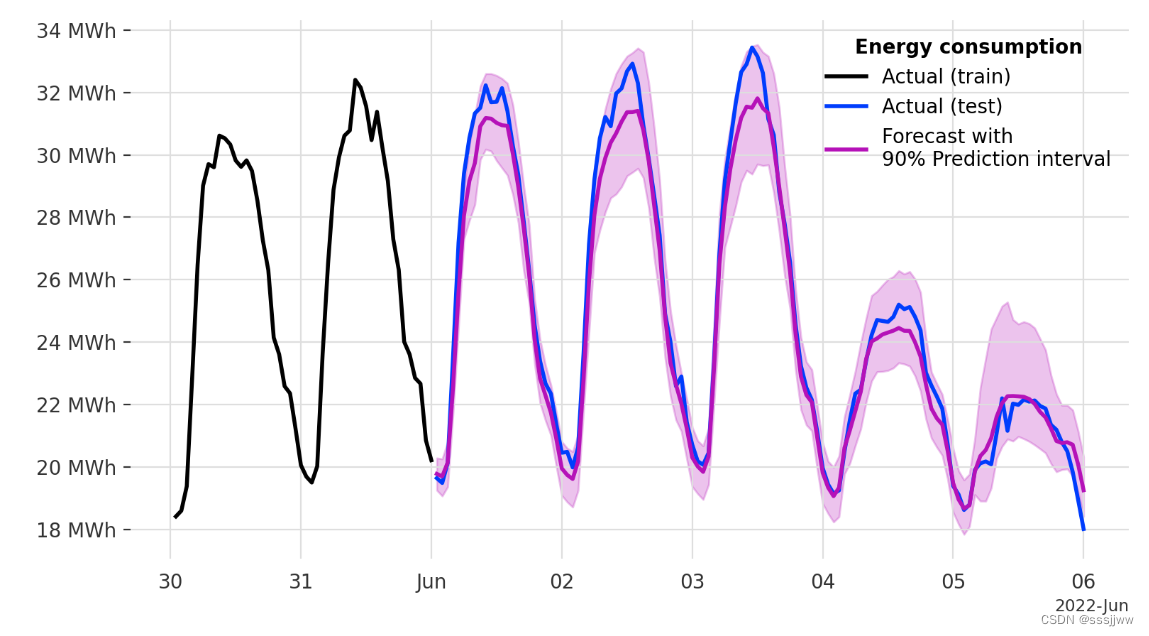
在测试集上可视化预测及其预测区间:
EnCQR
B:采用集成学习的个数
alpha:置信水平
quantiles:需要预测的分位数
采用的回归模型:LSTM
参数:L2正则化权重,批处理大小、lstm每层神经元个数、lstm的层数
P中存放上述配置
P = {'B':B, 'alpha':alpha, 'quantiles':quantiles, 'model_type':model_type,
'regression':regression,'l2':l2_lambda, 'batch_size':batch_size,
'units':units,'n_layers':n_layers }train_df:dataframe格式数据,(8760, 6)
val_df:同上
test_df:同上
数据预处理,对时间序列数据进行窗口化处理,将时间序列数据划分为固定长度的连续窗口,用于模型训练和预测。
train_data, val_x, val_y, test_x, test_y, Scaler = data_preprocessing.data_windowing(df=train_df, val_data=val_df, test_data=test_df, B=3, time_steps_in=168, time_steps_out=24, label_columns=['MWH'])train_data:list格式的数据,里面有3组数据,是按照集成学习的个数设置的

每个list中,0是指输入的,112组数据,每组数据有168个时间点组成(一个礼拜),每个时间点有6个特征;1是指输出的,112组数据,每组数据输出24个值,代表下一天的光伏发电量。
PI, conf_PI = EnCQR(train_data, val_x, val_y, test_x, test_y, P)生成的模型需要对train_data中的数据进行预测
pred = f_hat_b.transform(train_data[indx_LOO[i]][0])train_data中的一组数据作为输入,格式为(112, 168, 6)
pred的格式为(112, 24, 3)
然后将pred中每项的三个数中的最大值放入dct_hi,最小值放入dct_lo中
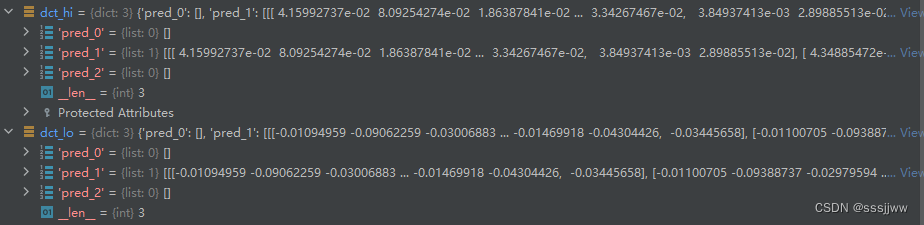
dct_hi与dct_lo的格式:
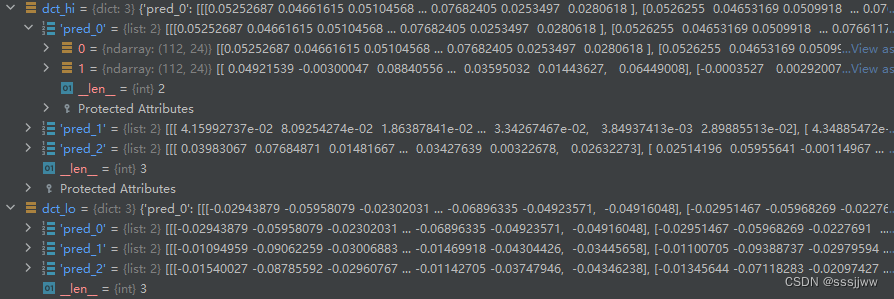
f_hat_b_agg_low与f_hat_b_agg_high的格式(112, 24, 3)
3指的是pred_1、pred_2、pred_3,pred_1中有2项,求平均后填入
for b in range(P['B']):
e_low, e_high = utils.asym_nonconformity(label=train_data[b][1],
low=f_hat_b_agg_low[:,:,b],
high=f_hat_b_agg_high[:,:,b])将train_data、f_hat_b_agg_low、f_hat_b_agg_high计算非一致性残差,这种类型的残差计算通常用于构建预测区间,尤其是在时间序列预测中
