










说明
本次主要说的是网络流量日志的自定义采集,是大数据学习的入门第一步。文章分为上下两部分,上部分为背景介绍,原理分析,设计实现三部分,上部分主要是以文字和原理为主。下半部分主要讲解实际部署,日志和事件采集的实现。
知识背景–Web访问日志
访问日志指用户访问网站时的所有访问、浏览、点击行为数据。比如点击了哪一个链接,打开了哪一个页面,采用了哪个搜索项、总体会话时间等。而所有这些信息都可通过网站日志保存下来。通过分析这些数据,可以获知许多对网站运营至关重要的信息。采集的数据越全面,分析就能越精准。
数据的生成渠道主要:
- web 服务器软件( httpd、 nginx、 tomcat) 自带的日志记录功能,如 Nginx
的 access.log 日志; - 自定义采集用户行为数据, 通过在页面嵌入自定义的 javascript 代码来获取用户的访问行为(比如鼠标悬停的位置,点击的页面组件等),然后通过 ajax请求到后台记录日志,这种方式所能采集的信息会更加全面。
- web 服务器软件( httpd、 nginx、 tomcat) 自带的日志记录功能,如 Nginx
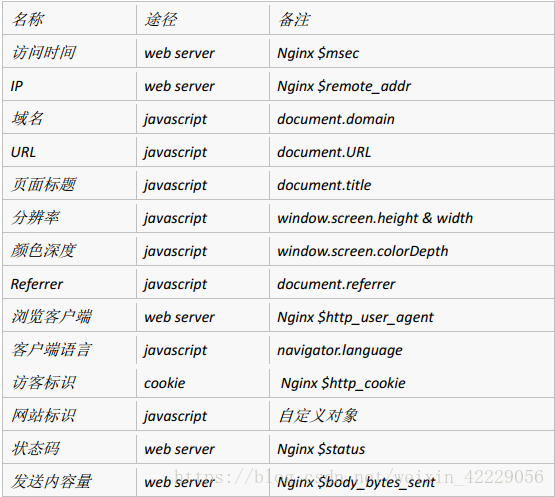
可以自定义采集的信息
- 系统特征: 比如所采用的操作系统、浏览器、域名和访问速度等。
- 访问特征: 包括停留时间、点击的 URL、所点击的“页面标签<\a>”及标签的
属性等。 - 来源特征: 包括来访 URL,来访 IP 等。
- 产品特征: 包括所访问的产品编号、产品类别、产品颜色、产品价格、产品
利润、产品数量和特价等级等。
以电商某东为例,其自定义采集的数据日志格式如下:

原理分析
基本原理:client访问的页面上增加埋点代码,在页面加载的时候执行。发出requset携带请求,使用图片标签包装数据,实现跨域异步请求,指定server接收数据,解析,存储数据,响应客户端(1*1b比例图片)。
原理图
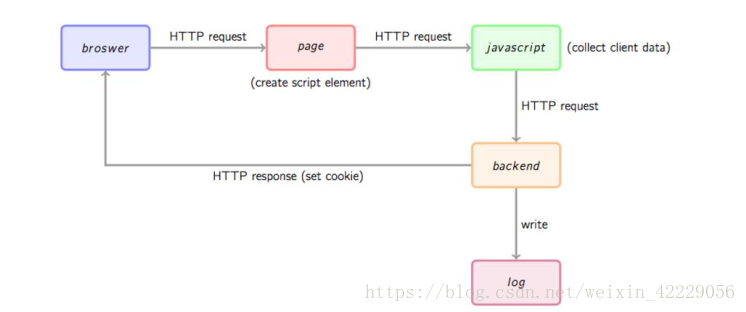
执行步骤
1. 用户的行为会触发浏览器对被统计页面的一个 http 请求, 比如打开某网页。
2.网页被打开,执行埋点 javascript 代码,创建一个ma.js请求,这个请求指向server中的ma.js代码块(分离埋点代码块,主要是为了解决两个服务之间的强度依赖关系,后端修改采集内容的时候,可以自行操作)。
3. ma.js被浏览器请求到并执行,这个js文件就数据收集脚本。
4. js请求会伪装成一个动态图片,将收集到的数据通过tttp参数的方式传递给端脚 本。
5. 后端脚本解析固定格式记录到访问日志,同时响应种给客户端一个用于追踪的ookie信息和1*1的图片。
埋点代码
在网页中预先加入小段 javascript 代码,这个代码片段一般会动态创建一个 script 标签,并将 src 属性指向一个单独的 js 文件,此时这个单独的 js 文件(图中绿色节点)会被浏览器请求到并执行,这个 js 往往就是真正的数据收集脚本。
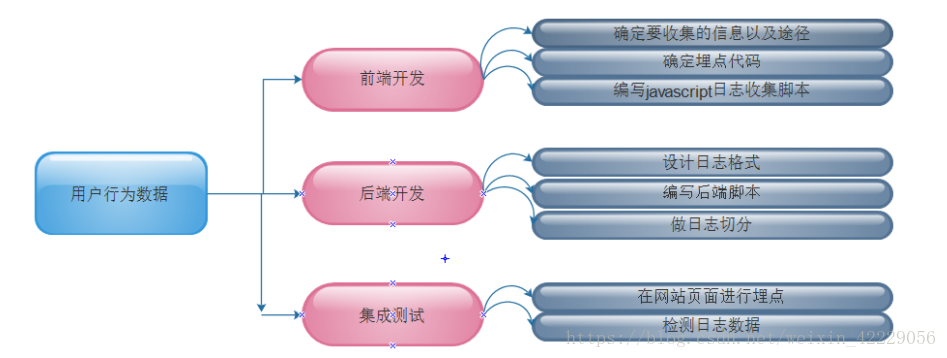
设计实现
- 根据原理分析并结合 Google Analytics, 想搭建一个自定义日志数据采集
系统, 要做以下几件事:
收集的信息














 841
841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









