







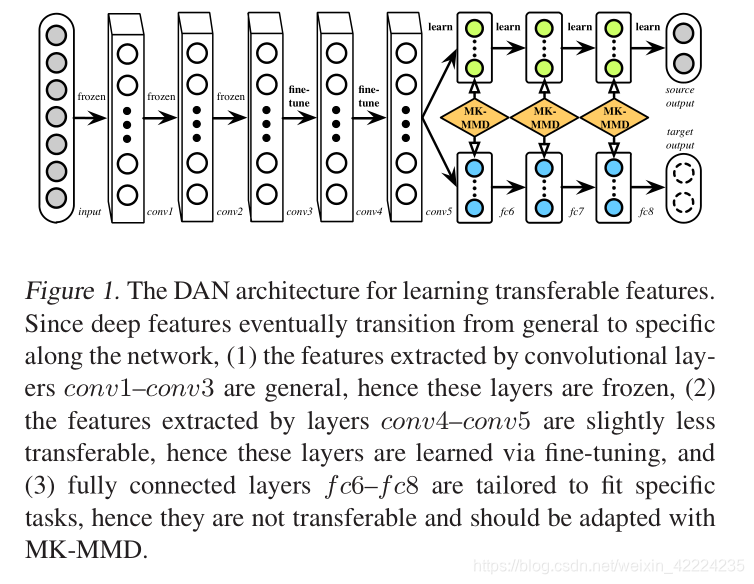
 该文章探讨了在深度学习中,由于特征从通用到特定的转变,导致高层特征的迁移性显著下降的问题。文章提出了多层适应网络(DAN)来解决这个问题,通过优化小批量随机梯度下降(SGD)过程中的成对相似性计算,以改善深度网络的训练效果。DAN网络包括固定的前几层,经过微调的中间层和学习的顶层。此外,它利用多核最大均方差异(MK-MMD)来最大化双样本测试功率并减少II类错误。文章介绍了参数更新和核参数β的学习,并强调了DAN的主要创新点:多层适配和MK-MMD的使用。
该文章探讨了在深度学习中,由于特征从通用到特定的转变,导致高层特征的迁移性显著下降的问题。文章提出了多层适应网络(DAN)来解决这个问题,通过优化小批量随机梯度下降(SGD)过程中的成对相似性计算,以改善深度网络的训练效果。DAN网络包括固定的前几层,经过微调的中间层和学习的顶层。此外,它利用多核最大均方差异(MK-MMD)来最大化双样本测试功率并减少II类错误。文章介绍了参数更新和核参数β的学习,并强调了DAN的主要创新点:多层适配和MK-MMD的使用。
经典文章DAN
problem:
1、as deep features eventually transition from general to specific along the network, the feature transferability drops significantly in higher layers with increasing domain discrepancy.特征的迁移性在高层明显下降,并增加域差异。
2、Moreover, the summation over pairwise similarities between data points makes mini-batch stochastic gradient descent(SGD) more difficult, whereas mini-batch SGD is crucial to the training effectiveness of deep networks.此外,对数据点之间成对相似性的求和使得小批量随机梯度下降(SGD)更加困难,而小批量SGD对深度网络的训练有效性至关重要。
总函数: 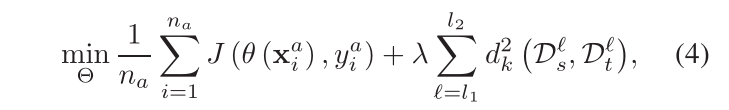
上面的公式中,J函数是一组有标签样本的损失,dk2是第l层的mk-mmd距离。
网络应该是1-8层(1-3层是固定的,4-5是fine-tune,6-8层是learn&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1125
1125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