计算残差的方式:
1、对于每个时间步长t,计算实际值label[t]与模型预测的高端值high[t]之间的差异,即residual_high[t] = label[t] - high[t]2、同样,计算实际值
label[t]与模型预测的低端值low[t]之间的差异,即residual_low[t] = low[t] - label[t]
3、返回这两个残差数组:e_low和e_high (就是差值)
这些残差被用来校准预测区间,确保他们具有正确的置信度水平,校准后的预测区间通常包括实际值在预测区间内的概率。
f_hat_t_batch格式:(357, 24, 3, 3)最后一个3对应的是几种模型
f_hat_t_batch[:,:,:,b] = model_b.transform(test_x)test_x的格式(357, 168, 6)
PI:格式(357, 24, 3),也就是f_hat_t_batch最后一个3中的数据求平均
获得预测区间后,需要对预测区间进行校准
conf_PI格式:(357, 24, 3)
将原始预测区间的中心值幅值到conf_PI中,作为校准后预测区间的中心
e_quantile_lo = np.quantile(epsilon_low, 1-P['alpha']/2) # 计算残差的分位数,用于确定预测区间的外界
e_quantile_hi = np.quantile(epsilon_hi, 1-P['alpha']/2)
conf_PI[i,:,0] = PI[i,:,0] - e_quantile_lo # 根据计算出的分位数,更新conf_PI的下界和上界,创建校准后的预测区间
conf_PI[i,:,2] = PI[i,:,2] + e_quantile_hi对357项中的每一项进行操作
个人理解:
有一个数据集,将数据集分成训练集、验证集、测试集
根据需要用的集成模型的个数,假设有3个底层的集成模型,将训练集的数据分成三等分。
构建底层的集成模型,假设底层3个回归模型都是lstm,那么就有3个lstm模型,基于三个训练集,一对一训练lstm模型,同时对另外两个训练集进行验证。所以pred_1、pred_2、pred_3中每个都有两项,由另外两个模型得到的。
LSTM模型是直接输出对应的分位数预测值,分位数分别是0.05, 0.5, 0.95,然后取得对应分位数的预测值。将预测的0.05分位数的预测值放于dct_lo中,将预测的0.95分位数对应的预测值放于dct_hi中。
然后每个训练集都有另外两个模型对其进行验证获得的预测值,对其相应点位进行求平均,可以获得对应点位的下界和上界的平均值。3个训练集每个都有一个上界和下界的预测值
计算非一致性残差,e_low 和 e_high 112*24*3=8064
采用三个lstm模型,分别对测试集进行预测
求平均后可以获得预测区间
基于残差,计算残差的分位数求校正各点处的上下界
区间预测的损失函数
分位数损失函数主要用于分位数回归,允许我们预测一个响应变量的条件分位数。在光伏发电预测的情况下,使用分位数损失函数可以帮我们预测发电量的特定分位数,从而得到一个区间。
分位数回归:是估计一组回归变量X与被解释变量Y的分位数之间线性关系的建模方法。OLS回归估计的计算是基于最小化残差平方,分位数回归估计量的计算也是基于一种非对称形式的绝对值残差最小化。其中中位数回归应用的是最小绝对值离差估计。
