






Abstract
建筑物立面分析长期以来都是计算机视觉中三维街景重建的关键组成部分。
①这篇文章提出了采用基于深度学习的方法来对建筑物立面进行语义信息分类。现实中的建筑物立面具有对称的特点,基于这一观察,②文章采用了对称正则化的方法来训练神经网络。 ③文章还提出了采用RPN所生成的边界框来细化分割结果的方法。 实验过程中,作者采用新颖的损失函数来训练FCN-8s网络,验证了其方法是state-of-the-art。
Introduction
成功的建筑立面解析不仅可以更有效地存储建筑信息,而且可以基于规则对信息进行记录。这些规则可以进一步用于重建不同风格的建筑立面,这在游戏引擎中非常有用。其次,精确的建筑物立面分析可以应用于街道地图重建和智能驾驶。它可以让汽车更好的去理解周围的环境,以提高智能驾驶的安全性。该论文的任务目标是在语义上识别每个像素的类别。语义范畴主要包括建筑外立面,如窗、墙、阳台等。
第二段主要介绍建筑物外表面的语义分割的困难性。
第三段应用了三篇论文,分别介绍了:大部分的语义分割都是基于逐像素级或超像素级操作方法,现今的方法试图学习不同抽象层的标签信息,以及动态规划的方法。
第四段主要介绍深度学习的方法在计算机视觉图像处理领域的运用。
后面两段就再次介绍论文中即将采用的方法了。最后一段还介绍了下训练用的数据集。
Related Work
本文提出了一种新的深度卷积神经网络对称损失算法,并在两个facade分析数据集上验证了该算法的有效性。
Approach
Network Structure
第一段就是介绍Fully Convolutional Networks for Semantic Segmentation的网络结构。
第二段介绍FCN-8s的卷积层,第三段主要介绍FCN-8s的反卷积层。
A Symmetric Constraint for Man-Made Architectures
第一部分介绍语义分割的损失函数:
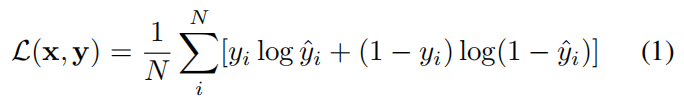
x
x
x代表输入的图片数组,
y
y
y为对应的语义标签,
N
N
N代表的是图片的像素值。
y
i
y_{i}
yi代表真实的语义标签。
y
^
i
\hat{y}_{i}
y^i代表生成的于一标签即
y
^
=
f
(
x
)
\hat{y}=f(x)
y^=f(x)。
尽管深度卷积神经网络在一般图像分割问题上表现出了强大的能力,但这种损失函数对神经网络没有任何约束或指导。我们希望神经网络能够在建筑立面中利用人造规则(也就是对称性),因此我们提出以下对称损失项。
对于我们想要施加对称约束的每个类别,让
p
p
p表示属于这个类别的每个对象。在建筑立面的例子中,同一类的两个不同对象没有交集,将对象划分为一个集合P,其中没有两个元素相交是可行的。(这句我的理解是该语义分割采用实力分割的方法,所分割出来的同类对象都有其相应的标号,不同编号的像素间是不相交的)。对于每个目标
p
p
p,其相应的对称损失为:


x
c
j
x_{cj}
xcj代表目标
p
p
p第
j
j
j个垂直线段的中心,用于处理水平对成。
N
j
N_{j}
Nj代表垂直线段上的像素。
同理,
y
c
i
y_{ci}
yci代表目标
p
p
p第
j
j
j个水平线段的中心,用于处理垂直方向上的对称。
N
i
N_{i}
Ni代表水平方向的像素。
note: 均方误差是反应估计量与被估计量之间差异程度的一种度量。(相当于期望)
最终的损失函数为:
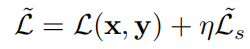
其中,0<
η
\eta
η<1论文将这个损失函数称为对称损失。
Boosting the Performance Using Object Detection
窗、门、阳台是立面分析中最重要的结构。这些大部分都是方形的,我们可以使用这些先验信息来提高我们立面分析的可视化效果。目标检测所生成的边框用于展示特定目标的位置,如果预测框额能够很好的框选出目标的位置,那结果将得到很大的改善。论文采用Faster R-CNN来生成窗户目标的边框。