分位数回归的优点
①能够更加全面的描述被解释变量条件分布的全貌,而不是仅仅分析被解释变量的条件期望(均值),也可以分析变量如何影响被解释变量的中位数、分位数等。不同分位数下的回归估计量常常不同,即解释变量对不同水平被解释变量的影响不同。
②中位数回归估计方法与最小二乘法相比,估计结果对离群值则表现的更加稳健,而且,分位数回归对误差项并不要求很强的假设条件,因此对于非正态分布而言,分位数回归系数估计量则更加稳健。
与传统的回归方法不同,分位数回归侧重于估计响应变量的条件量值,而不是条件均值。
分位数回归的数学原理
分位数,即分位点,是指将一个随机变量的概率分布范围分为几个等份的数值点,常用的有中位数(即二分位数)、四分位数(第25、50和75个百分位)、百分位数等。
分位数回归既能研究在不同分位点处自变量X对于因变量Y的影响变化趋势,也能研究在不同分位点处的哪些自变量X是主要影响因素。原理是将数据按因变量进行拆分成多个分位数点,研究不同分位点情况下时的回归印象关系情况。
本质上,分位数回归就是一个加权最小二乘法,给不同的y值(大于分位点和小于分位点的y)不同的权重,比如现在我们有一个数据集是1到10各整数,我们希望求0.7分位数,假设这个0.7分位数是q,然后所有大于q的数都被赋上权重0.7,小于q的赋予权重0.3。
一般的回顾地方法是最小二乘法,即最小化误差的平方和:其中,一个是真实值,一个是预测值,而分位数的目标是最小化加权的误差绝对值和:提个是给定的分位数,一个是真实值。
对于第个分位数(
),模型的形式可以表示为:
这里,是在给定X的条件下y的第
个分位数,
是分位数回归系数,它们随
的不同而变化。分位数回归的目标函数是:
常用的分位数回归模型
1、线性分位数回归
优点:
简单易理解,可以直接通过最小化分位数损失函数来求解
计算效率高,适用于小到中等规模的数据集
模型的系数容易理解,可以直接得到对应分位数的线性关系
缺点:
对于非线性关系,模型的表现可能不佳
对于异常值敏感,尤其是在目标分布的尾部
2、随机森林分位数回归
优点:
能够自然地处理非线性和复杂的数据结构
对异常值具有较好的鲁棒性
可以自动进行特征选择,减少过拟合的风险
缺点:
相对于线性模型,随机森林的结果更难解释
训练和预测的时间较长,尤其是在大数据集上
3、支持向量机分位数回归
优点:
通过使用不同的核函数,SVR可以很好地处理非线性问题
模型具有较好的泛化能力,尤其是在合适的正则化下
缺点:
参数调优对模型性能有较大的影响,但调优过程可能既复杂又耗时
计算成本高,尤其是在处理大规模数据集时
4、深度学习分位数回归
优点:
非常灵活,能够通过设计网络架构来捕捉复杂的非线性关系和交互效应
对大规模数据集有良好的适应性
缺点:
需要大量的数据来训练模型,以避免过拟合
模型解释性差,很难理解模型是如何做出预测的
训练时间长,对计算资源的需求高
5、量子神经网络分位数回归
优点:
在处理特定类型的问题时,可能提供超越传统机器学习技术的能力
长期看来,有潜力处理复杂度极高的问题
缺点:
目前仍处于研究和开发的早期阶段,实际应用有限
需要特殊的硬件和软件支持,可接触性有限















 1384
1384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