第二,第三段主要介绍的是Faster R-CNN。
为了在每个可能的位置上选择一个边框,我们只需采用NMS (Non-Maximum Suppression)的两个步骤。首先,设置阈值为0.7的NMS,以获得Top-M可能窗口(在我们的实验中,M为100),然后设置阈值为0.01,以抑制重叠,以采取最终建议。采用5折交叉验证从所有图像生成建议。(五折交叉验证: 把数据平均分成5等份,每次实验拿一份做测试,其余用做训练。 实验5次求平均值。)Figure 4 为其输出的效果图。
Faster R-CNN:
我们的计算机通过框的x轴,y轴坐标,框的高和宽四个参数就可以确定框选的目标的位置。
Faster R-CNN是一种双阶段的目标检测算法。在处理图像之前,Faster R-CNN会将图片的短边等比例Resize到600的大小,由于是等比例缩放,所以我们的图片并不会出现失真的情况。首先我们的网络会被传入到backbone主干提取网络中。特征提取网络有很多,如:VGG16,ResNet等。 提取出来的特征被存放到共享特征层Feature Map中,共享特征层中特征的shape为50×38×256。共享特征层相当于把我们输入进来的图片划分成50×38的网格。每个网格上有9个先验框,其为后续做铺垫。
如图,Feature Map左边的路径输入建议框网络RPN,我们的左边路线先经过两个3×3的卷积,再分成两段经过两段1×1的卷积。两个1×1的卷积的结果就是用来判断我们的先验框内部是否真实的包含物体,然后对先验框进行调整,调整成我们的建议框 。第一段1×1卷积的输出为18,代表9×2的卷积,其作用是判断先验框的内部是否真实地包含物体,其中的2一个是代表背景的概率,一个代表内部有物体的概率;第二段1×1卷积的输出为36,代表9×4的卷积,其中4指先验框的调整参数,因为我们刚开始就介绍了确定一个检测框需要x,y,h,w四个参数,所以9×4的卷积就是用于调整四个参数来调节先验框。经过两次卷积之后,我们就可以得到建议框proposal,这边的建议框是对画面中的物体进行粗略的筛选,并非完全准确,后面还需要进一步调整。
建议框proposal会和共享特征层Feature Map结合传到ROIPooling层中,由于我们获取的建议框的大小是不一样的,利用建议框对共享特征层进行截取的时候,所获得的局部特征层是不一样的(截取图片的大小是不一样的),ROIPooing会对这些局部特征层进行分区域的池化(需要把他们resize成同样的大小)。
然后,对于从ROIPooling所获得的所有局部特征层,我们需要对其进行分类预测和回归预测,回归预测的结果会直接对建议框进行调整获得最终的预测框;然后我们分类预测的会去判断我们预测内部是否有物体和判断物体的种类,最终确定我们的预测框。

为了将检测结果应用于分割,我们首先将边界框转换到整个图像的得分图中。设
s
=
{
s
i
j
k
}
H
×
W
×
K
s=\lbrace s_{ijk} \rbrace_{H×W×K}
s={sijk}H×W×K表示预测图像的得分图,
s
s
s是大小为H×H×K的矩阵,
H
H
H和
W
W
W代表图片的高和宽,
K
K
K代表的是语义类别的数量,
s
i
j
k
s_{ijk}
sijk代表属于类别
k
k
k的像素概率。在立面分析的例子当中,以下类别适用于探测器为它们生成边界框:{窗户、门、阳台、烟囱、商店}。
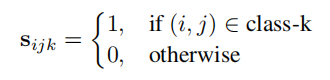
其中
s
f
c
n
s_{fcn}
sfcn表示由FCN生成的分数图。最后,最终的得分将是两者的线性组合:
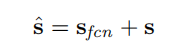
每个像素(i、j)的预测标签将为:
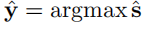















 800
800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









